发表于: 2017-11-24 21:27:40
1 692
一;整理模糊的概念问题;
1;log4j相关
A;先说为什么不用sout……前段时间,我还很依赖这个,哪里有问题,在哪里定一个sout……看看到底是什么鬼………专业一点说就是:通常,我们写代码的过程中,免不了要输出各种调试信息。在没有使用任何日志工具之前,都会使用 System.out.println 来做到。 这么做直观有效,但是有一系列的缺点
a:不知道这句话是在哪个类,哪个线程里出来的
b:不知道什么时候前后两句输出间隔了多少时间
c:无法关闭调试信息,一旦System.out.println多了之后,到处都是输出,增加定位自己需要信息的难度
d:只能输出到控制台
很…………干…………
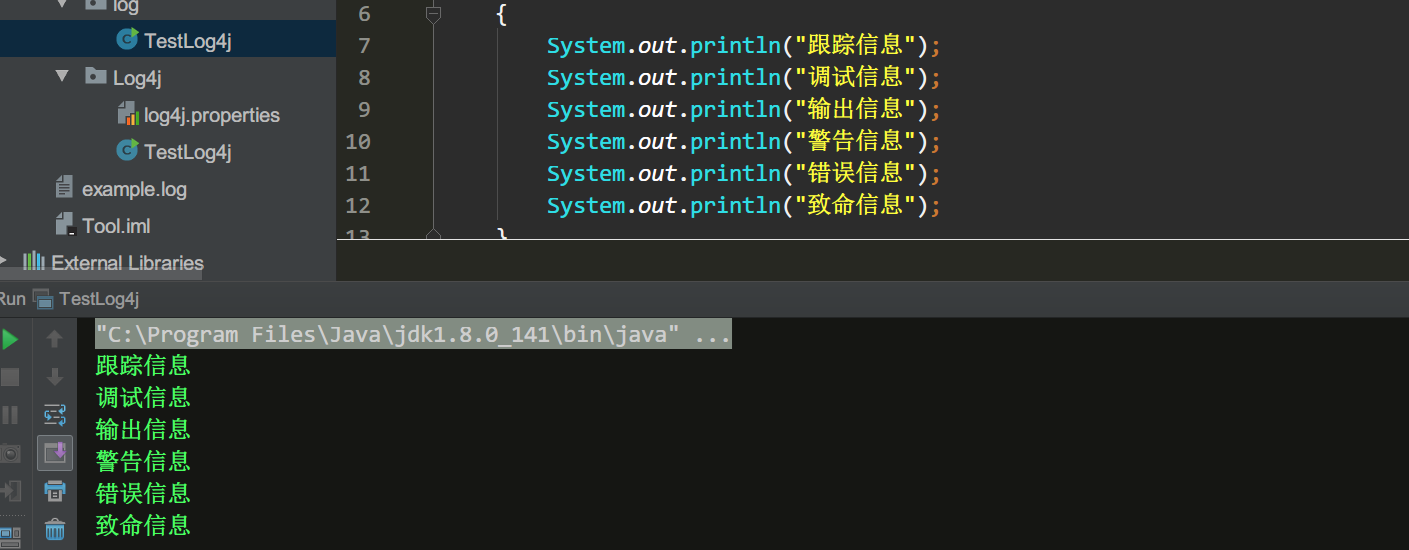
B:那么有了日志工具类,就很方便灵活了;……简单分析一下流程…..;
