发表于: 2018-03-29 23:24:01
1 603
今天完成的事情:(一定要写非常细致的内容,比如说学会了盒子模型,了解了Margin)
一、关于使用注解方式注入对象
1.首先,之前对注解有些地方理解不清楚,现在有点头绪了。
写在applicationContext.xml文件中的对象一开始就被创建了,需要用的时候就拿来用
@Autowired 注解会去xml文件中寻找与注解下面类型相同的类,将那里面通过IOC创建的对象DI进注解下面的这个类的新创建的对象中,相比于传统的使用的时候new一个对象出来,它是一直都有对象在的,而且属性都被赋予好了,拿来用就是了。
@Autowired如果注解set方法,就是将xml中创建好的对象赋予给set中的形参,让其再传递给实参,就可以起到注入属性的作用了
@Resource相比与@Autowired则是优先匹配的东西不一样,A优先匹配类型,也就是bean后面的class,R则是优先匹配bean后面的name,一般需要额外指定,所以图方便可能A用的多一点。
但是可以通过关键字@Qualifier来使A按照姓名匹配,但是这样的话还不如使用R,所以用的也比较少。
@Component是注解类的,即产生一个此类的新对象,此对象属性就是在类下面已经被赋予过的默认值,所以如果不赋予值就会产生一个全是默认值的对象
2.将PersonServiceTest中换为注解模式
@RunWith(SpringJUnit4ClassRunner.class)//生成spring容器
@ContextConfiguration(locations = {"classpath:applicationContext.xml"})//加载配置
public class PersonServiceTest ;//注入属性
@Autowired
IPersonDao personDao ;
测试通过
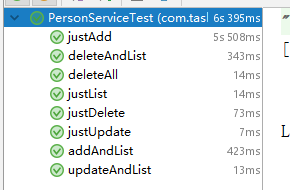
当使用同样注解在PersonServiceImpl中时,运行Main方法却报空指针异常

调试发现personDao并没有注入进去,显示是Null
这是因为Main是程序的入口是程序中最先加载的,此时是无法直接来使用personDao,因为连spring容器都没有生成,所以更别提IOC,DI的实现了,因此此时只能使用先生成容器加载配置再从容器中获取personDao.
因为Main的特殊性,所以其获取连接,从容器中获取Dao这一步不能使用注解的方式。
二、task28,数据库插入100万,2000万,2亿条数据,对比建索引和不建索引的差别。
1.首先是正常情况下100万条,数据如下
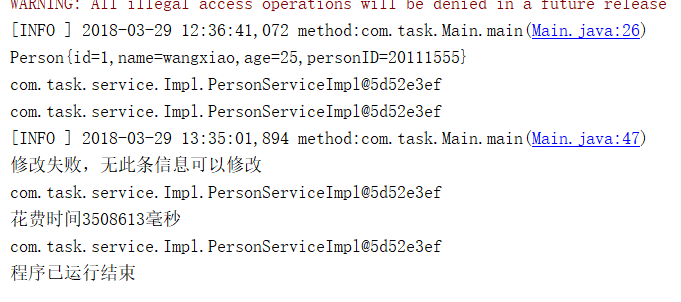
一共花了3508秒,查询一条 语句花费时间如下
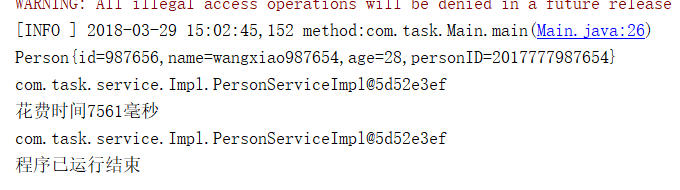
一共花了7.5秒
然后是去掉姓名里面的唯一索引,只保留Id后,插入100万条数据
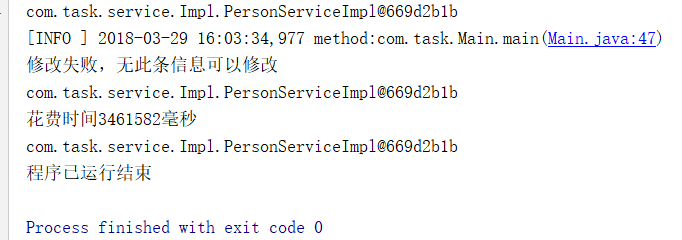
一共花费了3461秒,差距不大,查找数据
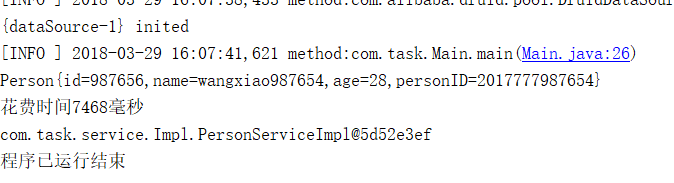
还是差距不大,好像又和预想中的有些差别啊。
和师兄咨询了一下,是因为我姓名里面的字符类型是varchar,所以建不建索引差别就不大,可能还需要继续实验。
三、深度思考
