发表于: 2018-04-06 10:33:09
1 695
今天完成的任务:
今天给数据库加了createtime和updatetime:


这两个数据不用展示给客户但是对维护数据库还是很重要的。
nginx实现了反向代理:

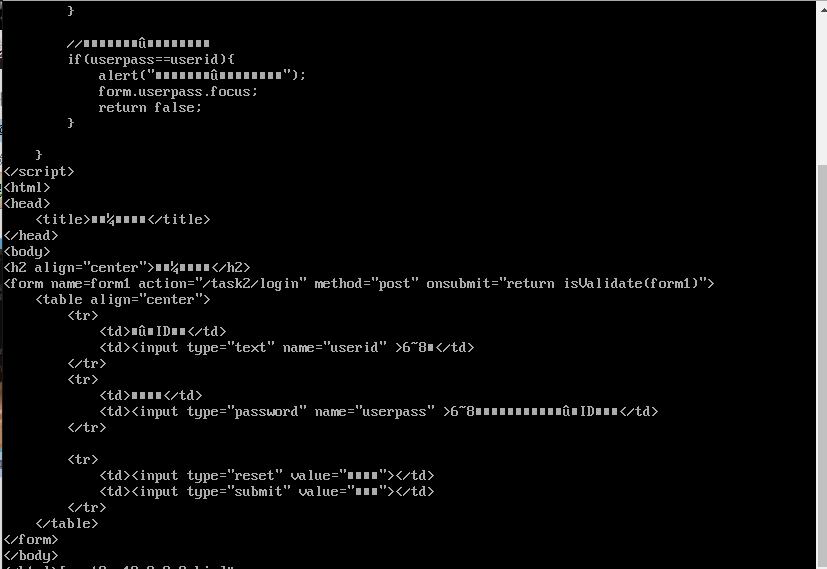
,动静分离就直接到任务4做吧还有负载均衡,之前把resin设置成开机自启动了,有点坑,现在改回来,想拿tomcat部署还得去把resin关掉。
本来可以做任务4的,但是还是想自己熟悉一下脚本,毕竟如果不写就一直不想写了,
grep:主要是对行操作
awk:主要是对列操作
sort:排序
大概是这么个区分,主要是学习了awk,按需学习,现阶段主要实现的是从日志文件中将列的信息提取出来做处理,比如nginx的log日志输出格式:
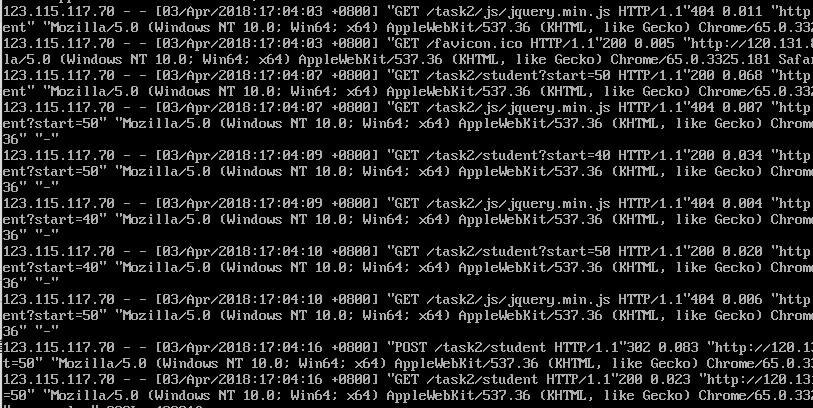
每行的输出格式都一样,只需要我们使用awk遍历每行然后用$选取第几个信息拿出来做处理即可。
1.awk基本使用语句:
awk '{pattern+action}' {filename}
pattern表示awk拿出的数据内容,action是对数据内容执行的命令,其中pattern部分寻找匹配数据可以用正则表达式完成。
2.awk调用方式
(1)awk [-F field-separator] 'commonds' input-file
commands中是awk真正执行的命令,-F是可选分隔符(默认是空格),后面是待处理文件。
(2) shell脚本调用awk命令
和#!/bin/sh类似 使用#!/bin/awk声明这是一个awk脚本
3.工作流程($域的含义)
直接拿之前的nginx输出的access.log举例,如果我们想提取每行的第一列数据(IP),那我们应该使用:
awk '{print $1}' access.log
这里直接在当前目录下找到的access.log,不用打绝对路径,如果想在脚本里面使用的话文件还是应该使用绝对路径,-F分隔符直接使用默认的空格,输出效果如下:
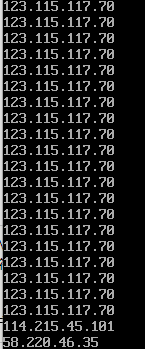
 注意日期之间的两个空格(我也不知道为啥nginx日志会输出两个空格),那么在默认分隔符是空格的情况下我们想选取日期就需要输入
注意日期之间的两个空格(我也不知道为啥nginx日志会输出两个空格),那么在默认分隔符是空格的情况下我们想选取日期就需要输入

