发表于: 2018-09-09 23:24:53
1 429
今天完成的事情
1.重新学习了下sql的查询
1.1简单的查询
先创两张表,一张是学生基本信息表,一张是学生成绩表

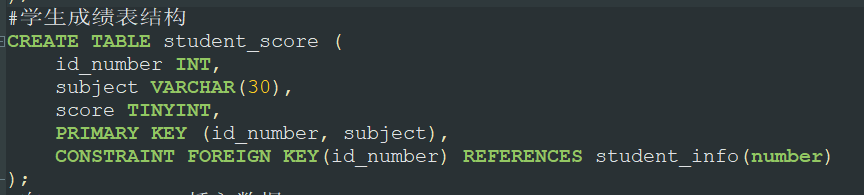
1.1.1插入数据
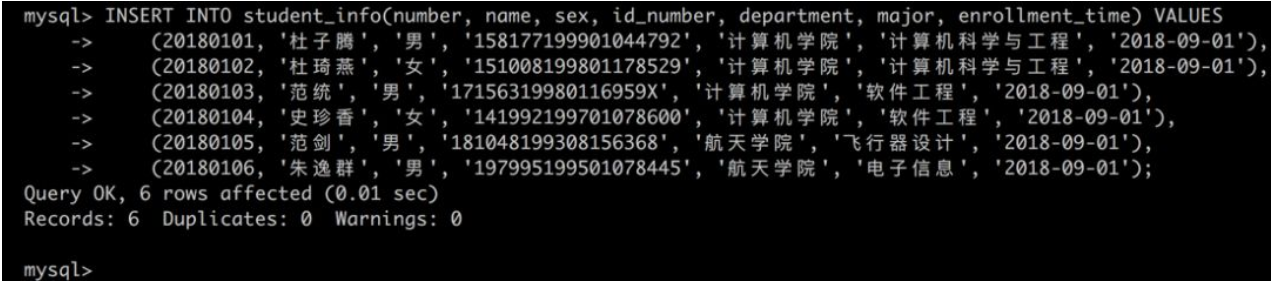
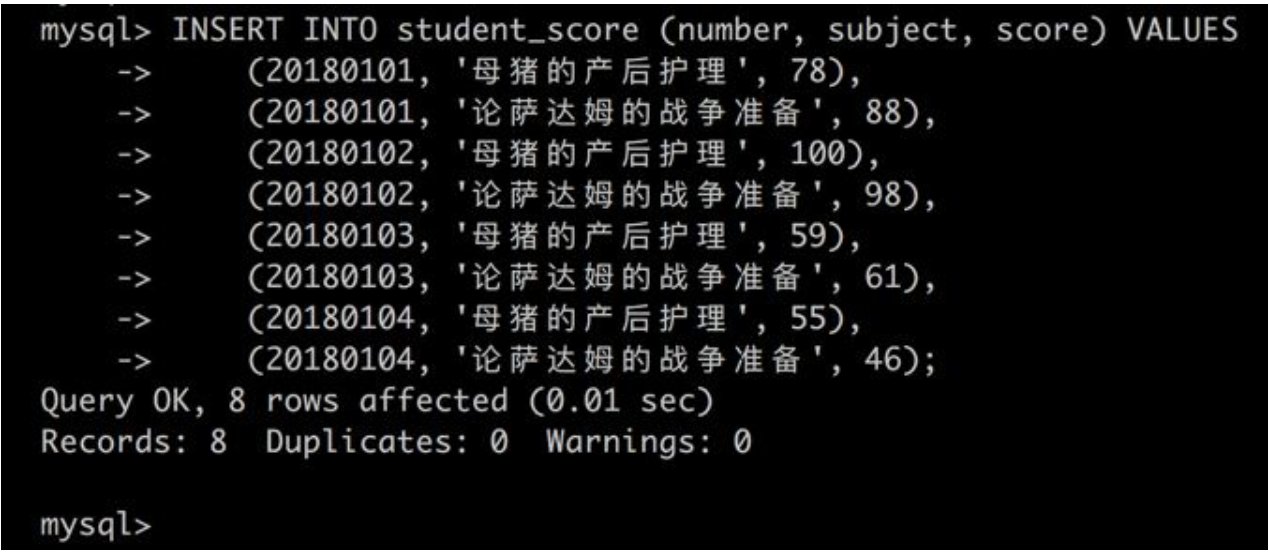
最终的结果是这样的:
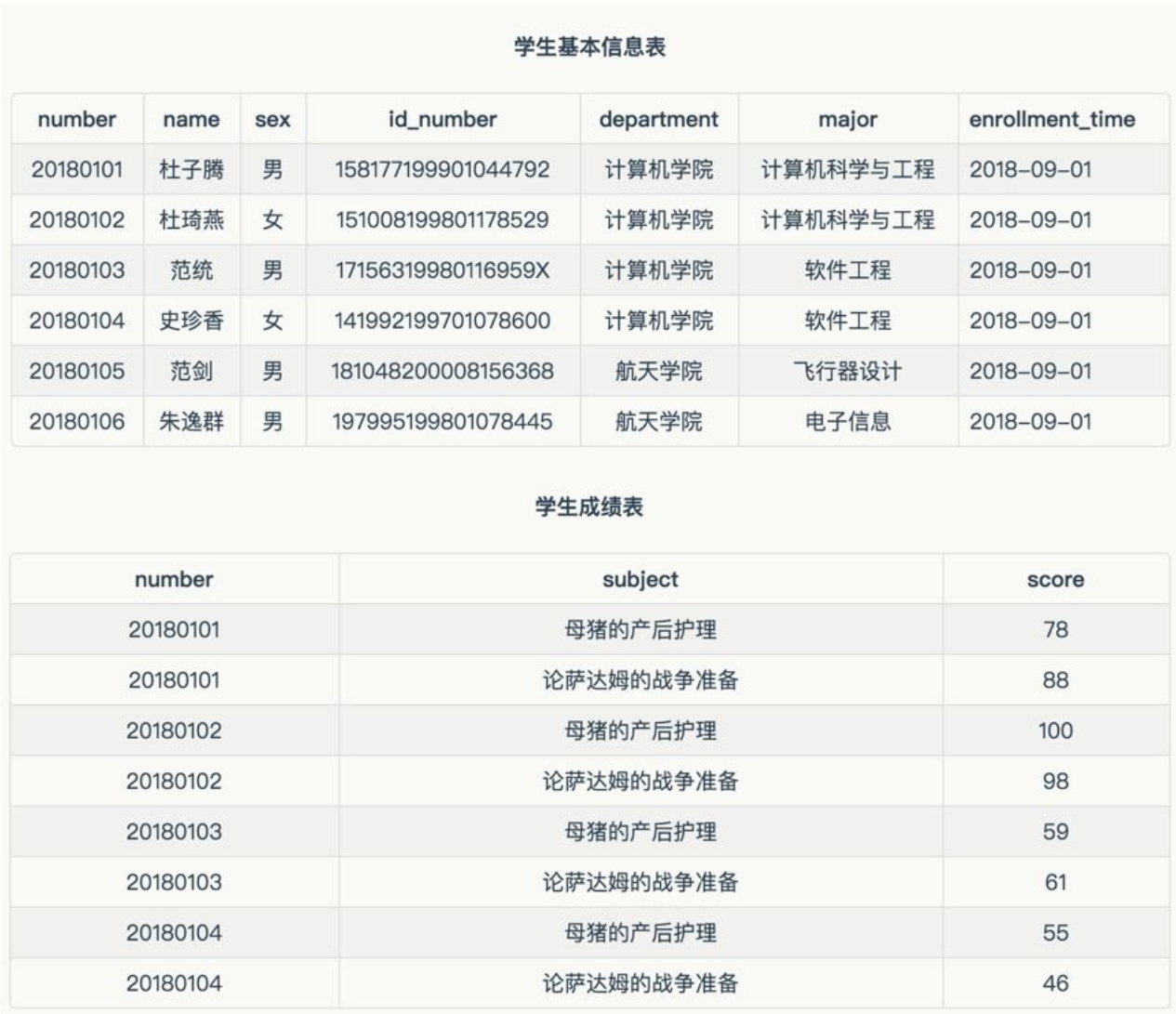
1.1.2常用操作
#去除单列重复结果
select distinct 列名 from 表名
#去除多列重复结果
delect distinct 列名1,列名2,...列名n from 表名;
#限制查询结果条数
limit 开始行,限制条数 (开始行是从0开始的,开始行不写默认为0)
#对查询结果进行排序
order by 列名 asc|desc (asc是升序,desc是降序,默认是升序的)
#按照多个列的值进行排序
order by 列名1 asc|desc,列名2 asc|desc;
order by和limit可以结合使用,并且order要放在前面
----------------------------------------------------------
############################过滤数据###################################
#简单搜索条件
where 后面加条件,条件操作符号又如下几种
等于 =
不等 !=
小于 <
不大于 <=
大于 >
不小于 >=
处于某个范围 between (例如:a处于b和c之间,a between b and c)
不处于某个范围 not between (例如a不处于b和c之间,a not between b and c)
#多值匹配
包含
where 某列 in (值1,值2);
不包含
where 某列 not in (值1,值2);
#NULL值检查
a is NULL a值为NULL;
a is not NULL a值不为NULL;
ps:这里判断是否为NULL不能用'='来判断
#多个搜索条件
条件与:
条件a and 条件b
条件或:
条件a or 条件b
当and和or同时使用时,注意and的优先级比or高,可以结合()来写查询逻辑
#通配符
模糊查询:
like: a like b (a匹配b)
not like:a not like b (a不匹配b)
模糊查询需要用到通配符,常用通配符如下:
% 表示任意一个字符串
_ 表示任意一个字符
\_ 转意通配符,将_转意成普通的字符串
--------------------------------------------------------------------
#########################表达式和函数##############################
#文本处理函数
left('abc123',3) abc
right('abc123',3) 123
length('abc') 3
lower('ABC') abc
upper('abc') ABC
ltrim(' abc') abc 将左边的空格去掉返回字符串
rtrim('abc ') abc 将右边的空格去掉返回字符串
substring('abc123',2,3) bc1 返回指定的字符串从指定位置截取指定长度的子串
