发表于: 2018-04-18 20:38:49
2 856
今天完成的事情:今天深入得学习了一下爬虫 感觉比自己想象中得要难,对小小白很不友好。网上方法太多,从Python2.7到Python3 各种模块 各种解析器 各种教程,还没有找到合适得教程。
不过倒是在找到合适得教程中,把HTTP协议工作原理理解了。
明天计划的事情:学习爬虫 复习Python得字典
遇到的问题:爬虫学习的很慢,效率不高,感受到了从入门到放弃。
收获:
HTTP协议工作原理(个人理解):
客户端:发送请求到服务器
服务器:接受请求 报文给客户端
服务器:发送响应 报文给客户端
客户端:处理接收到的内容
爬虫核心模块:
请求——解析——储存
请求:
这里我们使用的package是requests。这是一个第三方模块,对HTTP协议进行了高度封装,非常好用。
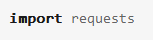
导入requests
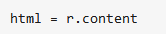
下面调用requests的get函数,把网页请求下来:

返回的“r”的是一个包含了整个HTTP协议需要的各种各样的东西的对象。
解析:
用bs4来解析。bs4是一个非常好的解析网页的库
package:目录 包
导入package

创建一个BeautifulSoup对象


这里我们使用了BeautifulSoup对象的find方法。这个方法的意思是找到带有‘div’这个标签并且参数包含" class = 'people_list' "的HTML代码。如果有多个的话,find方法就取第一个
取出所有的“a”标签里面的内容


使用BeautifulSoup支持的方法,使用类似于Python字典索引的方式把“a”标签里面“href”参数的值提取出来,赋值给url(Python实际上是对对象的引用),用get_text()方法把标签里面的文字提起出来
储存

使用print关键词把得到的数据print出来
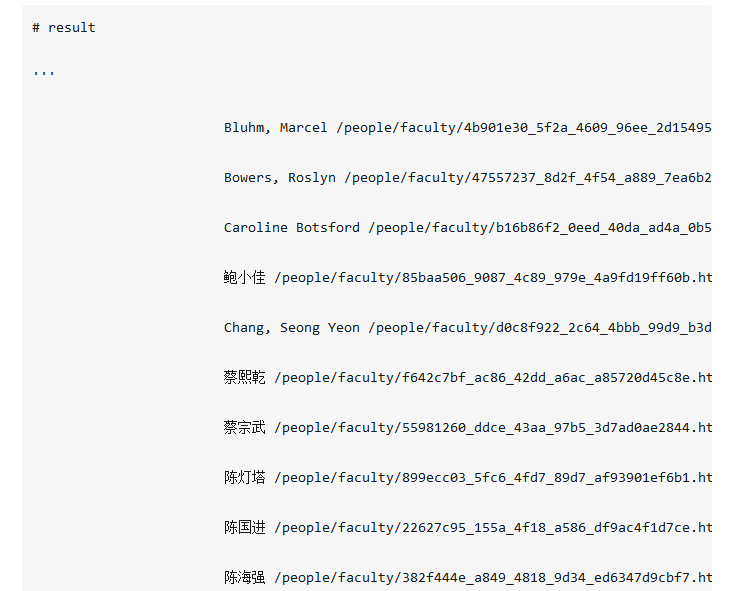
这就是一个非常简单的爬虫,总代码不过十几行。复杂到几百几千行的爬虫,都是在这样的一个原型的基础上不断深化、不断完善得到的。




评论