发表于: 2017-10-26 21:31:31
3 574
1;昨天简单看了http协议,发现浏览器可以用调试工具来看,不过没有深究,就简单看了一下,等学完这一块的请求响应再回头看吧;
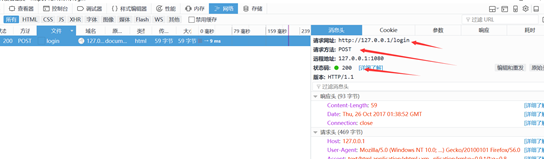
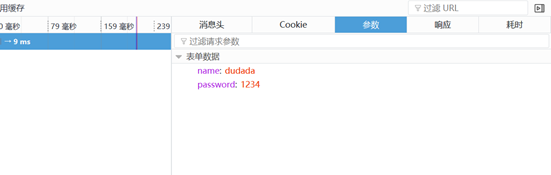
也简单小结一下;就是通过浏览器的调试工具,能看到浏览器和服务器交互的信息,比如说主要的请求信息(请求行,请求头部,请求数据),响应信息(响应行,消息头部,响应正文),以及请求方法和状态码;其中状态码有多种,而常见的就是上面的200就是表示请求成功,还有500 表示服务端的错误;还有301和302好像涉及到数据库,这个具体后说。
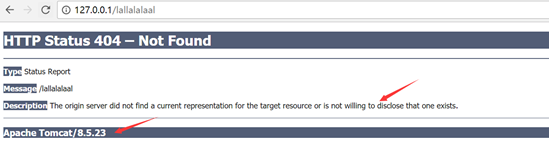
其实最近我感觉最常见的是404表示访问的页面不存在.。。。比如下面随便输入一个就是404,也就是说当一个页面不存在,就会得到404的响应状态码,这表示一个浏览器的错误,不能算汤姆猫,因为是tomcat没提供这个服务,但是web却去访问。不过另一方面404的问题也很多,比如配置文件路径错误,资源配置错误等。
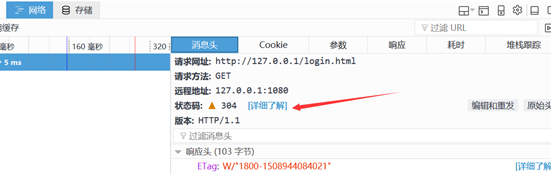
再提一下304 表示资源未被修改,这个也可以细说一下;就拿昨天的登陆界面来看,第一次访问之后的访问就会得到304提示。这是tomcat在提示浏览器,这个静态html资源没有发生改变,直接使用第一次下载的,不用重新下载,这样的话就节约了带宽,提高浏览器的加载速度。
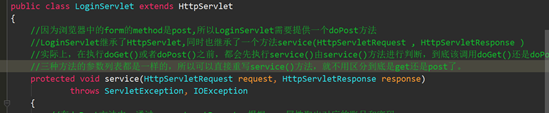
2;继续学习servlet发现还有一种方法可以用,昨天是get或者post,这两个方法应该是继承了父类Servlet extends HttpServlet的方法,下面重写调用;而Servlet继承httpservlet的同时还继承了service(httpServletRequest httpServletResponse)方法,而实际上再调用get和post的方法之前还是要通过service方法来判断,到底是哪一个的,这样看的话,直接用service方法也是行的通的;毕竟方法参数一致,下面做了简单修改很ok
3;想把登陆界面改成中文发现会乱码,学习一下怎么解决中文乱码
首先可以确定request获取的数据会乱码,控制台可查看

然后登陆界面的response反应数据也会乱码,浏览器可查看
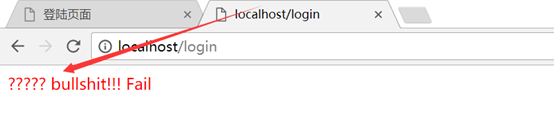
这样看起来解决办法是类似,解决获取的中文有两种,一种比较麻烦的是在中文参数的下面通过tomcat的编码方式先解码,然后再转为utf-8,这个原理放到下面解释了;还有一种比较简单的就是直接在中文的参数上面直接定义utf-8;都可行
//在doPost方法中,通过request.getParamter根据name属性取出对应的账号和密码,并且定义编码格式为utf-8
request.setCharacterEncoding("UTF-8");
String name = request.getParameter("name");
//这个是放到中文参数的下面,获取之后先解码,然后转码
//tomcat对于post提交的数据默认的编码方式是ISO-8859-1,这样解析就会乱码;由于ISO-8859-1是单字节编码
//所以先这样重新编码,得到是不乱码的utf-8,然后再utf-8编码即可
byte[] bytes = name.getBytes("ISO-8859-1");
name = new String(bytes, "UTF-8");
String password = request.getParameter("password");
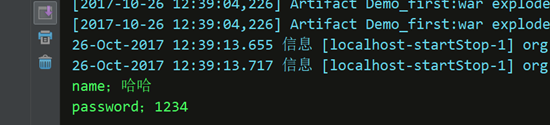
修改之后正常显示获取的数据
然后是解决返回的中文数据直接在参数上面定义好utf-8格式
//通过response.getWriter().println()发送到浏览器,并且定义响应到浏览器的文本格式为utf-8;