1.maven是什么,和Ant有什么区别?
Maven:通过标准化,清晰化,简单化的方式来共享管理jar的一个项目管理工具。jar的作用是通过别人已经明确定义的项目方式来描述自己的项目,主要是为了节约程序员构建基层源码的时间。同时,通过maven建立的项目有相同的结构,便于管理交流。
和Ant相比,Ant拥有的功能它都有,除此之外,它比Ant多了四个功能
1)使用Project Object Model来对软件项目管理;即pom.xml文件
2)内置了更多的隐式规则,使得构建文件更加简单;即相同的结构
3)内置依赖管理和Repository来实现依赖的管理和统一存储;即通过本地仓库和中央仓库实现依赖的管理和共享
4)内置了软件构建的生命周期;显式地定义了项目构建,测试和发布的过程,是每个maven工程的核心。应该是指用maven创建项目,跑单元测试,打包等操作吧。
| Maven | Ant | |
| 标准构建文件 | project.xml 和 maven.xml | build.xml |
| 特性处理顺序 | ${maven.home}/bin/driver.properties ${project.home}/project.properties ${project.home}/build.properties ${user.home}/build.properties 通过 -D 命令行选项定义的系统特性 最后一个定义起决定作用。 | 通过 -D 命令行选项定义的系统特性 由 任务装入的特性 第一个定义最先被处理。 |
| 构建规则 | 构建规则更为动态(类似于编程语言);它们是基于 Jelly 的可执行 XML。 | 构建规则或多或少是静态的,除非使用<script>任务 |
| 扩展语言 | 插件是用 Jelly(XML)编写的。 | 插件是用 Java 语言编写的。 |
| 构建规则可扩展性 | 通过定义 <preGoal> 和 <postGoal> 使构建 goal 可扩展。 | 构建规则不易扩展;可通过使用 <script> 任务模拟 <preGoal> 和 <postGoal> 所起的作用。 |
2.clean,install,package,deploy分别代表什么含义?
clean是将编译好的target文件夹中的字节码文件(.class)删除,一般在程序有重大调整,比如换结构,换依赖时会使用
package将项目打包,打包完毕会在target下生成打包好的jar.war等文件
install将打包完的jar包安装到本地仓库,方便本地仓库其他项目引用
deploy将打包好的jar包拷贝到远程的中央仓库,供他人下载使用
3.怎么样能让Maven跳过JUnit?
因为我们一般都是用集成的按钮直接打包,所以为了跳过打包前自动测试,一般是使用在pom.xml中添加插件来跳过
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<!--此处为ture则在打包时自动跳过test-->
<skipTests>true</skipTests>
<testFailureIgnore>true</testFailureIgnore>
</configuration>
</plugin>
或者是在使用命令行时输入
mvn install -DskipTests
或者
mvn install -Dmaven.test.skip=true
4.为什么要用Log4j来替代System.out.println?
