发表于: 2018-06-10 23:57:33
2 856
今日完成:
1. 参考修真院线下报名贴(学习资料-线下报名-北京报名)中报名的格式,整理出业务模型,确定需要几个对象,每个对象的属性是什么,对象和对象之间的关系是一对一,还是一对多。
报名格式:
(一)姓名:
(二)QQ :
(三)修真类型:
(四)预计入学时间:
(五)毕业院校:
(六)线上学号:
(七)日报链接:
(八)立愿:
(九)指导师兄:
(十)渠道:
对象以及对象和属性之间的关系这一块没看的很明白,请教师兄吧还是。
2.下载并安装及配置Mysql 5.5
完成
3.载navicat,或者是Hedisql,连接Mysql,别问我navicat收费怎么办。
完成,收费的情况可以网上找教程注册码破解。
4.创建出来报名贴的业务表,并将表结构粘贴到日报中,对比之前师兄的表结构设计,看看有什么差别
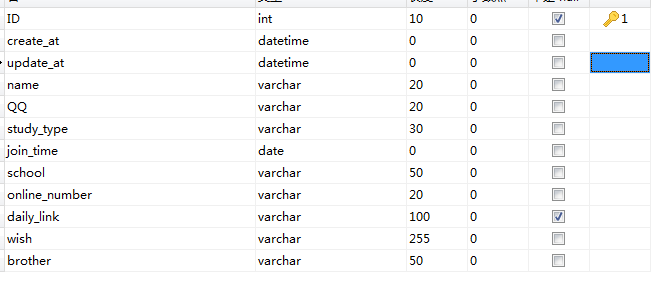
5.使用navicat设计mysql数据库,数据库的每一个表中都要有三个基本的字段,ID(自增Long),create_at,update_at(所有的时间都用Long)。 这一条没看明白,是把字段属性改成Long吗?
6. 从报名贴中找一条最近报名的师弟,用Mysql插入这条数据,并能够根据姓名查出来这条记录
插入语句: INSERT INTO `task1`.`task1_1` (`ID`, `create_at`, `update_at`, `name`, `QQ`, `study_type`, `join_time`, `school`, `online_number`, `daily_link`, `wish`, `brother`, `source`) VALUES ('1', '2018-06-10 11:20:51', '2018-06-10 11:20:56', '王庸之', '861684014', 'java工程师', '2018-04-27', '南京航空航天大学机电学院', 'JAVA-3834', 'http://www.jnshu.com/school/21289/daily', '破釜沉舟,破而后立', '宋尚', '知乎');
查找语句:SELECT * FROM task1.task1_1 WHERE name = "王庸之";
7. 分别用Navciat和Sql语句去将本条数据记录的报名宣言改成老大最帅
更新语句:UPDATE task1_1 SET wish = '老大最帅';
8.将表导出成Sql文件,并使用navciat和Sql分别尝试删除此条数据,并用之前备份的Sql恢复。
在命令行使用mysqldump -u dbuser -p dbname > dbname.sql导出数据库
在mysql数据库控制台mysql>source d:/dbname.sql导入数据库
9.给姓名建索引,思考一下还应该给哪些数据建索引
建立索引:create index index_name on task1.task1_1(name);
我觉得还可以给qq和在在线学号加上唯一索引
10.插入10条数据,查看有索引和无索引的情况下,Sql语句执行的效率 。
使用函数批量插入10条数据
在没有索引情况下:
在有索引情况下:
可以看出有索引的情况下会影响数据的插入速度。
11.查看深度思考中Mysql相关的一些问题,将自己思考的结果写在日报中,并查阅之前师兄的日报,看看是否有合自己思路接近或者是完全不一致的地方。
a. 自增ID有什么坏处?什么样的场景下不使用自增ID?
自增主键
这种方式是使用数据库提供的自增数值型字段作为自增主键,它的优点是:
(1)数据库自动编号,速度快,而且是增量增长,按顺序存放,对于检索非常有利;
(2)数字型,占用空间小,易排序,在程序中传递也方便;
(3)如果通过非系统增加记录时,可以不用指定该字段,不用担心主键重复问题。
其实它的缺点也就是来自其优点,缺点如下:
(1)因为自动增长,在手动要插入指定ID的记录时会显得麻烦,尤其是当系统与其它系统集成时,需要数据导入时,很难保证原系统的ID不发生主键冲突(前提是老系统也是数字型的)。特别是在新系统上线时,新旧系统并行存在,并且是异库异构的数据库的情况下,需要双向同步时,自增主键将是你的噩梦;
(2)在系统集成或割接时,如果新旧系统主键不同是数字型就会导致修改主键数据类型,这也会导致其它有外键关联的表的修改,后果同样很严重;
(3)若系统也是数字型的,在导入时,为了区分新老数据,可能想在老数据主键前统一加一个字符标识(例如“o”,old)来表示这是老数据,那么自动增长的数字型又面临一个挑战。
总结:自增主键两个坏处。第一是当新旧系统合并的时候会造成主键冲突。第二是当删除其中一条数据的时候其ID主键会为空,无法保持记录的连续性。
b.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
索引是一种数据结构,一般是Btree。类似图书的目录,可以通过查找目录快速查到我们想要的内容。在几万的数据量的情况下会有性能的差别。应该在频繁读取的字段建立索引。
c.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
区别是唯一索引的字段值不可重复。注意的是唯一索引的值可以是空值。在where查找字段可以建立唯一索引。
d.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
不需要,唯一索引可以排除重复
e.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
分别在创建这条数据和更新这条数据的时候以当时的时间值赋值。不应该开放给外部调用接口。
f.修真类型应该是直接存储Varchar,还是应该存储int?
int可以提高查询速度,需要使用数字映射字符串
g.varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
varchar后面的数字表示的字节,一个汉字是两个字节长度。代表的是不定长,多余的用空格补足。
text的长度为存放最大长度为 65,535 个字符的字符串。
longtext存放最大长度为 4,294,967,295 个字符的字符串。
h.怎么进行分页数据的查询,如何判断是否有下一页?
使用limit来精确查找部分结果。
i.为什么不可以用Select * from table?
会查找所有列影响查询效率,可以改为使用count(0)
12.下载Java 7,并配置环境变量,百度搜索一下JDK和JRE的区别,并将结论用自己的话写在日报中。
jdk是面向开发人员使用的SDK,它提供了java的开发环境和运行环境。jre是java的运行环境,面向java的使用者。jdk包括了jre。
13.下载Maven3,并配置好环境变量。
完成
14.下载Eclipse或者是IDEA,配置好Maven。IDEA不用配置Maven,Eclipse也分自带或者外部,推荐使用外部Maven。
完成
15.创建一个新的maven项目
完成




评论