发表于: 2018-04-09 11:08:39
1 858
day12
今天完成的事情:
1. 继续测试批处理
PreparedStatement pstat = con.prepareStatement(sql);
// 模拟数据
for (int i=0; i<1000000; i++) {
pstat.setString(1, "空见法师"+i);
pstat.setString(2, "男");
pstat.setString(3, "108");
if(i % 50000 == 0){
pstat.addBatch();
pstat.executeBatch();
}
}
pstat.executeBatch();
pstat.clearBatch();
pstat.close();
con.close();
在跑了以上代码后,我开心的发现自己的插100万条数据只要4秒,并兴奋的告诉了周围人,后来在数据库执行SELECT COUNT(*) FROM table1;查出来的数据才20条!!
我仔细检查了代码,发现了错误,上面判断能被5万整除才添加一次批处理,而100万刚好是5万的20倍数,所以数据库只有20条数据。这个错误真的是,唉。
每一条记录只有.addBatch()后才会放进批处理中,放完一定量后再
pstat.executeBatch(); 执行批处理
pstat.clearBatch(); 清空批处理
进入正式测试,100万数据插入
100万整个一批 27s
50万 26s
20万 28
10万 19s
5万一批处理 18s
1万 28s
5000 48s
由上面可知,批处理的速度跟每批处理数据量有关,每次处理太少会慢,但太高也不好,经过上面的测试对于100万的插入每批10万或5万最佳。
然后测试插入1000万条数据。用时192s
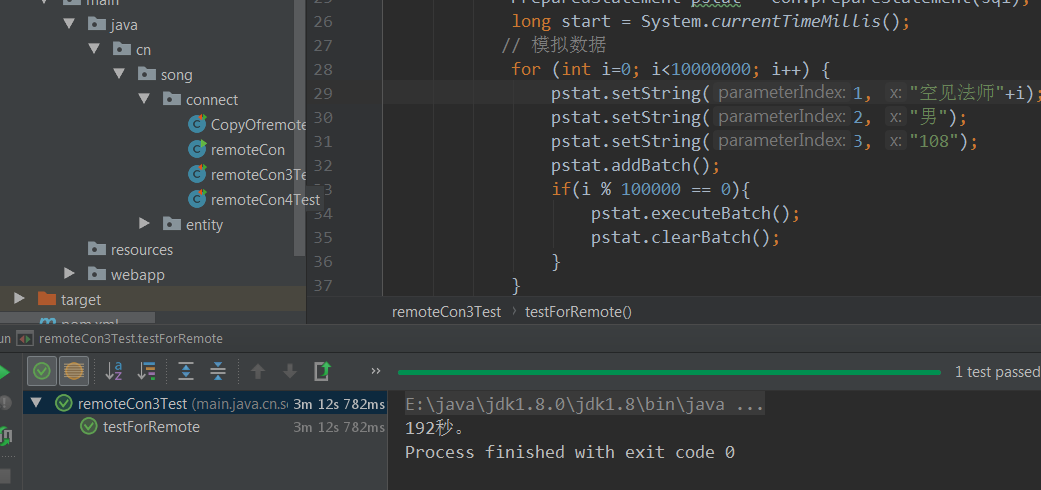
代码如下
@Test
public void testForRemote() throws Exception {
try {
String sql = "INSERT INTO table1(NAME,gender,age) VALUES(?,?,?)";
Connection con = null;
//加载驱动
Class.forName("com.mysql.jdbc.Driver");
con = DriverManager.getConnection("jdbc:mysql://39.107.247.104:3306/Jnshu1?useUnicode=true&"+
"characterEncoding=utf-8&useSSL=false&rewriteBatchedStatements=true",
"root","123456xyz");
PreparedStatement pstat = con.prepareStatement(sql);
