发表于: 2017-11-06 18:02:27
1 719
1; 查看Nginx日志,编写脚本统计访问次数,统计响应延时。
首先在大佬的引导下改一下日志格式,完善一下日志信息;把内容补全
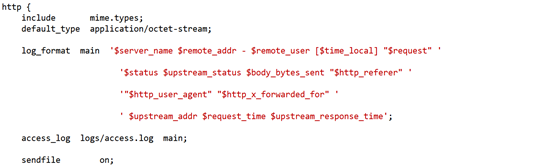
再把更改后的信息贴一下;对比理解加深记忆
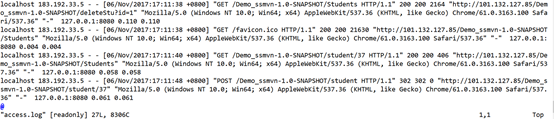
$server_name:虚拟主机名称。 $remote_addr:远程客户端的IP地址。
$remote_user:远程客户端用户名称,记录浏览者进行身份验证时提供的名字,登录的用户名没有就是空白。
[$time_local]:访问的时间与时区 $request:请求的URI和HTTP协议,
$status:记录请求返回的http状态码, $uptream_status:upstream状态,
$body_bytes_sent:发送给客户端的文件主体内容的大小 $http_referer:记录从哪个页面链接访问过来的。
$http_user_agent:客户端浏览器信息
$http_x_forwarded_for:用了反向代理之后,不能获取到真实客户端的IP地址了,是反向代理服务器的iP地址。反向代理服务器在转发请求的http头信息中,可以增加x_forwarded_for信息,用以记录原有客户端的IP地址和原来客户端的请求的服务器地址。
$upstream_addr:upstream的地址,即真正提供服务的主机地址ip。 $request_time:整个请求的总时间。
$upstream_response_time:请求过程中,upstream的响应时间。
2;统计时间,也就是响应延时,这里先学习awk print;看了一下博客,命令参数太多了,只说用到的吧;
简单来说AWK是一种优良的文本处理工具;可以创建简短的程序,这些程序读取输入文件、为数据排序、处理数
据、对输入执行计算以及生成报表等;这里就是取出日志的内容,来观察,基本语法
比如这个awk '{print $22}' access.log,就是查看日志里第二十二个字段,默认以空格为间隔;这样根据日志设置的格式来取之出来就可以了;
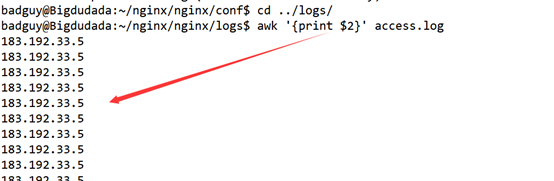
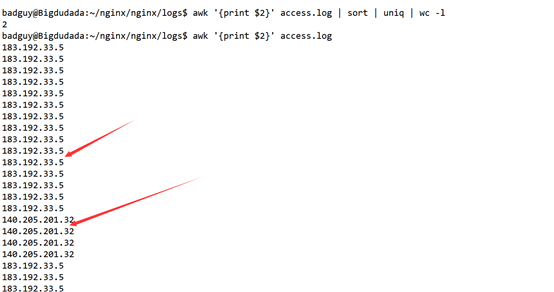
查看ip地址;awk '{print $2}' access.log
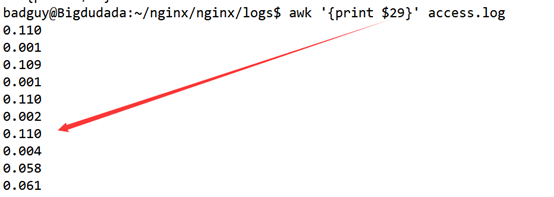
查看响应时间;
然后是通过awk '{print $2}' access.log | sort | uniq | wc -l来筛选
可以看到统计结果为2;列表也就是两个不同的ip,说一下sort是分类排序,uniq是筛选唯一, wc -l 命令计算行数
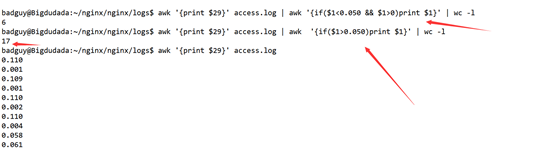
然后类似用awk进行二次筛选,来取出响应时间大于或者小于50ms的访问次数
awk '{print $29}' access.log | awk '{if($1>0.050)print $1}' | wc -l
awk '{print $29}' access.log | awk '{if($1<0.050 && $1>0)print $1}' | wc -l
这里|说一下, 重要的重定向工具"管道",通过使用|(管道)符号,可以重定向stdout流。简单来说一个最实用的用
法, 在文件里搜索的时候,可以直接用grep(grep命令Global Regular Expression Print,它能使用正则表达式搜
索文本,并把匹 配的行打印出来,它的使用权限是所有用户);如果需要在另一个命令的输出中查找某些东西,就可
以重定向输出到文件,然后再在文件里头查找,还有就是管道重定向总是从左至右的;这样在一定程度上也可以避免
临时文件的产生
