发表于: 2018-04-01 17:59:18
1 596
今天完成的事情
先做任务,测试一下连接DB中断后TryCatch是否能正常处理。
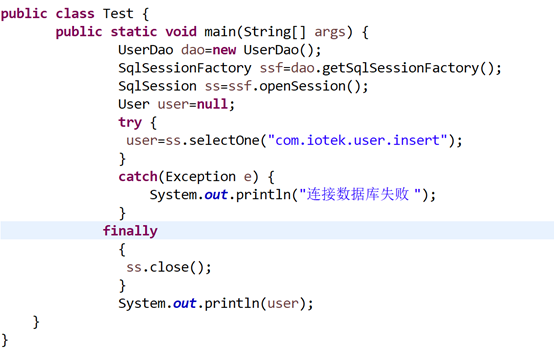
找到之前写的一段连接DVD影碟租赁系统数据库的代码,可以看到连接数据库的语句包裹在trycatch当中,先确保数据库是处于连接状态的,执行。
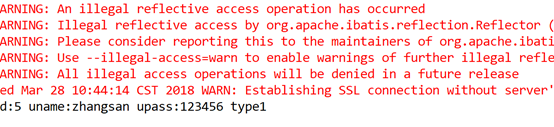
可以正确查到结果。
为了验证TryCatch是否能正确处理,这次先将数据库服务关闭,再执行程序。
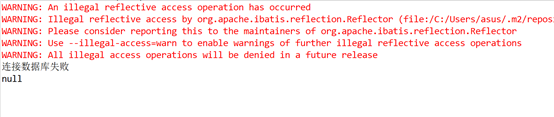
可以看到程序正常执行结束,若我们去掉catch这个环节。
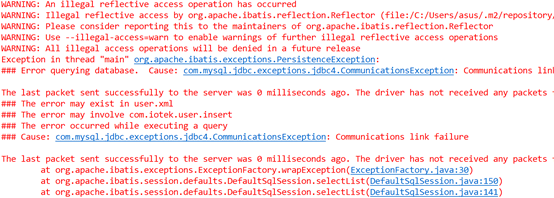
程序将报错,所以说明TryCatch可以正确处理数据库连接不到的问题。
这个任务使用到了异常处理的知识,所以就借此机会对异常处理部分的知识进行梳理一下。
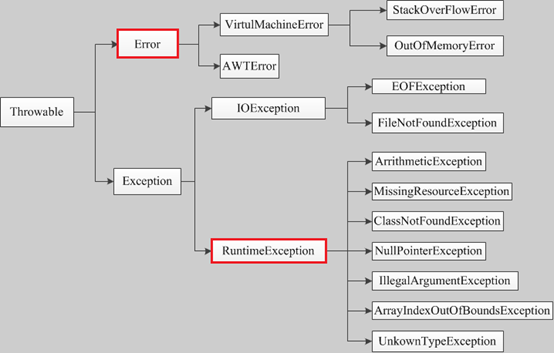
首先来看一张java异常的分类和类结构图,Throwable是所有异常的顶层父类,只有直接或者间接的继承了Throwable,才是一个异常对象,才能被java的异常处理机制所识别。而Throw
able派生出Error类和Exception类。
错误:Error类以及他的子类的实例,代表了JVM本身的错误。错误不能被程序员通过代码处理,Error很少出现。因此,程序员应该关注Exception为父类的分支下的各种异常类。
异常:Exception以及他的子类,代表程序运行时发送的各种不期望发生的事件。可以被Java异常处理机制使用,是异常处理的核心。
而根据我们对异常的处理要求,又可以分为两类;
非检查异常(unckecked exception):Error 和 RuntimeException 以及他们的子类。javac在编译时,不会提示和发现这样的异常,不要求在程序处理这些异常。所以如果愿意,我们可以编写代码处理(使用try…catch…finally)这样的异常,也可以不处理。对于这些异常,我们应该修正代码,而不是去通过异常处理器处理 。这样的异常发生的原因多半是代码写的有问题。如除0错误ArithmeticException,错误的强制类型转换错误ClassCastException,数组索引越界ArrayIndexOutOfBoundsException,使用了空对象NullPointerException等等。
检查异常(checked exception):除了Error 和 RuntimeException的其它异常。javac强制要求程序员为这样的异常做预备处理工作(使用try…catch…finally或者throws)。在方法中要么用try-catch语句捕获它并处理,要么用throws子句声明抛出它,否则编译不会通过。这样的异常一般是由程序的运行环境导致的。因为程序可能被运行在各种未知的环境下,而程序员无法干预用户如何使用他编写的程序,于是程序员就应该为这样的异常时刻准备着。如SQLException , IOException,ClassNotFoundException 等。
http://www.importnew.com/26613.html:
详细的在这个网站中,文章里已经写得很详细了,感觉异常这方面没什么好多说的,理解也挺快的。
检查自己的代码是否符合规范
想检查自己的代码是否符合规范,自然得先知道规范是什么,上网搜索了一下,都是洋洋洒洒的一大篇文章。然而我们的只是用于学习的demo,自然有很多用不上。我感觉现阶段,诸如包名要小写,类名要首字母大写以及方法的驼峰式命名法等,我还是都有很好的做到。Dao层、实现层、实体层等这些业务逻辑的分离也能够做到,现阶段来说,还是比较规范的吧。
如果数据表格有改动,如果只是单单的数据有改动,我们可以去数据库使用navicat改动,也可以通过我们写好的有改功能的代码改动。如果是表结构有改动,比如多了一个字段,少了一个字段啥的,我们要检查我们写的sql语句,是否有地方用到少了的字段,这时我们要修改相应的sql语句以及功能。具体还是得看变动以及项目的规模吧。
想对比加和不加索引的性能差别,但首先得往数据库中加入大量数据,翻看了很多资料,我这里使用的存储过程方法。简单来说就是通过函数的方法插入数据。
create table test (c1 int(11) default NULL,c2 varchar(30) default NULL,c3 date default NULL);
建表
delimiter //
CREATE PROCEDURE test_insert(n int)
begin
declare v int default 0;
SET AUTOCOMMIT=0;
while v < n
do
insert into test
values (v,'testing partitions',adddate('1995-01-01',(rand(v)*36520) mod 3652));
set v = v + 1;
end while;
SET AUTOCOMMIT=1;
end //
delimiter;
写存储过程
call test_insert(1000000);
插入100w条数据