response.setContentType("text/html;charset = UTF-8");
PrintWriter pw = response.getWriter();
//pw是代表服务端发向浏览器的输出流
修改之后正常显示返回的数据
这里涉及到第一种解释先用服务器的默认编码重新编码然后解码的原理有个解释很好理解:meta元素说一下,有教程两种方式看起来定义的不太一样,实际上效果相同,只是版本区别
<!--<meta> 元素可提供有关页面的元信息(meta-information),比如针对搜索引擎和更新频度的描述和关键词。-->
<!--<meta> 标签位于文档的头部,不包含任何内容。<meta> 标签的属性定义了与文档相关联的名称/值对。-->
<meta charset="UTF-8">
<!--上面那个和下面这个效果一样,区别在于<meta charset="UTF-8"> 是html5之后才开始支持的写法。-->
<!--有的一些老的不支持html5的浏览器要采用旧式的第二种写法,才可以正常的显示中文。-->
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>登陆页面</title>
然后编码解码原理<meta ;charset=UTF-8"> 这句话加在html以后,浏览器把输入的参数编码成utf-8的字节发送给了tomcat而 tomcat对于post提交的数据默认的编码方式是ISO-8859-1,也就是它用ISO-8859-1解析了utf-8编码之后的字节。这就是乱码的原因,同时由于ISO-8859-1是单字节编码, 所以可以通过byte[] bytes= name.getBytes("ISO-8859-1")进行重新编码可以得到没有被tomcat解析过的utf8字节串。 然后再用utf-8解码就能得到正常的utf-8数据了。
4;查看servlet的生命周期
当调用post方法时实例化
//通过浏览器输入一个路径,这个路径对应的servlet被调用的时候,该Servlet就会被实例化
//为LoginServlet显示提供一个构造方法 LoginServlet(),LoginSerlvet构造方法只会执行一次,所以Serlvet是单实例的。
public LoginServlet()
{
System.out.println("loginservlet无参构造方法执行了");
}并且用继承方法进行初始化
//LoginServlet继承了HttpServlet,同时也继承了init(ServletConfig)方法,进行初始化
//init方式是一个实例方法,所以会在构造方法执行后执行,而且只会被执行一次。
public void init(ServletConfig config)
{
System.out.println("初始化方法initial执行了");
}看输出台,印证结论

然后是通过servlet方法进行业务处理,这里登陆界面实际上就是对账号密码的判断,算是提供服务;
//自定义账号密码,然后创建对应的html字符串,用equals来做对比,
if ("dudada".equals(name) && "1234".equals(password)) {
//结果正确就打印success字符串;错误则是bullshit
html = "<div style ='color:green'> 登陆成功: bravo!!! </div>";
} else {
//HTML <div> 元素是块级元素,它是可用于组合其他 HTML元素的容器。
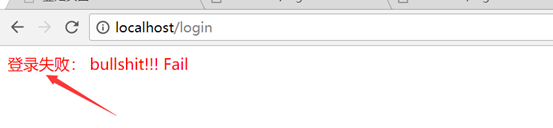
html = "<div style ='color:red'> 登录失败: bullshit!!! </div>";
}
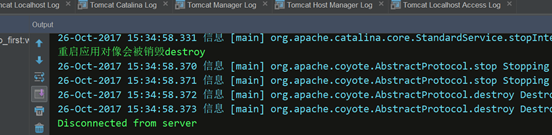
接着就是服务完被销毁,哇,这个好麻烦的,把方法写好,发现一直找不到,实际上是一闪而过,重启的时候可以看到,这里抓个图,而且必须是对象被实例化之后,不然也不会有对象被销毁
//关闭tomcat和web应用重启的时候destroy()方法会被调用,但是这个发生的很快,在控制台要抓取,哈哈。
