发表于: 2018-04-17 20:13:53
1 842
今天完成的事情:学习了爬虫 成功的完成了爬虫将网上的图片下载到硬盘的过程(虽然是复制粘贴的)
明天计划的事情:完成简单的爬虫 自己敲出代码 成功爬虫
遇到的问题:关于HTML和XML的语法印象不是很深,需要加强。爬虫大概流程清楚了,还需自己努力爬。这两天吸收内容太多,脑容量不够。
收获:
爬虫流程:发送请求——获得页面——解析页面——下载内容——储存内容
爬虫开头代码:
from bs4 import BeautifulSoup
import requests
import os
import#载入模块
requests#获取源代码
import requests#载入获取网页模块
BeautifulSoup#从网页提取数据的Python,包括在bs4模块中
from bs4 import BeautifulSoup#从bs4模块中载入BeautifulSoup模块
OS模块#保存获取到的图片
Url = “网址” #变量 右边赋予左边值
Url_get = requests.get(url) #变量 右边赋予左边值
print(Url_get.text) # 加text获取网页源代码
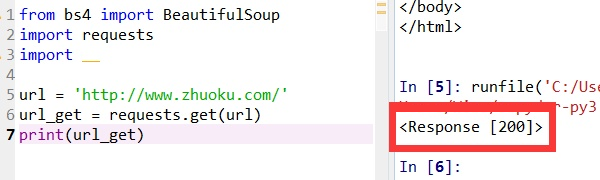 #不加text返回状态码
#不加text返回状态码
XYQ7GZHK.png)
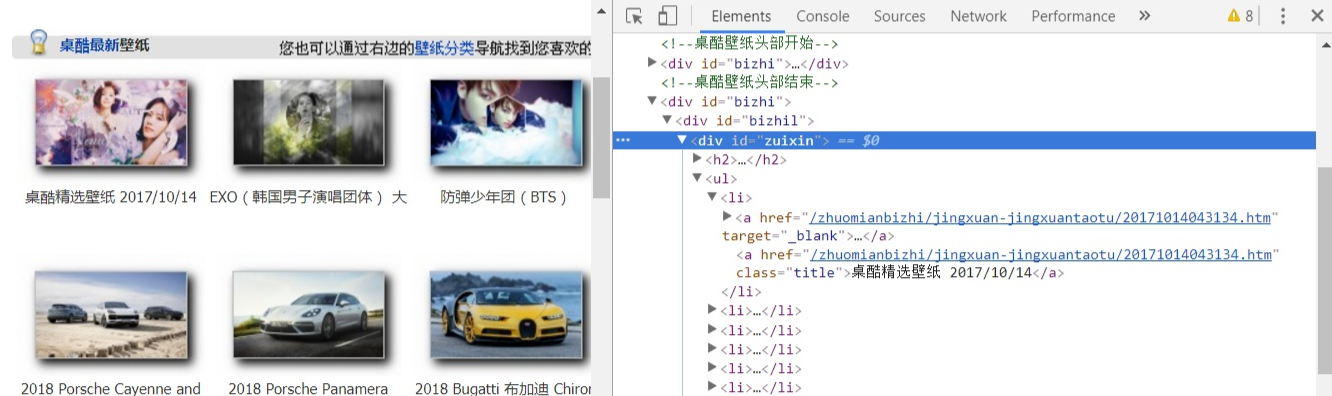
url_soup = BeautifulSoup(url_get,'html.parser')
all_a = url_soup.find('div',id="zuixin").find_all('a',attrs={"class":"title"})
for a in all_a:
print(a)




评论