long start = System.currentTimeMillis();
// 模拟数据
for (int i=0; i<10000000; i++) {
pstat.setString(1, "空见法师"+i);
pstat.setString(2, "男");
pstat.setString(3, "108");
pstat.addBatch();
if(i % 100000 == 0){
pstat.executeBatch();
pstat.clearBatch();
}
}
pstat.executeBatch();
pstat.clearBatch();
long end = System.currentTimeMillis();
pstat.close();
con.close();
System.out.print((end-start)/1000+"秒。");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
2.生成随机数、随机字母随机汉字
public void testForRemote2() throws Exception {
//(int)(Math.Random()*n) 可以得到一个0到n范围的随机数。
//产生一个大于等于0到小于1的double型随机数
double d = Math.random();
//乘以10然后再强转为int,转为int后会将小数部分弃掉,不是四舍五入
System.out.println((int)(d*10)+" and "+ d);
//以下代码可以生成随机的字符
/**
* 'z'-'a'=25,Math.random()产生的是0到1的小数[0,1),乘以26得到的是[0,26)的double
* 然后'a'的ASCII码表对应的是97,加上[0,26)的double得到[97,123)的double,但是自动舍弃小数部 分。
* 从而的到了a到z的码表值。
*/
char ca = (char)('a'+Math.random()*('z'-'a'+1));
System.out.println(ca);
/**
* 汉字的unicode范围是:0x4E00~0x9FA5。故可通过以下代码生成随机汉字
*(char) (0x4e00 + (int) (Math.random() * (0x9fa5 - 0x4e00 + 1)))
* 其实不用int强转,后面的char强转会弃掉后面的小数位
*/
System.out.println((char) (0x4e00 + (Math.random() * (0x9fa5 - 0x4e00 + 1))));
}
3.使用新学的随机函数,制造100万个不同的个人信息。
他们的姓名不同,因为我设定的三个随机汉字,顾不上遵守百家姓的规则了