public void destroy()
{
System.out.println("重启应用对像会被销毁destroy");
}
最后就是涉及到GC机制了,百度一下Java GC(Garbage Collection,垃圾收集,垃圾回收)机制,作为Java开发者,一般不需要专门编写内存回收和垃圾清理代码,对内存泄露和溢出的问题,也不需要考虑过多,就是因为在Java虚拟机中,存在自动内存管理和垃圾清扫的GC机制。
总结一下:到这里一个servlet类的完整生命周期就走完了;实例化—初始化—业务执行—销毁—垃圾回收。
5;学习简单跳转;这里涉及两个概念,服务端和客户端两种跳转方式;
这里也先了解一下概念:服务器端跳转是由客户端发送一个请求,请求一个服务器资源——如JSP和Servlet——,这个资源又将请求转到另一个服务器资源,然后再给客户端发送一个响应,也就是说服务器端跳转是客户端发送一次请求,服务器端给出一次响应;而客户端跳转的流程则不同。客户端同样是发送一个请求给服务器端资源,这个服务器资源会首先给客户端一个响应,客户端再根据这个响应当中所包含的地址,再次向服务器端发送一个请求,也就是说客户端跳转是两次请求,两次响应;这样来看的话就是服务端更便于传输数据,而客户端就完全是另一个页面。
然后是代码表现,服务器端跳转是使用RequestDispather对象的forward方法实现
if ("dudada".equals(name) && "1234".equals(password)) {
//getRequestDispatcher("success.html")设定要访问的页面forward去访问
request.getRequestDispatcher("success.html").forward(request, response);
改完之后上来就给我来个404.。。。其实是个小问题,,顺手写成xml了。。。。
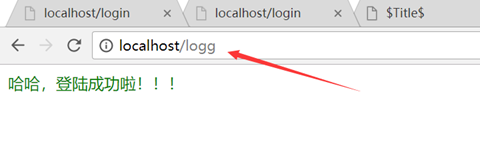
修改之后很ok路径没变,证明在服务器端跳转了一下
而客户端跳转是response.sendRedirect();
} else {
//响应给浏览器,让他去访问fail这个页面
response.sendRedirect("fail.html");
}
System.out.println("name;" + name);
可以看一下访问路径变了,变成fail.html了,这也就证明发生了客户端跳转。
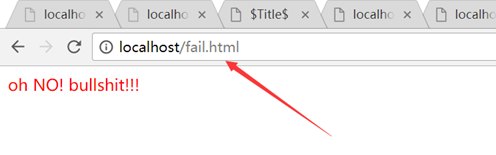
对比写的上一个没有跳转的失败页面,这里路径没有变化的
6;又看到说web应用自启动的方法
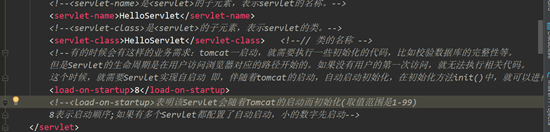
测试可行

7;之前关于mybatis感觉不够熟悉流程,尤其是注解方式,今天再重新做一遍,再看一下注解方式和xml方式的区别;具体流程就不再赘述了,说几个重要的。
首先是建立StudentMapper接口,然后在接口的声明的方法上加注解,这一步实际上就是把之前的xml里的sql语句放到注解上了
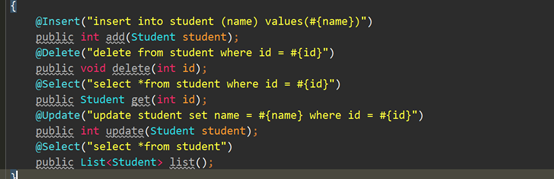
然后在mybatis配置文件加上映射,就是为了让配置读取到这个类的方法
<mappers>
<!--<mapper resource="Student.xml"/>-->
<mapper class="com.jnshu.Mapper.StudentMapper"/>
</mappers>测试类就不说了,整体就是重新写了一遍感觉更透彻一些吧。
明日计划的事情:
1;完成servlet最后的内容动态web,普通的做了一遍,接下来应该容易不少。
2;时间果然不够用了,mvc也算是按照计划放到明天了
3;然后是语法基础的补习
遇到的问题及解决方法:
内容比较基础,问题不大,就一个中文乱码;问题以及解决思路也都写在上面了
收获:
1;关于web的相关知识概念的理解与应用:servlet完整的生命周期,http协议,页面的两种跳转方式,中文乱码,还有web应用自启动等
2;简单的语法基础学习




评论