Log4j有三个主要的组件:Loggers(记录器),Appenders (输出源)和Layouts(布局)。
创建日志实例对象;为什么不能用new,这取决于Logge类;它不允许实例化一个新的记录器实例,但它提供了两个静态方法获得一个 Logger 对象;其中一个就是上面的,另外一个就不说了;
//基于类名获取日志对象
private static Logger logger =Logger.getLogger(Test.class);
然后是Logging方法; 得到了一个名为记录器的实例之后,可以使用记录的几种方法来记录消息;Logger类有专门用于打印日志信息的方法,
logger.debug("调试");
logger.info("输出");
然后配置文件信息参数没什么好说的,自己挨个试一遍就知道;
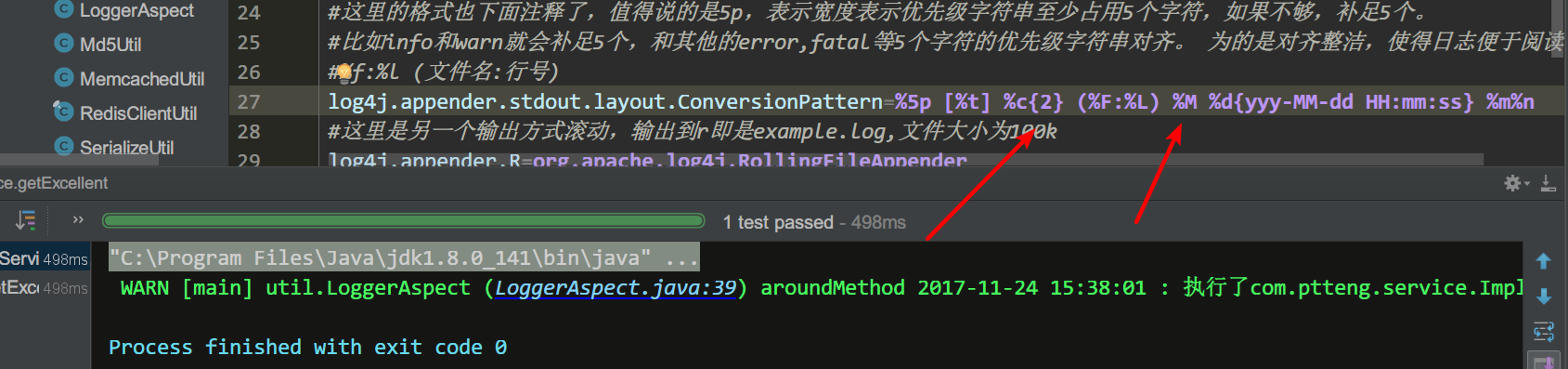
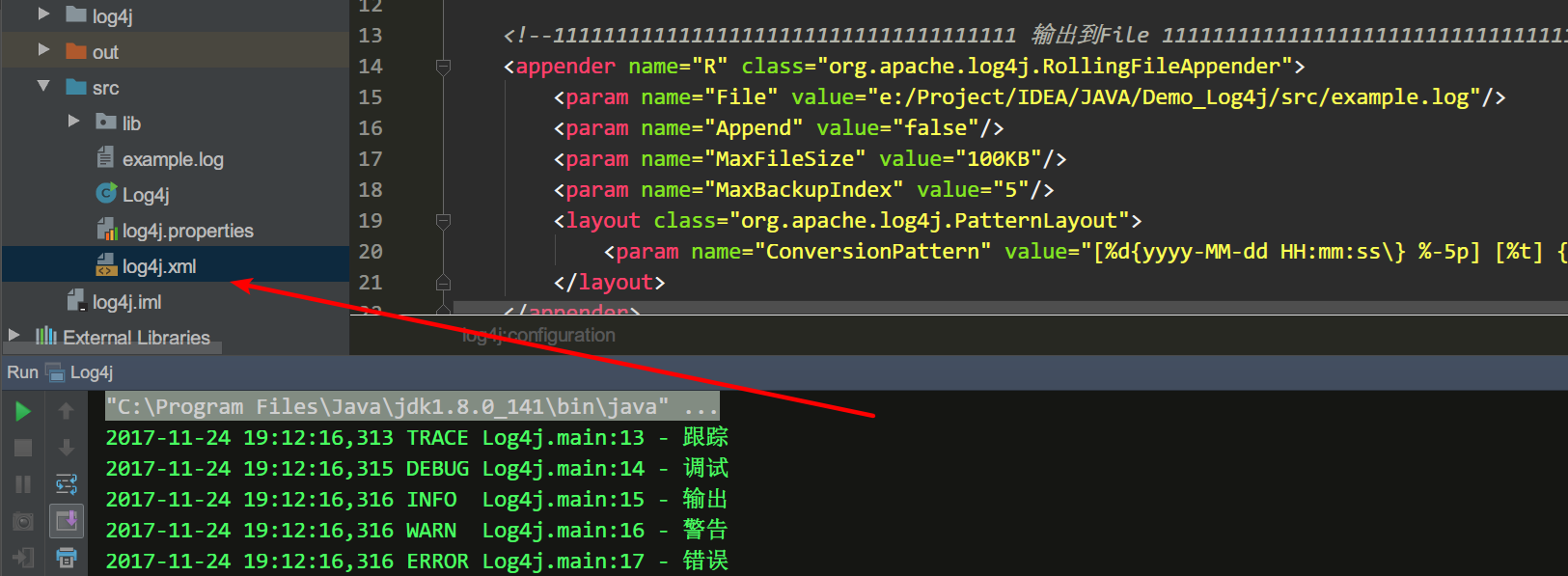