他们的性别也是随机的 '男' 或 '女' ,我还分配了 ‘人妖’这一性别,尽在程序出错是出现
它们的qq号我用的10位随机数模拟,年龄也是两位的随机数来模拟。代码如下
@Test
public void testForRemote() throws Exception {
try {
String sql = "INSERT INTO table1(NAME,gender,age,qq) VALUES(?,?,?,?)";
Connection con = null;
//加载驱动
Class.forName("com.mysql.jdbc.Driver");
con = DriverManager.getConnection("jdbc:mysql://39.107.247.104:3306/Jnshu1?useUnicode=true&"+
"characterEncoding=utf-8&useSSL=false&rewriteBatchedStatements=true",
"root","123456xyz");
PreparedStatement pstat = con.prepareStatement(sql);
list2 = getPersonWithArg();
System.out.println(list2.size());
long start = System.currentTimeMillis();
for (int i=0; i<list2.size(); i++) {
Person person = list2.get(i);
pstat.setString(1, person.getNAME());
pstat.setString(2, person.getGender());
pstat.setString(3, person.getAge());
pstat.setString(4, person.getQq());
pstat.addBatch();
if(i % 100000 == 0){
pstat.executeBatch();
pstat.clearBatch();
}
}
pstat.executeBatch();
pstat.clearBatch();
long end = System.currentTimeMillis();
pstat.close();
con.close();
System.out.print((end-start)/1000+"秒。");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
// 模拟数据
public List<Person> getPersonWithArg(){
for (int r = 0; r < 1000000 ; r++) {
String qq = "";
String sex = "";