concat('abc','123','xyz') abc123xyz 将给定的各个字符串参数拼接成一个新的字符串
#日期和时间处理函数
now() 当前日期和时间
curdate() 返回当前日期
date('2018-02-28 09:24:10') 将给定的时间值得日期提取出来
date_add('时间','时间间隔') 给日期添加指定的时间间隔
date_sub('时间’,'时间间隔') 给日期减少指定的时间间隔
datediff('time1','time2') 返回两个日期之间的天数
date_format('time','%m-%d-%Y) 将指定的时间转换成特定格式
#数学处理函数
abs(-1) 1 返回绝对值
pi() 3.141593 返回圆周率
cos() 余弦值
exp(1) 返回e的指定次方
mod(5,2) 1 取余数
rand() 返回一个随机数
sin() 正弦值
sqrt(9) 3 返回一个数的平方根
tan() 返回正切值
#聚集函数
count(column1) 返回一共有几列,忽略null的列,count(*)不会忽略null的列
max() 返回某列的最大值
min() 返回某列的最小值
sum() 返回某一列值之和
avg() 返回某一列得平均值
#分组
group by 列名
eg:select subject,avg(score) from student_info group by subject;
ps:非分组列不能出现在查询语句中
带有where字句的分组
select subject,avg(score) from student_score where score >=60 group by subject;
having max(score) > 98 过滤分组后的数据
分组注意的地方:
如果分组列中含有NULL,那么NULL也会作为一个独立的分组存在
如果查询语句中存在where字句之后,order by子句必须出现在where字句之后
非分组列不能单独出现在检索列表中(可以被放到聚集函数中)。
GROUP BY子句后也可以跟随表达式(但不能是聚集函数)。
查询子句的顺序要严格按下面顺序执行:
SELECT [DISTINCT] 查询列表
[FROM 表名]
[WHERE 布尔表达式]
[GROUP BY 分组列表 [HAVING 分组过滤条件] ]
[ORDER BY 排序列表]
[LIMIT 开始行, 限制条数]
-------------------------------------------------------------------
####################################标量子查询#######################
A查询语句作为B查询语句的条件,A查询语句为子查询
#in和not in子查询
子查询的查询结果有多个,要用in子查询,not in子查询用法也一样
select * from student_info where number in (select number from student_info where major in ='计算机学'
#exits和not exists
exists(select ...)当子查询有结果时表达式为真
not exists(select ...)当子查询没有结果时表达式为真
#相关子查询