C;配置文件里的另一个最重要的信息;怎么输出到文件…那就是必须使用org.apache.log4j.FileAppender;而实际运用中,我们通常用的是其扩展类;并且继承了属性的RollingFileAppender类;这是因为我们的日志需要根据大小一定的阈值;来把日志分开为多个文件……
log4j.appender.R=org.apache.log4j.RollingFileAppender
这里的滚动输出也很好理解,简单操作就行了……滚两个试一下.....
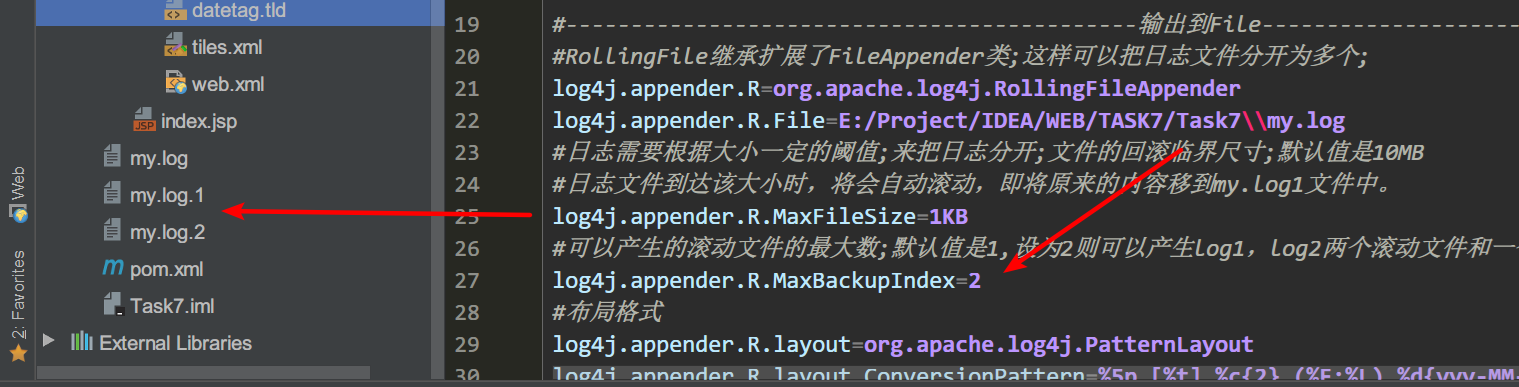
然后说两个默认参数.了解一下………
第一个true;一旦有新日志写入,立马将日志写入到磁盘的文件中。当日志很多,就像昨天jmeter压测信息;频繁操作文件性能很低下;可以使用BufferedIO和BufferSize……mark….
第二个true;是追加到日志末尾;如果false则是重写….
