发表于: 2017-12-05 21:13:40
1 843
今天完成的事情:
1.看了数据从七牛云迁移到阿里云,阿里云迁移到七牛云的API文档
使用前声明:
就是说,你需要向哪个API里面迁移,就要使用哪一家的数据迁移工具。
每个对象储存的开发文档里都有说明。
以阿里云为例:
OssImport工具可以将本地、其它云存储的数据迁移到OSS。-----------------从xxxxxx迁移到OSS里。
(1)从七牛云迁移到阿里云
1)架构:OssImport是基于 master-worker 的分布式架构
Job:用户通过提交的数据迁移任务,对用户来说一个任务对应一个配置文件job.cfg。
Task:Job按照数据大小和文件个数可以分成多个Task ,每个Task迁移部分文件。Job切分成Task的最小单位是文件,同一个文件不会切分到多个Task中。
2)部署方式,我们选用单机模式。
阿里有两种:单机和分布式两种模式。
选择的条件就是:传输文件小于30TB的时候就选择单机模式
单机模式:单机模式下Master、Worker、TaskTracker、Console四个模块统一打包成ossimport2.jar。
下载该 ossimport-2.2.4.zip,就可以拿到打包后的文件。
里面的所有文件中我们可能需要修改的有:两个配置文件conf/sys.properties、conf/local_job.cfg
事实上在看了注解以后,结合任务,我觉得也没什么需要修改的。
比如:sys.properties配置文件的配置:
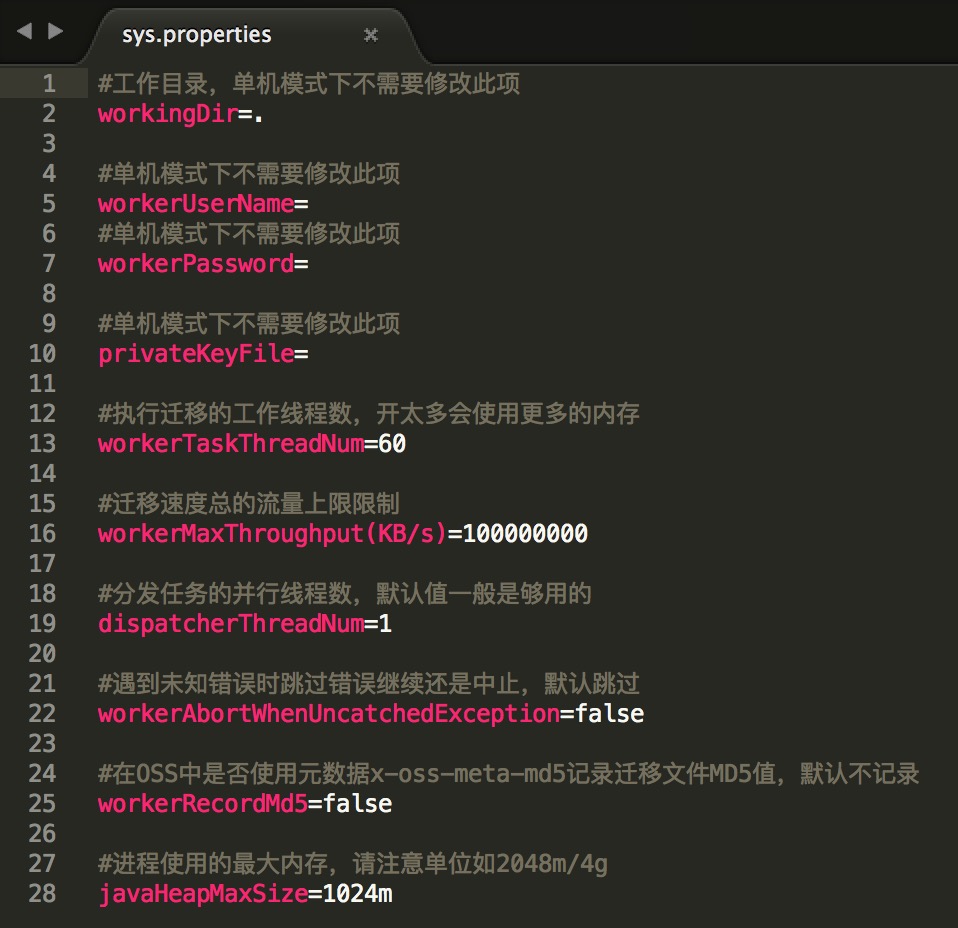
很喜欢这种配置文件,就是保证你在没看懂API以后,还可以很清楚的在打开配置文件以后还是可以很明白的。
不涉及群体,识字的斗酒可以看懂它的每个熟悉时配置什么的。
剩余就没什么了。对于初学者阿里建议使用一键导入。
3)一键导入步骤
- 1.执行一键导入,Window系统下在 cmd.exe 中执行 import.bat,Linux终端中执行 bash import.sh。
- 2.如果之前执行过程序,会提示有是否从上次的断点处继续执行,或者重新执行同步任务。对新的数据迁移任务,或者修改了同步的源端/目的端,请选择重新执行。
- 3.Windows下任务开始后,会打开一个新的cmd窗口执行同步任务并显示日志,旧窗口会每隔10秒打一次任务状态,数据迁移期间不要关闭两个窗口;Linux下服务在后台执行。
- 4.当 Job 完成后,如果发现有任务失败了,会提示是否重试,输入 y 重试,输入 n 则跳过退出。
- 5.如果上传失败,请打开文件master/jobs/local_test/failed_tasks/<tasktaskid>/audit.log查看,确定失败原因。
-
- 根据步骤执行就可以了,总的来说,向阿里云里面迁移数据还是不难的。
(2)从阿里云迁移到七牛云
七牛云的迁移工具是:qfetch
1)qfetch
qfetch是一款数据迁移工具,利用七牛提供的fetch功能抓取指定文件列表中的文件。在文件列表中,您只需要提供资源的外链地址和要保存的文件名就可以了。
使用该工具进行资源抓取时,您可以根据需要中断任务的执行,下次重新使用原命令执行时,会自动跳过已经抓取成功的资源。(这个功能挺不错的)
新名词:外链,字面意思:外部的链接。可以这样理解。
同理,下载qfetch v1.7文件。里面是三个操作系统的运行文件,根据自己的系统选择就行。
2)这个工具是一个命令行工具,需要设定相关参数。如下:
Usage of qfetch:
-ak="": qiniu access key
-sk="": qiniu secret key
-bucket="": qiniu bucket
-job="": job name to record the progress
-file="": resource list file to fetch
-worker=0: max goroutine in a worker group
-zone="nb": qiniu zone, nb or bc
