发表于: 2018-04-25 22:24:24
1 603
今天完成的任务:
由于之前使用spring注解一直看不到输出,今天终于自己写了一个缓存读取和输出:
package memcached;
import net.rubyeye.xmemcached.MemcachedClient;
import net.rubyeye.xmemcached.exception.MemcachedException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeoutException;
@Component
public class CacheManager {
@Autowired
MemcachedClient memcachedClient;
public <T> T get(String key) {
T t = null;
try {
t = memcachedClient.get(key, 3000L);
} catch (TimeoutException | InterruptedException | MemcachedException e) {
e.printStackTrace();
}
return t;
}
public void add(String key, Object data) {
try {
if (memcachedClient.set(key, 60 * 30, data))
return;
} catch (TimeoutException | InterruptedException | MemcachedException e) {
e.printStackTrace();
}
}
}
配置文件还是需要一个工厂化实例的配置和连接池以及链接端口配置,如下:
<!--Xmemcached配置-->
<bean id="memcachedClientBuilder" class="net.rubyeye.xmemcached.XMemcachedClientBuilder">
<property name="connectionPoolSize" value="10"/>
<property name="failureMode" value="true"/>
<constructor-arg>
<list>
<bean class="java.net.InetSocketAddress">
<constructor-arg value="127.0.0.1"/>
<constructor-arg value="11211"/>
</bean>
</list>
</constructor-arg>
<!-- BinaryCommandFactory -->
<property name="commandFactory">
<bean class="net.rubyeye.xmemcached.command.TextCommandFactory"/>
</property>
<property name="sessionLocator">
<bean class="net.rubyeye.xmemcached.impl.KetamaMemcachedSessionLocator"/>
</property>
<property name="transcoder">
<bean class="net.rubyeye.xmemcached.transcoders.SerializingTranscoder" />
</property>
</bean>
<!-- 使用工厂模式获得客户端实例 -->
<bean id="memcachedClient" factory-bean="memcachedClientBuilder"
factory-method="build" destroy-method="shutdown" />
因为要测乱码问题,然后做了一下控制台的输出检查:
@Override
public Integer gettotal(){
Integer total ;
if((total=cacheManager.get("total"))!=null){
System.out.print("读取缓存:"+total);return total;
}
else
{
total=studentMapper.gettotal();
cacheManager.add("total",total);
System.out.print("增加缓存:"+total);
return total;
}
}
可以看到确实是读取到了非乱码的int类型数据:
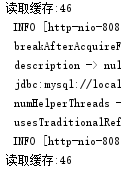
然后以为这样就可以了,结果去看memcached:
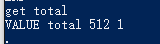
还是乱码,起码知道问题在哪里了,这两天在这个问题纠结太久了,今天赶赶进度,昨天没提交任务5是因为github合并没过去。
今天遇到的问题:
使用缓存之后关闭tomcat会报错缓存泄露:

还有那个乱码问题,今天继续解决这两个问题
今天的收获:
memcached的一些注意事项:
1.key-value的限制
缓存的key有长度限制,key的组成有特定字符的限制。
缓存的value必须可以序列化,且缓存的单一value容量有大小限制,对于可序列化的value,应该想方设法尽量规避某些特定数据结构,比如Hashtable,DataTable这些内部其实非常非常之复杂的数据结构。对于读频繁的操作来说,每次序列化和反序列化复杂数据结构的开销可想而知。
如果连分布式缓存的key和value(尤其是value)的一般限制都搞错了,那么使用缓存的后果很可能只是白白增加了网络IO及序列化、反序列化的开销,对系统性能提升当然是巨大的反作用。
2、小心Memcached的.net客户端的误用
这一点隐藏的也比较深,下面以应用广泛的EnyimMemcached为例来简单说明。
通常我们使用的客户端每次实例化MemcachedClient对象内部都会初始化一个客户端对象池(TCP连接池,客户端命名为ServerPool)。所谓TCP连接池就是将创建好的TCP连接(连接数通常按照配置来,生产环境的配置不会小于两位数)初始化放在容器内,客户端调用的时候可以直接拿出已经存在的TCP连接来用,这样可以省去实时打开TCP连接的开销。
因为有人喜欢using一下(当然包括楼主自己了),一看到MemcachedClient是继承自IDisposable的,必须用using啊,然后就要new一个MemcachedClient对象,这样客户端内部也就不得不再初始化一个TCP连接池。如果某个使用缓存的服务方法调用频繁,很快你就会发现系统CPU飙升,页面打开速度奇慢,直至不能正常访问。
我们知道,分布式缓存系统都有一个TCP连接上限的设置,无论如何,超过这个上限都有可能引发连环反应,这种反应毫无疑问是不良副作用。
所以如果我们误用MemcachedClient,每次都new一个对象,那么高并发情况下效果就非常惨了,一方面web服务器因为TCP连接过多无法正常访问,另一方面Memcached服务器也因为连接太多负载过重而性能变得极差,依赖Memcached的服务很可能短时间内只接收到超时响应。
解决方案无比简单,配置合适的TCP连接数,MemcachedClient对象单例即可。
3.适合缓存的数据通常应该对外公开供(所有)人调用,私有的数据缓存多数情况下是没有意义的
4.对准确性、实时性、安全性等要求极高的业务数据,你的数据可能不适合缓存
泛型的使用:
以前一直用object,有的时候需要类型的强制转换,泛型可以避免我们遇到类型转换这些问题。
明日计划:
解决问题、继续学习
PS:早上更新一发 问题大概解决了:
现在问题来了,好多人会发现,在反序列化程序中运行后能够正常输出Person的相关信息,但是在目录下的文件“person.obj”用文本编辑器打开之后却是乱码的。这是为什么呢?是不是因为写出去的编码和文本编辑器的默认编码采用了不一样的字符集?然后我们就开始想怎么能够将二者的编码格式设为一致的。
其实,这么想一开始就是错误的。为什么这么说呢,因为序列化和反序列化都是基于二进制流的,也就是说,在第二步中,其实就是将person的相关信息转化为二进制存储在了person.obj这个文件中,那么用文本编辑器打开查看的话当然是会出现乱码的。只有通过反序列化才能将存储的二进制读取出来,然后正常显示在控制台上。

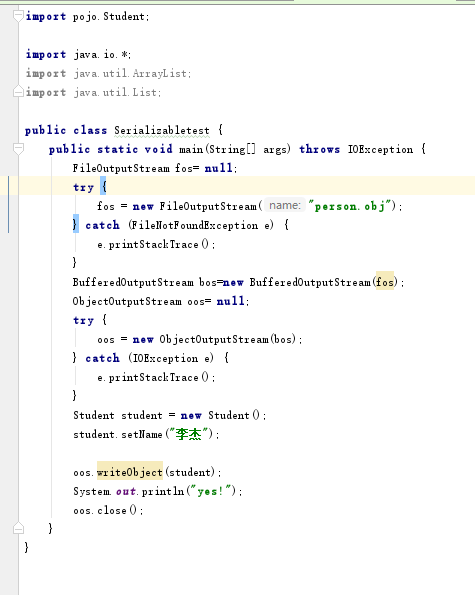
大概原因就是上面所说的,其实直接读取是读不到序列化过后的数据的?读出来大概只能是乱码,再附上可视化工具上面的:
value里面的数据不显示结果,只显示了已序列化的对象,现在问题已经基本解决,继续写代码去咯。




评论