# Set the immediate flush to true (default)
log4j.appender.R.ImmediateFlush=true
# Set the append to false, overwrite!!!(true default)
log4j.appender.R.Append=true
D;最后再说一个;配置文件的log4j.properties加载机制;
在Java项目比较好理解;直接加载配置信息
//构造记录器,形参是记录器所在的类,表示要在该类做日志
private static Logger logger = Logger.getLogger(Log4j.class);
public static void main(String[] args)
//进行默认配置
//BasicConfigurator.configure();
//把默认换行注释掉,改成用配置文件来调用,配置文件位置
PropertyConfigurator.configure("E:*log4j.properties");
而在web项目中它放置的位置是在src目录下,因为这个时候tomcat会去默认的加载它的,不需要我们去手动的加载log4j的配置文件,只需要根据配置获取自己需要的logger实例即可;那怎么理解加载呢?
程序启动时,log4j组件去读log4j.properties,和读取普通配置文件没多大区别。获取用户配置的一些log4j的属性值,调用想应的方法为log4j属性设置。然后把log4j.properties当作一个xml文件.不同的是log4j不像spring,它不是一个独立的组件,没法自己完成初始化,都是什么组件需要它就去初始化,像springAOP需要它,那么spring启动的时候就会加载它……..如果没有配置log4j.properties估计也会报错吧……