和阿里的设置参数还是有相似点的。
其余含义可以看文档。zone:nb为华东
https://developer.qiniu.com/kodo/tools/1296/qfetch
3)file:resource list file to fetch(选择其中一种格式)
格式为:文件链接\t文件名
\t:tab分隔符
4)文件抓取命令:
qfetch -ak="x98pdzDw8dtwM-XnjCwlatqwjAeed3lwyjcNYqjv" -sk="OCCTbp-zhD8x_spN0tFx4WnMABHxggvveg9l9m07"
-bucket="image" -file=diff.txt -worker=300 -job="diff" | tee diff.log
5)还有个go语言编写的命令行工具qshell也可以,有时间可多做了解.
2.了解任务8
(1)首先学习RMI
RMI是Java的一组拥护开发分布式应用程序的API。RMI使用Java语言接口定义了远程对象,它集合了Java序列化和Java远程方法协议(Java Remote Method Protocol)。简单地说,这样使原先的程序在同一操作系统的方法调用,变成了不同操作系统之间程序的方法调用,由于J2EE是分布式程序平台,它以RMI机制实现程序组件在不同操作系统之间的通信。比如,一个EJB可以通过RMI调用Web上另一台机器上的EJB远程方法。
RMI(Remote Method Invocation,远程方法调用)是用Java在JDK1.1中实现的,它大大增强了Java开发分布式应用的能力。Java作为一种风靡一时的网络开发语言,其巨大的威力就体现在它强大的开发分布式网络应用的能力上,而RMI就是开发百分之百纯Java的网络分布式应用系统的核心解决方案之一。其实它可以被看作是RPC的Java版本。但是传统RPC并不能很好地应用于扽不是对象系统。而Java RMI 则支持存储于不同地址空间的程序级对象之间彼此进行通信,实现远程对象之间的无缝远程调用。
明天计划的事情:
疯一样做任务八,还有个比较棘手的小课堂
遇到的问题:
理解为上吧!没代码就没bug
收获:
1.外链的概念:
外链就是指在别的网站导入自己网站的链接。导入链接对于网站优化来说是非常重要的一个过程。导入链接的质量(即导入链接所在页面的权重)间接影响了我们的网站在搜索引擎中的权重。
外链是互联网的血液,是链接的一种。没有链接的话,信息就是孤立的,结果就是我们什么都看不到。一个网站是很难做到面面俱到的,因此需要链接到别的网站,将其他网站所能补充的信息吸收过来,连接外链不在于数量,而是在于链接外链的质量。
外链的效果不只是为了提高网站的权重,也不仅仅是为了提高某个关键词的排名。一个高质量的外部链接是可以给网站带来很好的流量。
2.远程调用:
所谓远程,并不需要分布在internet上。或者在局域网中,或者在同一台计算机的不同虚拟机之间,我们都可以称为远程。
3.客户端/服务器
这儿可以理解一个更为广义的定义。并不局限于浏览器和服务器。
(1)一台称为客户端的计算机向一台称为服务端的计算机进行请求和相应的过程。比如:有一个流程,超市的pos机向服务器A索取一个商品的价格,服务器A从数据库服务器B中获取商品的价格并把价格响应给pos机,这个过程中pos机与服务器A之间我们称pos机时客户端,服务器A是本次任务的服务器;在服务器A从数据库服务器B中获取商品的价格的过程中服务器A是本次任务的客户端,而服务器B是本次任务的服务器。
(2)一个软件向另一个软件进行通信时,动作发起方称为客户端,动作接收放为服务器。比如:IE浏览器对weblogic,weblogic不会主动向一个浏览器发送数据的,只有浏览器主动向服务器发送数据请求是weblogic对请求进行处理的。我们这时把浏览器称为客户端,把weblogic称为服务器。
(3)一个软件内部,一个方法A调用另外一个方法B时,我们把方法A称为本次调用的客户端,把方法B称为本次调用的服务器。
所以服务器,我们可以称呼有的为Web服务器,有的为数据库服务器等等!




评论