3;知道怎么查看计数,就可以编写脚本了
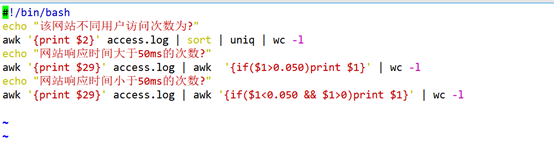
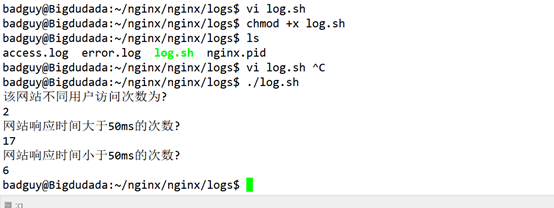
4;top命令的使用, top命令经常用来监控linux的系统状况,比如cpu、内存
首先top进入视图
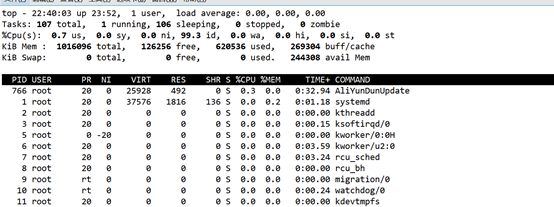
这里也学习了解一下;试图分为上下两块;上面一块;可以理解为内存的分析参数
第一行:
22:40— 当前系统时间 up— 系统已经运行了23小时52分钟(没有重启过) users — 有1个用户登录系统
load average负载— load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况,可以根据一定的算法来计算是否超负荷
Tasks — 任务进程,系统现在共有107个进程,其中处于运行中的有1个,106个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行是cpu,暂时没了解,牵涉到linux的内核空间以及用户空间
Kib mem; 内存状态 total — 物理内存总量(1GB) used — 使用中的内存总量(600M)
free — 空闲内存总量(130M) buffers — 缓存的内存量 (270M)
第五行:swap交换分区,这个也不多说了,最后是缓存交换的量240M
这样看系统要炸了…没内存了,1g的内存剩下130M…然后了解到,不能一win的角度去看; 第四行中使用中的内存总
量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入
内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使
用的内存交还到free中去,因此在linux上free内存会越来越少,
有个近似的计算公式:第四行的free + 第四行的buffers + 第五行的avail,按这个公式可用内存:240+270+130= 640M
5;进程图, 各进程(任务)的状态监控;列举一下,以后用到再查阅
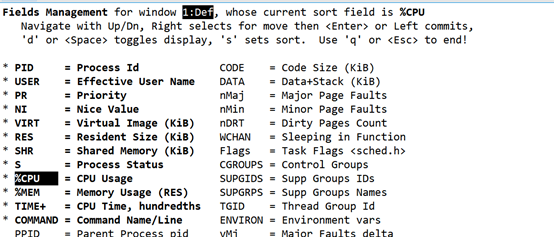
PID — 进程id USER — 进程所有者 PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
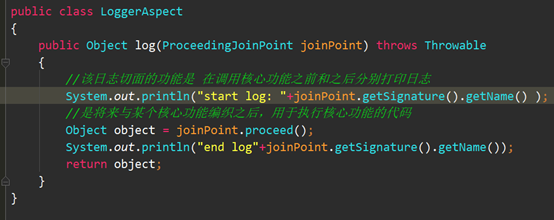
6;最后是学习AOP;之前学习spring就避开了这一块,这次要求打日志,必须学了,师兄也说,这个打印日志很方便;
先说一下概念: Aspect Oriented Program 面向切面编程;思想就是把功能分为核心业务功能,和周边功能;核心业务,比如登陆,增加数据,删除数据;周边功能,比如性能统计,日志,事务管理等等.周边功能在Spring的面向切面编程AOP思想里,即被定义为切面;AOP的思想里面,核心业务功能和切面功能分别独立进行开发然后把切面功能和核心业务功能 "编织" 在一起,这就叫AOP
基础不好,从最基础的aop学习,引入切面
业务类
测试类,这个时候不用切面,业务同样可以调用打印
准备日志切面 LoggerAspect;功能是在调用核心功能之前之后分别打印日志
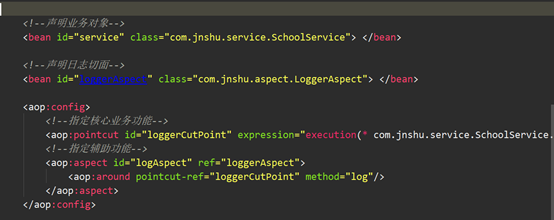
配置文件, 把切面和核心业务类编制在了一起。
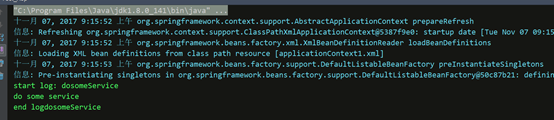
结果,之前之后执行了打印
明日计划的事情:
1;切面有点难,继续学习aop
2;准备小课堂
3;完善任务三
遇到的问题及解决方法:
1;刚接触aop有点难
2;linux操作起来还是慢
收获:
1;熟悉了更多的linux命令.
2;简单查看分析日志
3;初步学习aop




评论