试一下;删除log4j的配置文件….根本不让删除….应该是已经被当作组件运行了…
还有一点就是xml形式的,意义不大;效果一样,简单配一个试试,了解一下
到这里log4j的基本使用功能已经可以了;还有输出到邮箱,什么的暂时就不说了…….
二;学习扩展新知识;
1;昨天的nginx负载均衡有五种方式,轮询权重就不说了;试一下ip_hash
A:首先说下为什么会有这种负载均衡的策略……根据ip来分发????
因为普通的轮询;会把请求分发到不同的 Tomcat 来缓解服务器的压力,但是这存在一个问题:当同一个用户第一次访问tomcat1并且登录成功,而第二次访问却被分配到了tomcat2,那么就会呈现未登录状态了,嗯……这会……严重伤害……用户体验……要解决………ip_hash……
也很好理解操作……通过ip地址标记用户,如果请求都是从同一个ip来的,那么就都分配到同一个tomcat.这样就避免了session问题.upstream最后加上ip_hash;就行了。
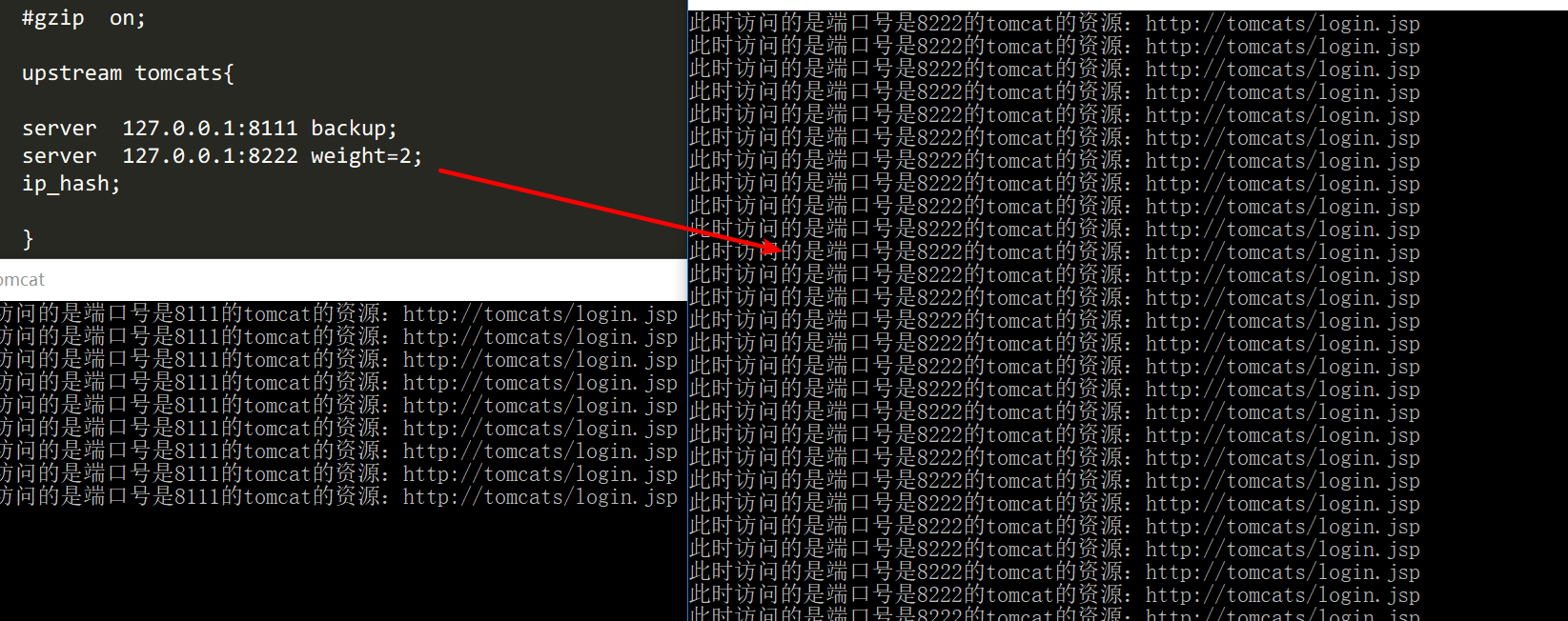
实际上这样处理还是有问题的,因为当在某一个大量访问的局域网内,用ip的话,就相当于没有负载均衡了………如果这台记录登陆状态的tomcat挂了,那转到第二台……还是没有登陆状态,还是……伤害……用户体验…….还有就是其他原因也限制比较多,像nginx前面不能有nginx了,不然找不到真正的IP…还有什么鬼的……
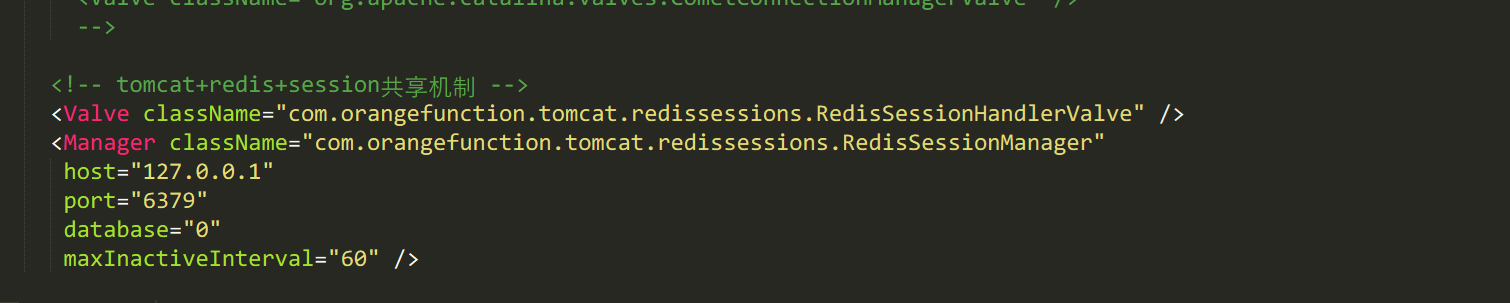
B:总之网上还有更为完善的解决办法,就是结合昨天的缓存机制,利用redis来存放登陆密码;这样的话,加入用户第一次登陆被分配到tom1,那么直接把用户信息保存到redis;当第二次访问被分到tom2;直接从redis取出值,这样的话,不仅实现了负载均衡,还满足了session共享…….