我的理解:因为sout只能实现输出到控制台,并且不能操作输出内容的格式,级别等,而log4j可以实现信息的按级别和指定格式输出到指定位置,使得程序关闭后也可以查看信息
5.为什么DB的设计中要使用Long来替换掉Date类型?
我的理解:数据库内部对于时间的计算就是用时间戳的方式进行的,所以用BIGINT来存储时间戳不仅运行速度查找速度上更快,而且可以避免以DATA方式存储造成的时区影响,在输出时可以利用转换函数,就可以避免看起来不够直观的问题了
6.自增ID有什么坏处?什么样的场景下不使用自增ID?
我的理解:今天自己做表格时,由于数据录入错误,所以多次删除了数据,导致后面录入的数据Id不是连续的,它将删除数据的id永久跳过了,所以如果数据在录入过程中需要经常增删的话,那么自增ID不仅会导致ID的不连续而且在后期按照ID查找时会容易造成数据为空的情况。
7.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
我的理解:数据库的索引是为某一列或几列数据添加的标记,可以利用这个标记快速定位到需要查询的数据中(相当于定位法术);当数据库的数据量上千,超过mysql的内存,使得其无法将所有记录储存在内存中随时调用时,建索引才会产生性能差别,可以理解为当我身上口袋装不下时,买个包才会比用手捧着作用明显;当某字段经常作为关键字被查询时,即SELECT WHERE 语句中,WHERE后面的变量经常定义的字段需要建立索引,可以提高查询效率,如果不用此关键字进行定位,也就无需建立索引了,因为建立索引不仅需要消耗内存,花费时间,而且修改数据速度也会变慢。一般数据量上十万时就会产生影响了
8.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
我的理解:唯一索引意味着不同行内的索引值不能重复必须唯一,简单索引则允许不同行存在重复索引,当我们建索引行的内容不存在重复可能时(比如QQ号,手机号)建唯一索引可以增加效率,而且建立了唯一索引之后,再插入新数据时系统会自动检测新数据是否重复,如果重复,则会拒绝插入此数据。但是唯一索引在插入时要注意try-catch错误,因为数据重复是会报错的。
9.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
我的理解:由于唯一索引的机制就是数据唯一性,所以为了避免数据重复,在插入前,系统会先判断是否存在,如果存在就拒绝插入,不存在就可以顺利插入。
10.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
我的理解:create_at一般在创建数据时赋值,update_at则是在修改数据时赋值,即前一个一般只有一个值且不会变,后一个则可能多次变化;一般情况下是不会开放外部调用接口的,因为这个属性不需要人为修改。
11.修真类型应该是直接存储Varchar,还是应该存储int?
我的理解:Int类型只能存储整数,而修真类型一般会以单词或是中文来表示,所以用VARCHAR比较好,但是Int的话插入读取等操作都比较快,所以数据量大的时候是可以考虑用INT来代替varchar的
12.varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
我的理解:建立表格时,数据类型中便需要确定好VARCHAR类型的最大长度,由于其长度可随输入内容而变化,所以在系统中其存储空间是不固定的,(而CHAR类型由于长度固定的,如果输入的数据不到最大长度,则会以空格填满)但超过最大长度则会报错,一般长度低于255会用一个字节储存长度,大于255会用两个字节储存长度;TEXT和LONGTEXT的区别是可存储字符长度上,TEXT最大存储65535长度,而LONGTEXT则可以存储2^32-1长度的字节
13.怎么进行分页数据的查询,如何判断是否有下一页?