效果如下:
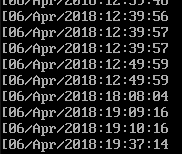
当然我们也可以同时提取多个信息,同时拿到IP和时间,中间用tab分割
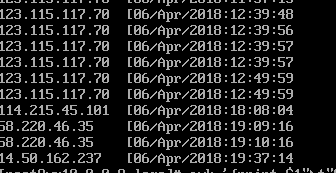
试试使用自己指定的分割符,使用-F '/'指定/为分隔符

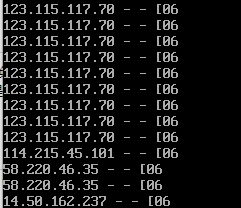
数据从06/Apr中间被分开
awk的工作原理:
awk在处理文本时也是一次读取一行文本,然后根据输入分隔符(默认为空格字符)进行切片,切成n个片段,然后将每一片都赋予awk内部的一个变量当中进行保存,这些变量名为$1,$2,$3...等等一直到最后一个,awk就可以对这些片段进行单独处理,比如显示某一段,特定段,甚至可以对某些片段进行额外的的加工处理,比如计数、运算等。
具体工作原理如下:
第一步:执行BEGIN{action;… }语句块中的语句;
·第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ action;… }语句块,它逐行扫描文件,从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
·第三步:当读至输入流末尾时,执行END{action;…}语句块
·BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中
·END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块
·pattern语句块中的通用命令是最重要的部分,也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块
4.awk的命令和变量
(1)print命令
print item1,item2,...输出的item可以是字符串,也可以是数值,当前记录的字段,变量或awk表达式。
(2)内置和自定义变量
FS:输入字段分隔符;
OFS:输出字段分隔符;
NF:字段数量;
NR:行号;
-v var = value 变量名区分字符大小写;
(3)printf也能输出,和print的区别同java语言类似,在此就不再多说
(4)操作符
这里的算术操作符、赋值操作符、模式匹配符、逻辑操作符等等其实也和java比较类似,而且更多可以用正则来判断,正则学的不好...
(5)pattern
根据pattern过滤匹配的行再进行处理(可以不用grep做行的筛选)
1)如果未指定,则awk会匹配每一行进行输出;
2)/regular expressin/:仅处理能够模式匹配到的行,需要用/..../表示,例如:
awk ‘ /abc/ {action} ' /filename;
3) relational expression :关系表达式,结果为非0值处理。
自己写出的语句:
一开始是使用的grep+awk:
cat log4j.log | grep "method:action.StudentController"| awk -F ":"
后来用了awk的pattern筛选:
awk -F: '/method:action.Studentcontroller/{print $3} ' log4j.log(这句话可以提取出响应时间)
然后又试着用:
awk -F: ’
BEGIN {action}
/pattern/ {action}
/pattern/ {action}
...
END{action}' filename
写了一个脚本,可是报错不能用,awk语句如下:
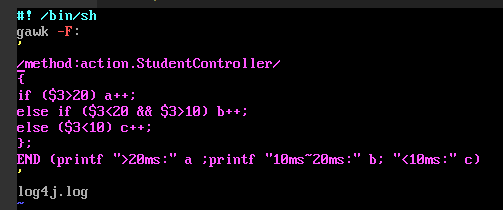
今天的收获:
学习了awk,写了个脚本(可惜不能用),试着帮别人解决一个任务二的问题(最后我拿着别人的项目改成了自己的格式,还是思维太固定了),这里举个例子吧,别人href用的是/deletestudent?id=${student.id}传参,我没用过问号,没想到控制器直接用/deletestudent就可以接到传递的参数,可是我想用控制台输出这个id参数结果啥都没没输出出来,可是@requestmapping(/deletestudent) 方法(student)就能调用方法提供参数student直接删掉数据,太神奇了....
遇到的问题:
看了一下任务4,需要新加一个毕业师兄数据库,另外的合作伙伴之类的不用数据库,看了两个别人的日报还都建了2个数据库,自己理解有点问题。
明天的计划:
将静态页面转换成动态界面,学习新的框架。




评论