1;直接修改tomcat的配置文件就可以了;Session缓存指向redis
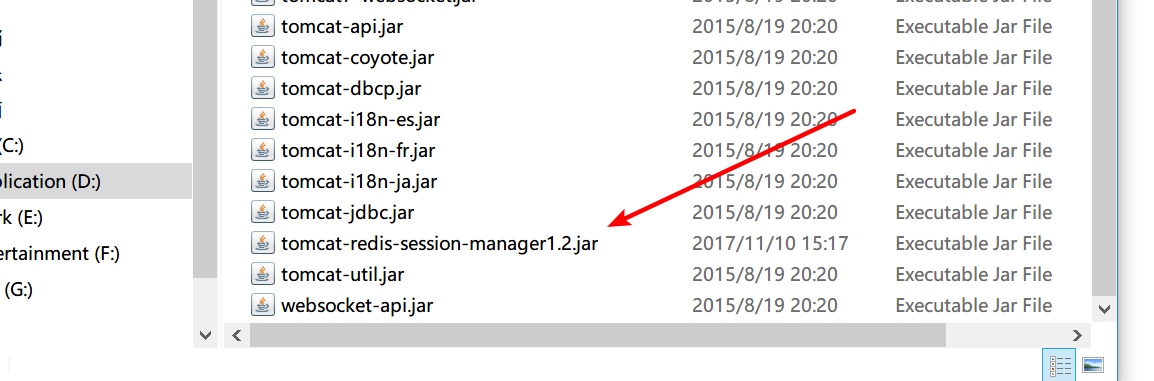
2;然后是找到tomcat链接redis的相关jar放进去;
3;然后就是测试;并且查看redis的是否生成key……大概意思是有的是保存到硬盘;有的是保存到内存了……证明保存了信息
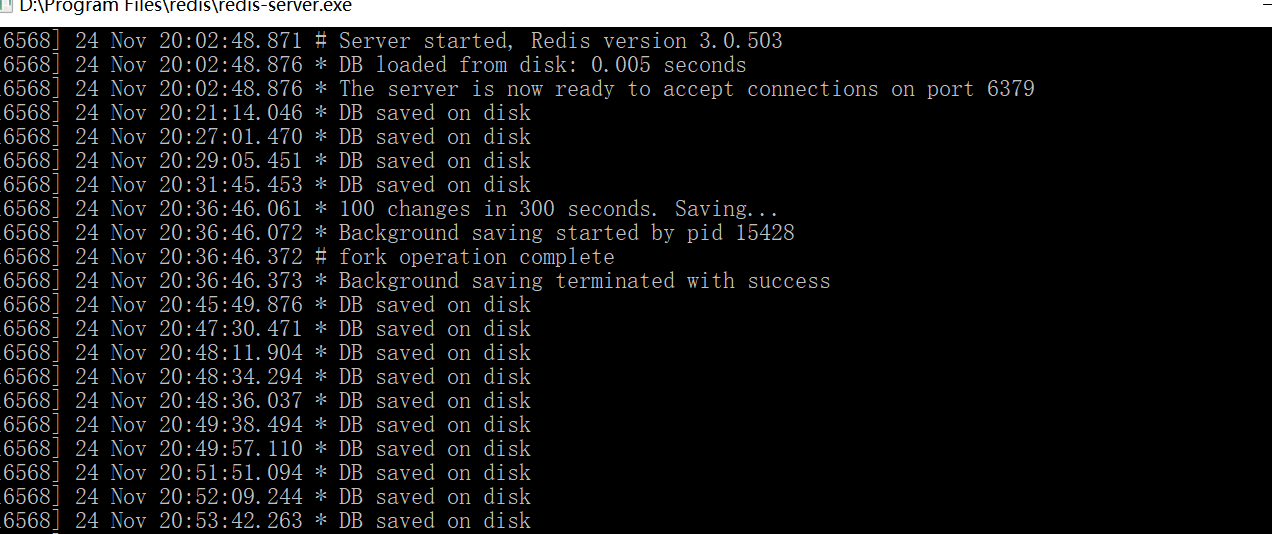
两次访问,只需要任意一处登陆,就可以了……而且只要一次登陆,就可以看到redis服务端查看也确实出现了新的key
三;学习java基础知识概念
1;java的关键字;super…简单说就是,
通过super关键字,可以调用父类的有参构造方法;
//使用关键字super显式调用父类带参的构造方法
public ADHero(String name)
super(name);
System.out.println("AD Hero的构造方法");
通过super关键字调用父类属性;
//通过super调用父类的moveSpeed属性
public int getMoveSpeed2()
return super.moveSpeed;
通过super关键字,调用父类方法
//重写userItem,并在其中调用父类的userItem方法
public void useItem(Item i)
System.out.println("adhero use item");
super.useItem(i);
