发表于: 2018-09-17 23:16:35
2 401
编辑日今天完成的事情:
协议是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则,超文本传输协议(HTTP)是一种通信协议,它允许将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器
目前我们使用的是HTTP/1.1 版本



9.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
不需要,唯一索引如果检测到有重复会拒绝插入。
10.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
前者在数据插入是赋值,后者在数据被更改是赋值,属于数据库内部属性,不建议开放给外部调用。
11.修真类型应该是直接存储Varchar,还是应该存储int?
本来我想的是Varchar,但是随着深入了解,发现还是int好,首先可以建立一个表用来存储修真类型和相应int数字的映射,然后在总表上直接用int即可。能够用数字类型的字段尽量选择数字类型而不用字符串类型的,这会降低查询和连接的性能,并会增加存储开销。因为引擎在处理查询和连接会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
12.varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
varchar的长度取决于数据长度加一,附加的一用来存储数据长度。既然说道varchar,不得不说char,两者的特点主要体现在以下:
1). char(n)和varchar(n)中括号中n代表字符的个数,并不代表字节(Byte)个数,所以当内容为中文又使用UTF8编码时意味着可以插入n个中文,但是实际会占用3*n个字节。
2). 同时char和varchar最大的区别就在于char不管实际数据多长,都会占用n个字符的空间,而varchar只会占用实际字符应该占用的空间+1,并且实际空间+1<=n,因为>n会被截断。
3). 超过char和varchar的n设置后,字符串会被截断。
4). char的上限为255字节(2^8-1)字节(Byte),varchar的上限65535(2^16-1)字节(Byte)。
5). char在存储的时候会截断尾部的空格,varchar和text不会。
6). varchar会使用1-3个字节来存储长度,text不会。
而关于Text和LongText
text:存储可变长度的非Unicode数据,最大长度为2^16-1个字符。text列不能有默认值,存储或检索过程中,不存在大小写转换,后面如果指定长度,不会报错误,但是这个长度是不起作用的,意思就是你插入数据的时候,超过你指定的长度还是可以正常插入
Unicode数据:世界统一编码,与字符集无关。非Unicode数据:只要字符集变了,数据就出现乱码,无法使用。
LongText 最大长度4294967295个字符 (2^32-1)。
13.怎么进行分页数据的查询,如何判断是否有下一页?
select * from table order by id limit (intPage - 1) * PageRow , intPage * PageRow
PageRow 每页多少条记录
intPage 页数
可以先通过count(id)函数获得数据量,然后除以每页展示数可以得到页数。
15.什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
贫血模型:是指领域对象里只有get和set方法,或者包含少量的CRUD方法,所有的业务逻辑都不包含在内而是放在业务逻辑层。
充血模型: 层次结构和上面的差不多,不过大多业务逻辑和持久化放在Domain Object里面,Business Logic只是简单封装部分业务逻辑以及控制事务、权限等。
贫血模型有利于层次的划分,功能的模块化,即领域对象只充当数据载体,也便于后续的维护。
16.Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
控制反转(Inversion of Control),就是由容器控制程序之间的关系,而非传统实现中,由程序代码直接控制。这也就是所谓“控制反转”的概念所在:控制权由应用代码中转到了外部容器,控制权的转移,就是所谓反转。
这样将对象统一的放在IOC容器中,方便了管理对象和处理对象的依赖关系,减少了程序间的耦合。
17.为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
接口相当于一种规范,只是制定好规范但是具体怎么实现却各有各的实现,如果连接mysql数据库有mysql的实现方法,如果是orecal又有一套实现方法,如果是其他数据库可能实现细节上又会不一样,但大家大体实现的功能是一样的,这就是接口的功能。
二、关于Hosts/DNS的理解。
hosts是什么,DNS是什么,两者区别?
Hosts是一个没有扩展名的系统文件,可以用记事本等工具打开,其作用就是将一些常用的网址域名与其对应的IP地址建立一个关联“数据库”,当用户在浏览器中输入一个需要登录的网址时,系统会首先自动从Hosts文件中寻找对应的IP地址,一旦找到,系统会立即打开对应网页,如果没有找到,则系统会再将网址提交DNS域名解析服务器进行IP地址的解析。
需要注意的是,Hosts文件配置的映射是静态的,如果网络上的计算机更改了请及时更新IP
地址,否则将不能访问。
IP和域名映射的两种方式。Hosts和DNS
1)静态映射,每台设备上都配置主机到IP地址的映射,各设备独立维护自己的映射表,而且只供本设备使用;
2)动态映射,建立一套域名解析系统(DNS),只在专门的DNS服务器上配置主机到IP地址的映射,网络上需要使用主机名通信的设备,首先需要到DNS服务器查询主机所对应的IP地址。
hosts和DNS渊源