String age = "";
String name = "";
Person person = new Person();
//生成3个随机汉字来模拟姓名
for (int i = 0; i < 3; i++)
name += (char) (0x4e00 + (Math.random() * (0x9fa5 - 0x4e00 + 1)));
}
person.setNAME(name);
//性别
int sexf = (int)Math.random() * 2;
if(sexf==0){
sex = "男";
}else if( sexf == 1){
sex = "女";
}else {
sex = "人妖";
}
person.setGender(sex);
//年龄
int d;
for (int i = 0; i < 2; i++) {
d = (int)(Math.random()*10);
age += d;
}
person.setAge(age);
int j;
for (int i = 0; i < 10; i++) {
d = (int)(Math.random()*10);
qq += d;
}
person.setQq(qq);
list.add(person);
}
return list;
}
最终结果数据库里出现了100万个各不相同的个人信息(模拟)。由于姓名是随机的汉字,而全体汉字中其实大部分都是繁体字,所以可以看到姓名都是那样的,注意,那不是乱码。
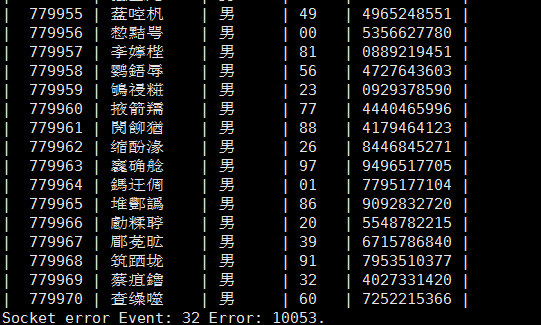
用时20秒,偶尔抽风会飙到40秒。但多次测试是20秒。

小课堂:
String 字符串常量
StringBuffer 字符串变量(线程安全)
StringBuilder 字符串变量(非线程安全)
简要的说, String 类型和 StringBuffer 类型的主要性能区别其实在于 String 是不可变的对象, 因此在每次对 String 类型进行改变的时候其实都等同于生成了一个新的 String 对象,然后将指针指向新的 String 对象,所以经常改变内容的字符串最好不要用 String ,因为每次生成对 象都会对系统性能产生影响,特别当内存中无引用对象多了以后, JVM 的 GC 就会开始工作,那速度是一定会相当慢的。
而如果是使用 StringBuffer 类则结果就不一样了,每次结果都会对 StringBuffer 对象本身进行操作,
而不是生成新的对象,再改变对象引用。所以在一般情况下我们推荐使用 StringBuffer ,特别
是字符串对象经常改变的情况下。
例:
String S1 = “This is only a” + “ simple” + “ test”;