default:即不加任何访问修饰符,只允许在同一个包中进行访问。
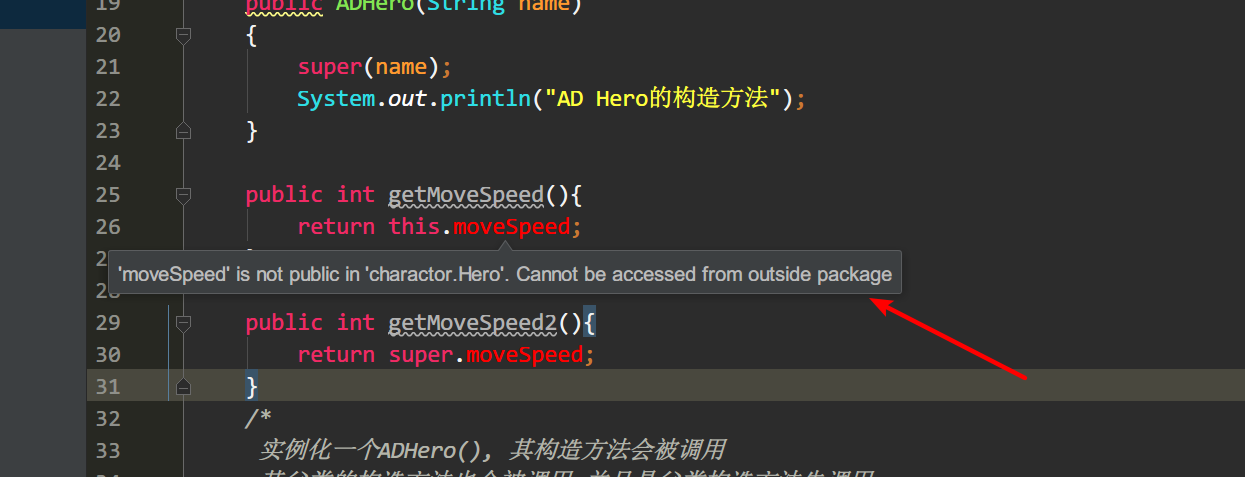
再复习一下访问修饰符,就不墨迹了…贴个图,加深记忆

四;简单了解一下新任务的相关概念;
1;api是什么………
API(Application Programming Interface),应用程序编程接口是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。
2;api的作用是什么……
- 对于软件提供商来说,留出API,让别的应用程序来调用,形成生态,软件才能发挥最大的价值,才能更有生命力(同时别人也看不见代码,不伤害商业机密)
- 对于应用开发者来说,有了开放的API,就可以直接调用多家公司做好的功能来做自己的应用,不需要所有的事情都自己操刀,节省精力。
3;什么是api文档……
接口里有很多函数,要使用这个库,但是并不知道每个函数内部是怎么实现的。使用的人需要看api文档或者注释才知道这个函数的入口参数和返回值或者这个函数是用来做什么的。对于用户来说,这些函数就是API,而使用的方法以及操作内容,是接口文档……
明日计划的事情:
1;集中精力;开始任务
2;学习一点基础知识
遇到的问题及解决方法:
休息一天;学习一下基础知识,加点小扩展,问题不大;赞无
收获:
1;对于log4j认识了更多,配置文件信息也掌握了很多
2;学习IP_hash以及session共享机制
3;学习几个的java基础知识




评论