发表于: 2018-03-31 20:24:19
1 688
今天完成的事:
1、学习了性能测试的主要概念和计算公式
TPS:Transactions Per Second(每秒传输的事物处理个数),即服务器每秒处理的事务数。TPS包括一条消息入和一条消息出,加上一次用户数据库访问。
TPS是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。系统整体处理能力取决于处理能力最低模块的TPS值。
并发数:系统同时处理的request/事务数
响应时间: 一般取平均响应时间。聚合报告中有平均响应时间、90%、99%响应时间。
一个系统吞吐量通常由TPS、并发数两个因素决定,每套系统这两个值都有一个相对极限值,在应用场景访问压力下,只要某一项达到系统最高值,系统的吞吐量就上不去了,如果压力继续增大,系统的吞吐量反而会下降,原因是系统超负荷工作,上下文切换、内存等等其它消耗导致系统性能下降。
2、用redis替代了memcached,整合项目成功,成果跑通。服务器安装了redis和memcached。并且发布了redis版本的项目。
3、
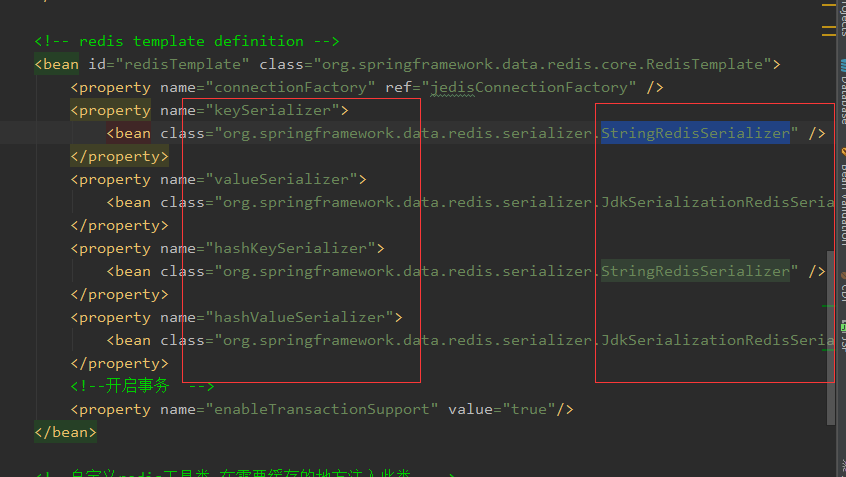
spring-data-redis提供了多种serializer策略,这对使用jedis的开发者而言,实在是非常便捷。sdr提供了4种内置的serializer:
1:JdkSerializationRedisSerializer:使用JDK的序列化手段(serializable接口,ObjectInputStrean,ObjectOutputStream),数据以字节流存储,POJO对象的存取场景,使用JDK本身序列化机制,将pojo类通过ObjectInputStream/ObjectOutputStream进行序列化操作,最终redis-server中将存储字节序列,是目前最常用的序列化策略。
2:StringRedisSerializer:字符串编码,数据以string存储,Key或者value为字符串的场景,根据指定的charset对数据的字节序列编码成string。
3:JacksonJsonRedisSerializer:json格式存储,jackson-json工具提供了javabean与json之间的转换能力,可以将pojo实例序列化成json格式存储在redis中,也可以将json格式的数据转换成pojo实例。因为jackson工具在序列化和反序列化时,需要明确指定Class类型,因此此策略封装起来稍微复杂。
4:OxmSerializer:xml格式存储,提供了将javabean与xml之间的转换能力(不推荐)
缓存穿透,缓存击穿,缓存雪崩解决方案分析
博文链接:https://blog.csdn.net/zeb_perfect/article/details/54135506
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
这里不是很懂,我的程序根本就不会去搭理不存在的key啊,有怎么会去麻烦数据库呢?
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
这个很好理解,缓存时间错开一点就行了。
缓存击穿:对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
今天服务器上忙活了大半天,代码敲得少
遇到的问题:
服务器上tomcat日志乱码。改了好久没改过来。明天再试试。
明天的计划:
整理一下代码
收获:服务器安装部署redis




评论