一般在sql中使用limit a,b来实现分页查询,但是真正操作时,可以根据返回的起始页数来稍微改变sql语句,select * from table limit (s-1)*p,p;其中s为开始页数,p为每页数据条数,如果第一页,每页十条,那么就是select * from table limit (1-1)*10,10;等价于select * from table limit 0,10;即从0条开始,查询10条数据们可以根据数据总数,和每页数据数来判断总页数,再结合当前页数s,就能判断是否还有下一页了
14.为什么不可以用Select * from table?
因为当数据库数据量很大时,全部筛选出来不仅筛选得很慢,而且也不适合直观的看数据,所以一般需要什么数据就取出什么数据,这也是为什么需要多定义一些查找的方法的原因了。
15.什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
a.贫血模型是指Model中只有基本的成员变量(属性)和它们对应的get/set方法,却不包括具体方法(行为),采用这种设计时,需要分离出DB层,专门用于数据库操作。即在基本的pojo上面要有Dao层,只包含CURD等基本方法的接口类和重写接口类中方法的实现类,再上面是Service层,来进行基本的逻辑业务操作。
b.充血模型是指Model中不仅有基本的成员变量还有具体方法,所以说充血方法是更符合面向对象思想的。其只有包含了属性和方法的Model层和具体实现的Service层。
c.贫血模型优点是系统的层次结构清楚,各层之间单向依赖。缺点是不够面向对象。
充血模型优点是面向对象,Business Logic符合单一职责,不像在贫血模型里面那样包含所有的业务逻辑太过沉重。缺点是比较复杂,对技术要求更高。而且程序各层之间耦合度较高,出现改动时改的比较多。
16.Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
IOC即控制反转,将创建对象的过程交给spring去完成,使用IOC可以降低程序耦合度,实现资源的可配置和易管理,将高层依赖底层扭转为底层依赖高层
https://blog.csdn.net/c513063286/article/details/71516886
17.为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
首先,可以实现多态,即一个语句多种实现;其次可以在不同实现类添加不同的其独特的方法,如果只有一个实现类就不可以了;一个实现类可以继承多个不同接口,就可以产生多种不同的组合;最主要一点,可以使代码可插拔,降低耦合。
18.为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发 生一次?
如果不处理异常,当异常发生时会直接打断程序的进行,使得程序正常流程被打断,会影响后面本来可以正常运行的流程,而try-catch则可以抓住这个异常后让后面的流程照常走下去。真实系统中也会遇到,但是我觉得概率很小,一般都在服务器上跑数据,数据库也在服务器上,或者本地跑数据,数据库也在本地,即使中断,也没什么影响吧?多久发生一次应该是看网络稳定程度了,越稳定发生几率越小。
19.日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
日志应该首先确定等级,哪些需要输出,然后对于需要控制台输出,需要记录的,分情况输出到不同地方,一般INFO以上的信息都需要在控制台输出,主要打印错误类型,时间,发生在函数的什么位置,然后就是具体信息,其他的可以看需要添加。
20.为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
运行程序时有时发生错误我们不能直接从错误信息里判断到底哪一步出错了,此时就可以使用单步调试,在调试过程中一步步比照程序的流程,看那些关键参数的值,流程进度等和自己预估的是不是一样的,从而方便我们找出bug。Debug的时候IDE应该是靠导入的依赖包直接进入源码的吧。
21.可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
到后面程序上线之后出现Bug应该都是采用远程直接调试的,如果在本地还可以分析日志来找问题,线上的话直接debug模式比较方便一点。
四、在已经做出来整合spring-mybatis的版本上,再写一遍mybatis版本和jdbctemperate版本
明天计划的事情:(一定要写非常细致的内容)
1.将另外两个版本做好,对照验收标准检查一遍
2.总结任务一,提交任务
遇到的问题:(遇到什么困难,怎么解决的)
中间写mybatis-config.xml的时候直接copy的配置,结果因为日报中有一个单行注释没有注意到,找了半天bug
收获:(通过今天的学习,学到了什么知识)
1.加深了对注解的理解
2.通过深度思考,进行了一些平时漏掉的知识点的补充




评论