在引入DNS(Domain Name System,域名系统)之前,网络中的主机是将容易记忆的域名映射到IP地址并将它保存在一个共享的静态文件hosts中,再由hosts文件来实现网络中域名的管理。最初Internet非常小,仅使用这个集中管理的文件就可以通过FTP为连入Internet的站点和主机提供域名的发布和下载。每个Internet站点将定期地更新其主机文件的副本,并且发布主机文件的更新版本来反映网络的变化。
但是,当Internet上的计算机迅速增加时,通过一个中心授权机构为所有Internet主机管理一个主机文件的工作将无法进行。文件会随着时间的推移而增大,这样按当前和更新的形式维持文件以及将文件分配至所有站点将变得非常困难,甚至无法完成,于是便产生了DNS服务器。浏览器访问网站,要首先通过DNS服务器把要访问的网站域名解析成一个唯一的IP地址,之后,浏览器才能对此网站进行定位并且访问其数据。
操作系统规定,在进行DNS请求以前,先检查系自己的Hosts文件中是否有这个域名和IP的映射关系。如果有,则直接访问这个IP地址指定的网络位置,如果没有,再向已知的DNS服务器提出域名解析请求。也就是说Hosts的IP解析优先级比DNS要高。
之前从数据库存储获得的毫秒值,可以通过以下方式转为易读性高的时间格式。
取出的时候使用SimpleDateFormat来转化为时间:
SimpleDateFormat stm = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String std = "创建时间为:" + stm.format(person.getUpdate_at()) + "\n";
String str = "修改时间为: " + stm.format(person.getUpdate_at()) + "\n";
3、springMVC流程梳理,即浏览器访问服务器的流程
Spirng常用注解:
@Controller 用于标记在一个类上,使用它标记的类就是一个SpringMVC Controller 对象。分发处理器将会扫描使用了该注解的类的方法。通俗来说,被Controller标记的类就是一个控制器,这个类中的方法,就是相应的动作。
1、@controller 控制器(注入服务)
2、@service 服务(注入dao)
3、@repository dao(实现dao访问)
4、@component (把普通pojo实例化到spring容器中,相当于配置文件中的<bean id=""
Information:java: Multiple encodings set for module chunk Springmvc1 "GBK" will be used by compiler
< url-pattern > / </ url-pattern > 不会匹配到*.jsp,即:*.jsp不会进入spring的 DispatcherServlet类 。
< url-pattern > /* </ url-pattern > 会匹配*.jsp,会出现返回jsp视图时再次进入spring的DispatcherServlet 类,导致找不到对应的controller所以报404错。
总之,关于web.xml的url映射的小知识:
< url-pattern>/</url-pattern> 会匹配到/login这样的路径型url,不会匹配到模式为*.jsp这样的后缀型url
< url-pattern>/*</url-pattern> 会匹配所有url:路径型的和后缀型的url(包括/login,*.jsp,*.js和*.html等)
找了个Eclips导出的非maven项目,导入到了IDEA中,跑起来了,兴奋,以后就可以跟这个教程了。主要有好多jar包,需要自己添加到lib下面。作者用的好多jar包版本都好低。
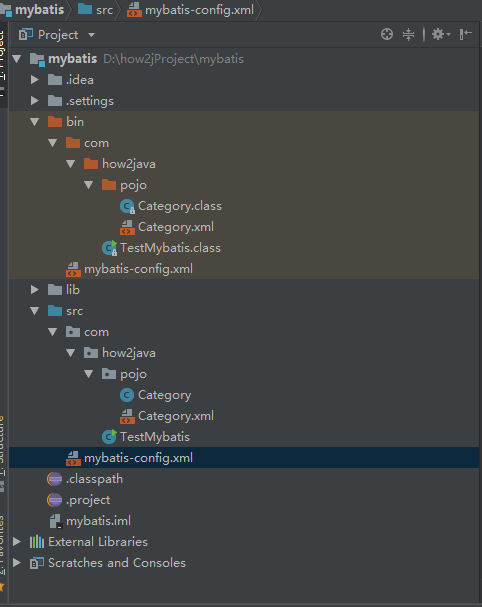
将导入的非maven项目改成了一个maven管理的项目结果结构。改了之后xml文件中的路径需要修改。
可以看出maven项目的项目结构,要比非maven项目的项目结构层次清晰,resources,src,tests三个文件夹下放着
不同性质的文件,而非maven项目把各种不同性质的文件混杂在了一一起,对日后的管理带来极大的不便。
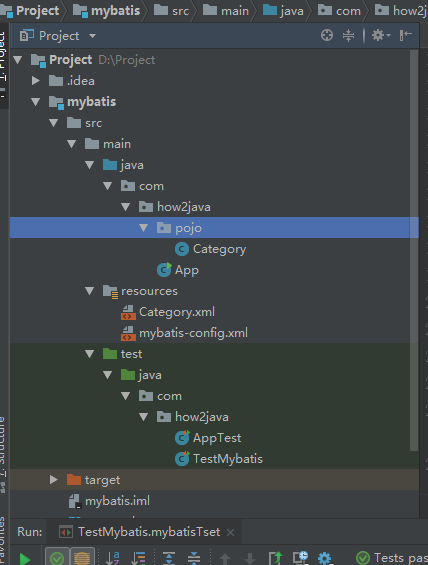
改写后将原来放在main方法下面的测试方法写在了测试类中,作者在加载配置文件时用的是
Resources.getResourceAsStream(resource)我刚开始用这个方法是报错的,是依赖的问题。
public class TestMybatis {
@Test
public void mybatisTset() throws IOException {
String resource = "mybatis-config.xml";
// InputStream inputStream =TestMybatis.class.getClassLoader().getResourceAsStream(resource);
InputStream inputStream =org.apache.ibatis.io.Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession session=sqlSessionFactory.openSession();
List<Category> cs=session.selectList("listCategory");
for (Category c : cs) {
System.out.println(c.getName());
}
}
明天计划的事情:再做一SSM,完成rest风格和分页功能。
遇到的问题:无
收获:对mybatis的配置更加熟悉了,了解了HTTP协议,DNS.对浏览器请求服务器的流程进一步熟悉了。听帆哥讲分布式,大概有了一个了解,看到了师兄写的代码规范很规范,该打日志打日志,该分层分层。




评论