StringBuffer Sb = new StringBuilder(“This is only a”).append(“ simple”).append(“ test”);
明天计划的事情:
1.再用框架测试数据插入
2.maven在服务器跑一遍
遇到的问题:
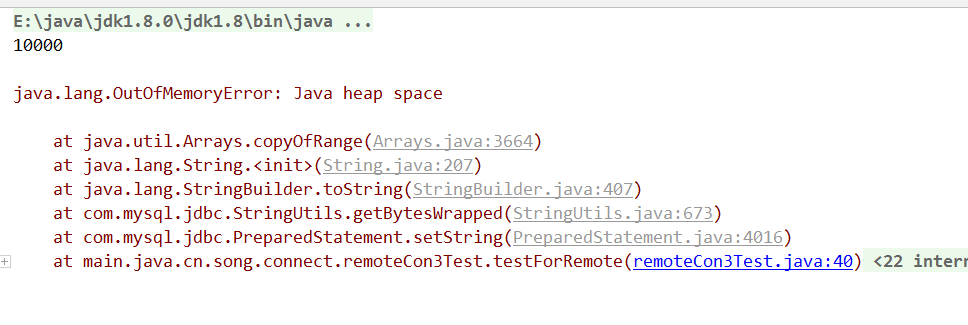
1. 在用随机信息填充数据库时,发生了内存溢出的报错,执行以下代码导致内存溢出
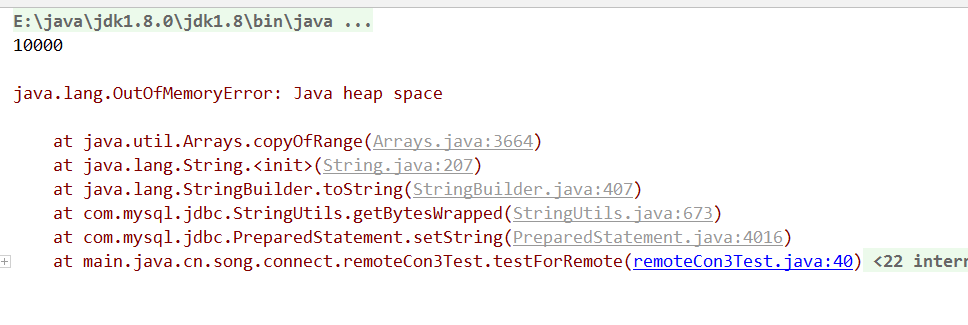
现在想想,应该是太多的字符串修改用了String而没有用StringBuffer,100万的数据没对字符串修改一次就多一个指针,光3个汉字就要出来300万没用的字符串指针,所以这种频繁操作字符串场景要用StringBuffer。
2.在插入完数据后,出现了第一个姓名3个汉字,第二个6个,第三个9个......还有qq、年龄等如下图
正常的该是这样的,分别是id、name、gender、age、qq 字段。
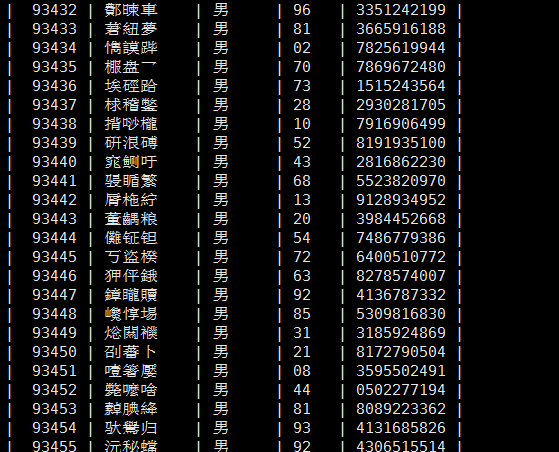
可却出现了这样的情况:

越到后面越会发生雪崩,插100万更不得了。

最终找到了问题原因,可先看我下面代码,错误处已被我标红
public List<Person> getPersonWithArg(){
Person person = new Person();
String qq = "";
String sex = "";
String age = "";
String name = "";
for (int r = 0; r < 50 ; r++) {
//生成3个随机汉字来模拟姓名
for (int i = 0; i < 3; i++) {
name += (char) (0x4e00 + (Math.random() * (0x9fa5 - 0x4e00 + 1)));
}
person.setNAME(name);
//性别
int sexf = (int)Math.random() * 2;
if(sexf==0){
sex = "男";
}else if( sexf == 1){
sex = "女";
}else {
sex = "人妖";
}
person.setGender(sex);
//年龄
int d;
for (int i = 0; i < 2; i++) {
d = (int)(Math.random()*10);
age += d;
}
person.setAge(age);
int j;
for (int i = 0; i < 10; i++) {
d = (int)(Math.random()*10);
qq += d;
}
person.setQq(qq);
list.add(person);
}
return list;
}