select number,name,id_number,major from student_info where exists (select * from student_score where student_score.number = student_info.number)
#对同一个表的子查询
查询一个表中有哪些列大于平均值,下面这样写是错误的:
select * from student_score where subject = '母猪的产后护理' and score > avg(score);
聚合函数avg(score)不能用在where后面,应该用子查询:
select * from student_score where subject = '母猪的产后护理' and score >(select avg(score) from student_score where subject = '母猪的产后护理');
--------------------------------------------------------------------
##################################连接查询#############################
先简单建两个表:
表1:create table t1 (m1 int,n1 char(1));
插入数据:INSERT INTO t1 VALUES(1, 'a'), (2, 'b'), (3, 'c');
表2:create table t2 (m2 int, n2 char(1));
插入数据:INSERT INTO t2 VALUES(2, 'b'), (3, 'c'), (4, 'd');
当执行select * from t1,t2;返回9个值笛尔卡积
#内连接 inner join
select * from t1 inner join t2 where t1.m1 = t2.m2;
外连接:即使某条记录在另一个表中没有任意一条记录与它相匹配,它也能被加入结果集中的连接查询被称为外连接
#左外连接
select 查询列表 from 表1 left join 表2 on 连接条件
保留表1的值,即使没有匹配,而表2的值只有匹配的才能输出
#右外连接
与左外连接的概念相似
外连接的注意事项:
1.外连接不能用where作为查询连接,要用on
2.有普通搜索条件优先级别更高
-----------------------------------------------------------
############################组合查询#########################
多个查询语句可以用union合并起来
union all 多张表查询,重复也列出来,union默认把重复的行合并
#对组合查询进行排序
select m1,n1 from t1 union select m2, n2 from t2 order by m1 desc
注意不能单个用order by
合并查询注意事项:
1.被合并的各个查询的对象个数必须相同
select m1 from t1 union select m2,n2 from t2;这样会报错
2.查询的结果集中显示的列名将以第一个查询中的列名为准
3.各个查询语句中的查询列表的类型兼容就可以(也就是说不必完全相同)。
明天计划的事情
1.上面的格式只是简单地做了个记录,官网这里的编辑器太垃圾了,明天或许会整理下上面的内容发到简书上面去。
2.继续学一下权限管理这一块。
遇到的问题
暂无
收获
如上




评论