发表于: 2018-10-18 23:31:58
1 422
今天完成的事情:(一定要写非常细致的内容,比如说学会了盒子模型,了解了Margin)
一、了解数据库,一对一,一对多,多对多的关系,以及什么是关系表
数据库实体表数据具有一对一,一对多,多对多。
例如:
一对一关系示例:
- 一个学生对应一个学生档案材料,或者每个人都有唯一的身份证编号。
一对多关系示例:
- 一个学生只属于一个班,但是一个班级有多名学生。
多对多关系示例:
- 一个学生可以选择多门课,一门课也有多名学生。
1.一对多关系处理:
通过学生和班级问题了解一对多:

设计数据库表:只需在 学生表 中多添加一个班级号的ID;
注:在数据库中表中初学时,还是通过添加主外键约束,避免删除数据时造成数据混乱!
2.多对多关系处理:
通过学生选课了解多对多问题的处理:

在多对多中在一个表中添加一个字段就行不通了,所以处理多对多表问题时,就要考虑建立关系表了
例:
学生表: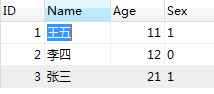 课程表:
课程表: 关系表:
关系表: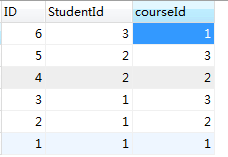
注:所以对于多对多表,通过关系表就建立起了两张表的联系!多对多表时建立主外键后,要先删除约束表内容再删除主表内容
实体表就是对应实际的对象的表,比如:学生表,老师表
关系表是表示表与表之间的数据关系,我的理解是:关系表设计一般只存在多对多。
了解数据库的建表规范 三大范式
1.第一范式(确保每列保持原子性)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。
2.第二范式(确保表中的每列都和主键相关)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
3.第三范式(确保每列都和主键列直接相关,而不是间接相关)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。
建表的规范
1.【强制】表达是与否概念的字段,必须使用 is_xxx的方式命名,数据类型是 unsigned tinyint( 1表示是,0表示否),此规则同样适用于 odps建表。
说明:任何字段如果为非负数,必须是 unsigned。
个人备注:
Open Data Processing Service, 简称ODPS;是由阿里云自主研发,提供针对TB/PB级数据、实时性要求不高的分布式处理能力,应用于数据分析、挖掘、商业智能等领域;阿里巴巴的离线数据业务都运行在ODPS上;。
2.【强制】表名、字段名必须使用小写字母或数字;禁止出现数字开头,禁止两个下划线中间只出现数字。数据库字段名的修改代价很大,因为无法进行预发布,所以字段名称需要慎重考虑。
正例:getter_admin,task_config,level3_name
反例:GetterAdmin,taskConfig,level_3_name
3.【强制】表名不使用复数名词。
说明:表名应该仅仅表示表里面的实体内容,不应该表示实体数量,对应于 DO类名也是单数形式,符合表达习惯。
4.【强制】禁用保留字,如 desc、range、match、delayed等,请参考 MySQL官方保留字。
5.【强制】唯一索引名为 uk_字段名;普通索引名则为 idx_字段名。
说明:uk_ 即 unique key;idx_ 即 index的简称。
6.【强制】小数类型为 decimal,禁止使用 float和 double。
说明:float和 double在存储的时候,存在精度损失的问题,很可能在值的比较时,得到不正确的结果。如果存储的数据范围超过 decimal的范围,建议将数据拆成整数和小数分开存储。
7.【强制】如果存储的字符串长度几乎相等,使用 char定长字符串类型。
8.【强制】varchar是可变长字符串,不预先分配存储空间,长度不要超过 5000,如果存储长度大于此值,定义字段类型为 text,独立出来一张表,用主键来对应,避免影响其它字段索引效率。
9.【强制】表必备三字段:id, gmt_create, gmt_modified。
说明:其中 id必为主键,类型为 unsigned bigint、单表时自增、步长为 1。
gmt_create,gmt_modified的类型均为 date_time类型。
10.【推荐】表的命名最好是加上“业务名称_表的作用”。
正例:tiger_task / tiger_reader / mpp_config
11.【推荐】库名与应用名称尽量一致。
12.【推荐】如果修改字段含义或对字段表示的状态追加时,需要及时更新字段注释。
13.【推荐】字段允许适当冗余,以提高性能,但是必须考虑数据同步的情况。冗余字段应遵循:
1)不是频繁修改的字段。
2)不是 varchar超长字段,更不能是 text字段。
正例:商品类目名称使用频率高,字段长度短,名称基本一成不变,可在相关联的表中冗余存储类目名称,避免关联查询。
14.【推荐】单表行数超过 500万行或者单表容量超过 2GB,才推荐进行分库分表。
说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
15.【参考】合适的字符存储长度,不但节约数据库表空间、节约索引存储,更重要的是提升检索速度。
正例:人的年龄用 unsigned tinyint(表示范围 0-255,人的寿命不会超过 255岁);海龟就必须是 smallint,但如果是太阳的年龄,就必须是 int;如果是所有恒星的年龄都加起来,那么就必须使用 bigint。
明天计划的事情:
理清需求,设计DB数据库表格




评论