花了接近半分钟
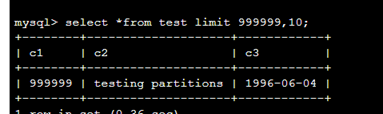
可以看到数据的量是正确的。
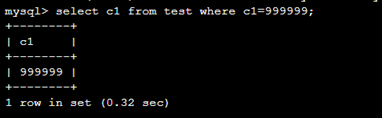
不建立索引的情况下查询

加上索引,可见100w级别数据量加上索引也要花费不少时间了
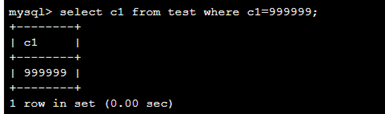
加上索引花费的时间。。看不到。。估计是几毫秒的事情。

用这句话清除数据库中的数据.

加入3000w数据,花了12分半。。
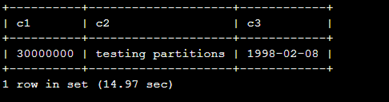
看见数据量没有问题
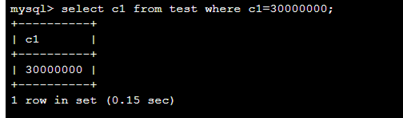
有索引的情况下3000w的数量也只用0.15s。

删除索引都花了接近4min。。。
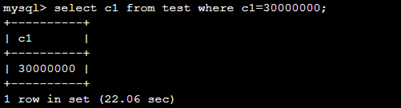
没索引花了22s。。
当尝试2亿条时出了点问题,腾讯云一段时间没操作自动断开了,结果重新登录后对原来进行插入操作的表和库操作一点反应都没有,删也删不掉。不过通过百度后知道可以直接去删除文件
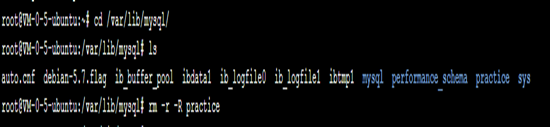
就可以成功删除practice库了。
2亿条暂时还没搞定,不过通过前面的经验光是插入数据就要花不少时间了。所以以后有机会再尝试吧。
明天计划的事情:
任务也差不多做完了,做最后的总结吧!
遇到的困难:
对数据库的库和表无法操作,通过百度可解决。
收获:
复习了异常机制,学会了往数据库中插入大量数据并体会了加入索引的性能。




评论