关于name、gender、age、qq 的字符串声明在了循环外面,意味着每一次循环后string内部的字符串没有被释放或置空,而是加在前面的内容上,于是出现了上图的效果,如果插100万条数据,那么第100万条数据的姓名将是300万字的姓名,好可怕。string在循环外声明,那么循环执行完后相当于在给它加了n个后缀,然后有set到了实体类的属性中。
3. 今天还发生了一个错误,这个错误是紧接着上一个的,当我乖乖把那四个String的声明放到了for循环体内后,插入完数据去看数据库,发现上一个问题解决了,但是还有一个问题。同样可以参考上面那段代码那个被我标绿的new Person()的声明,那个person对象同样声明在循环体外。首先字段内的信息不会叠加了,但是全部一样:
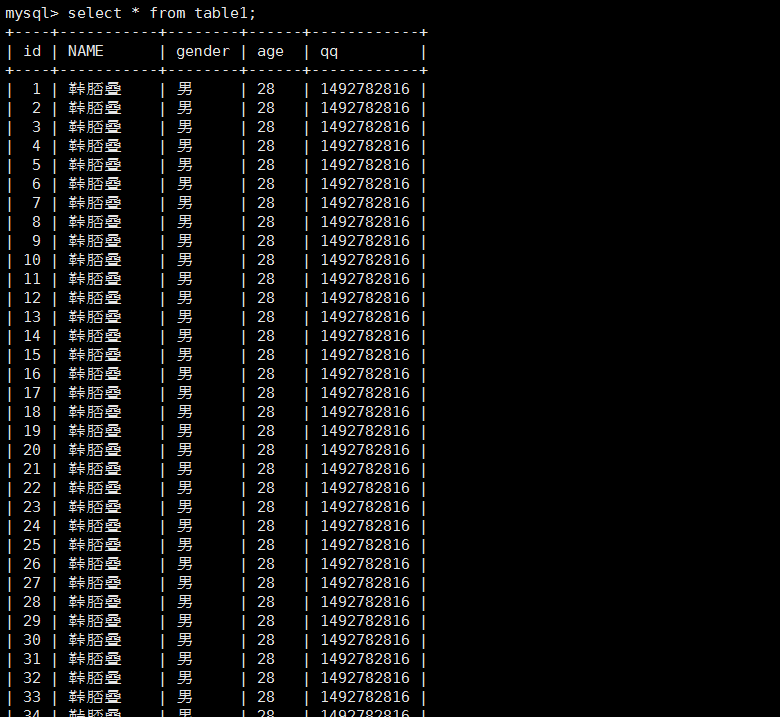
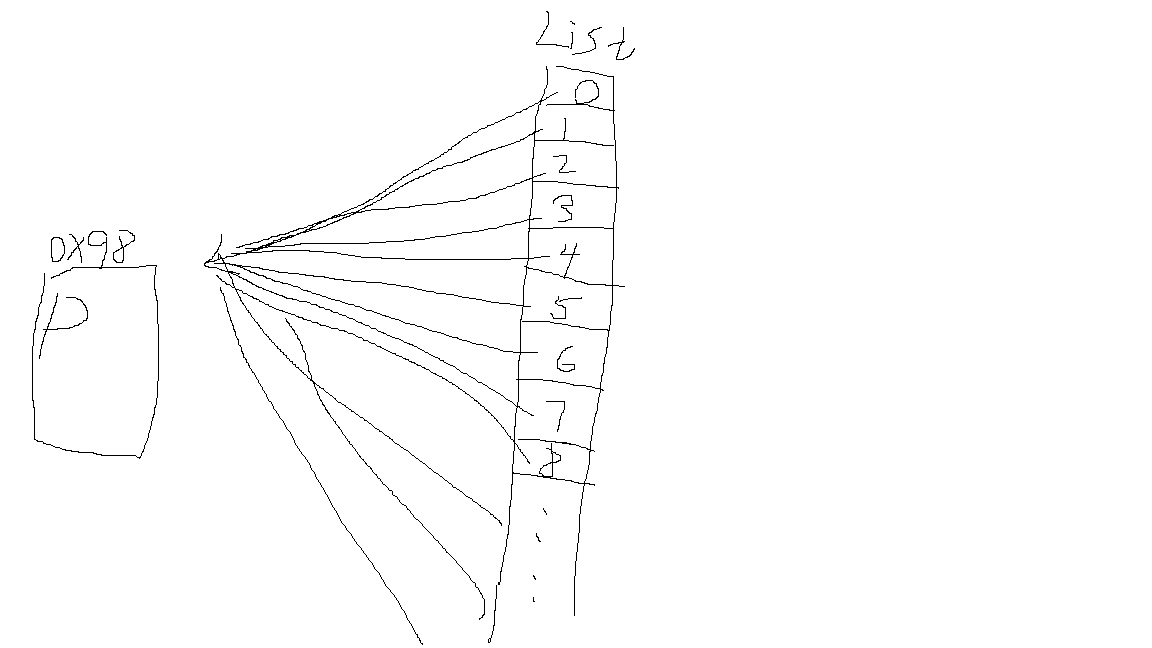
这个问题原因也在我不断调试中找到了,没错,就是因为person在循环外声明,也就是说这个方法内就一个person对象,虽然后面后 list.add(person) ,但不过以一个对象add 了一百万遍,更怪异的是数据库数据全一样,这就揭示了list的内部实现原理,首先我们知道每创一个对象就在内存中开辟了一块内存空间,然后声明一个变量可以指向它的首地址,同样list集合在add对象时,也是将建一个索引指向该对象的内存首地址,list每执行一次add ,就是将一个对象的地址加进来,最终由于list集合中的所有元素都是同一个per送的首地址,所以
,就是将一个对象的地址加进来,最终由于list集合中的所有元素都是同一个per送的首地址,所以 你get出来的都是一个,那么数据库里插入的信息自然都是一样的。那问题又来了,我前面循环了100万次,又给person对象set过100万次属性,数据库里的信息是哪一次的呢? 没错,就是最后一次的,最后一次会覆盖前面的值,所以上图中的信息是 "最后一个person" 的信息。不信?我们来演示下,很简单,将循环调到10次,然后把person和string的声明都放循环外面如下
你get出来的都是一个,那么数据库里插入的信息自然都是一样的。那问题又来了,我前面循环了100万次,又给person对象set过100万次属性,数据库里的信息是哪一次的呢? 没错,就是最后一次的,最后一次会覆盖前面的值,所以上图中的信息是 "最后一个person" 的信息。不信?我们来演示下,很简单,将循环调到10次,然后把person和string的声明都放循环外面如下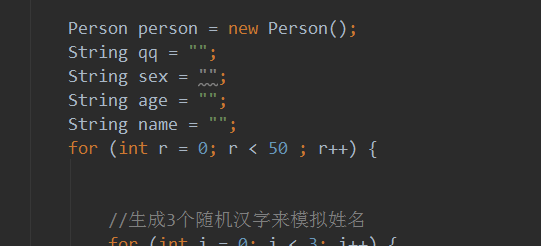
跑一次程序看看数据库如下,可以看到,姓名刚好 3*10 30个汉字
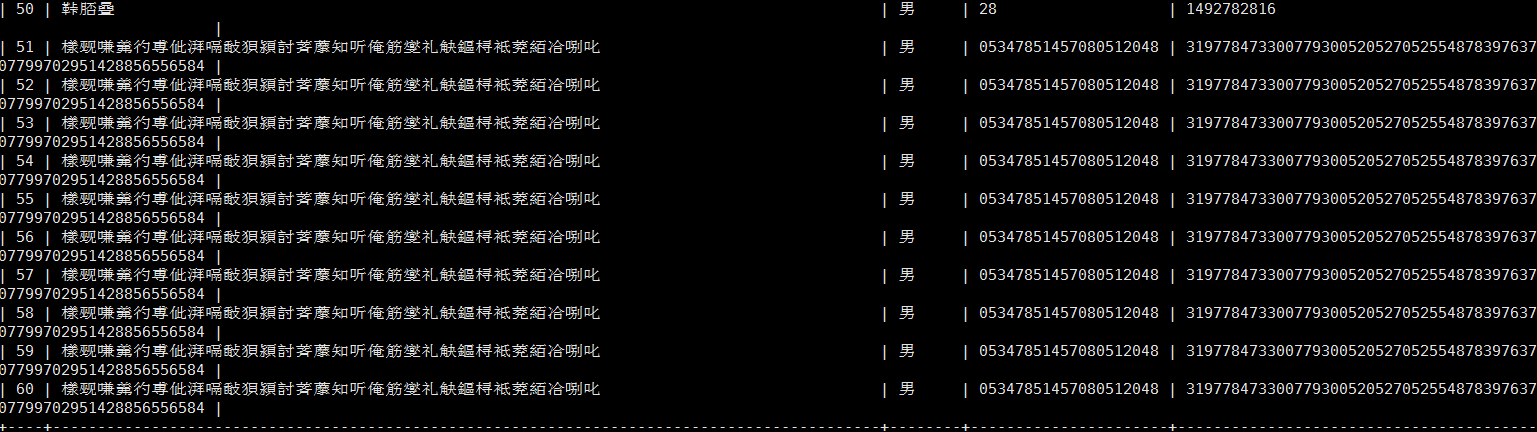
附一张我画的List集合所有元素执行一个对象示意图
收获:
凌晨四点钟,看到海棠花未眠




评论