发表于: 2018-03-29 08:56:15
2 530
twelfth day
昨天学习了Hibernate,受阻。后面学习了XML以及通过Java访问XML文件的四种方式
今日任务:
1. Hibernate 继续配置
2. XML DOM 教程(W3C)
3. XML 的java访问
4. 搜索目前Java相关技术和框架,比如SSH和SSM,微服务等等
5. JavaBean -- 我注意你很久了,今天你完了
6. https://www.activiti.org/,没什么我想看看这是什么
学习轨迹:
第一部分: XML 解析
1. IBM-Java 处理 XML 的三种主流技术及介绍(https://www.ibm.com/developerworks/cn/xml/dm-1208gub/)
Wikipedia 中对XML的解释很nice:
In computing,Extensible Markup Language(XML) is a markup language that defines a set of rules for encoding documents in a format that is both human-readable and machine-readable.
很到位。
IBM 这篇文章是 12 年底发布的,可能比较老,但是解释的是Perfect,全局搜XML还是有其他解析方式的介绍,后面再看看。这篇介绍了三种方式: DOM、SAX、Digester
整体看一下:
DOM: 牛逼的,是 JDOM DOM4J 的原始
SAX:绿色环保,快速
Digester: 低调,XML 的 JavaBean 化
三种方式比较以及使用范围:
1. DOM
优点:实现W3C标准,易学。
缺点:整个XML都读入然后在解析,对于数据量比较大的XML文件无能为力
适用范围:小型 XML 解析,需要全部解析或者大部分解析的XML,需要修改XML内容以生成自己的对象模型
2. SAX
优点:通过类似流的解析技术,通读整个XML文档树,可以解析部分XML
缺点:不好学,API复杂
适用范围:大型XML文件解析,只需要分析或者只想取得部分XML树内容,有XPath查询需求,有自己生成特定XML树对象模型的需求
3.Digester/JAXB
优点: ----
缺点: Struts 的 XML 解析工具,不算缺点吧这个,
适用范围:有将XML文档直接转换为JavaBean的需求
DOM (Document Object Model)
Wikipedia: https://en.wikipedia.org/wiki/Document_Object_Model
模型:
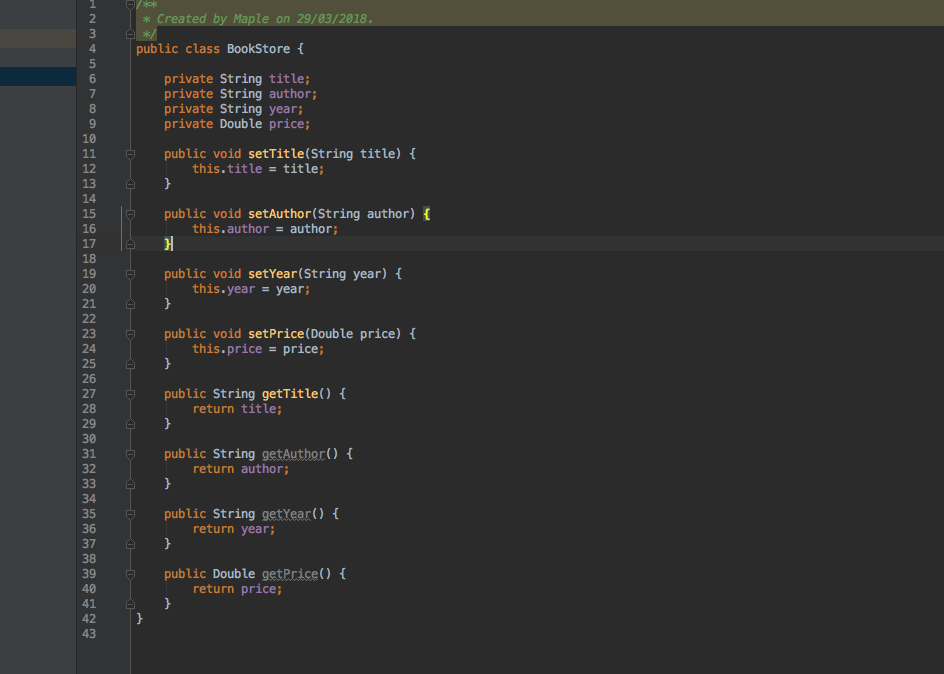
获取XML DOM 文档节点
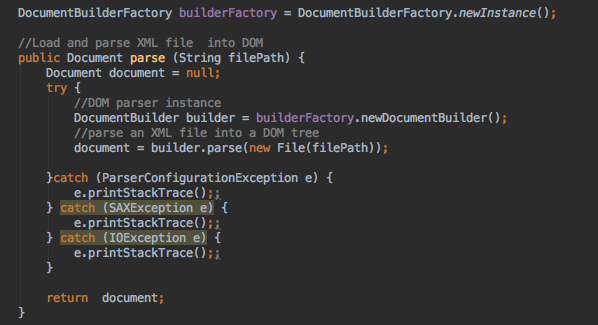
解析 XML
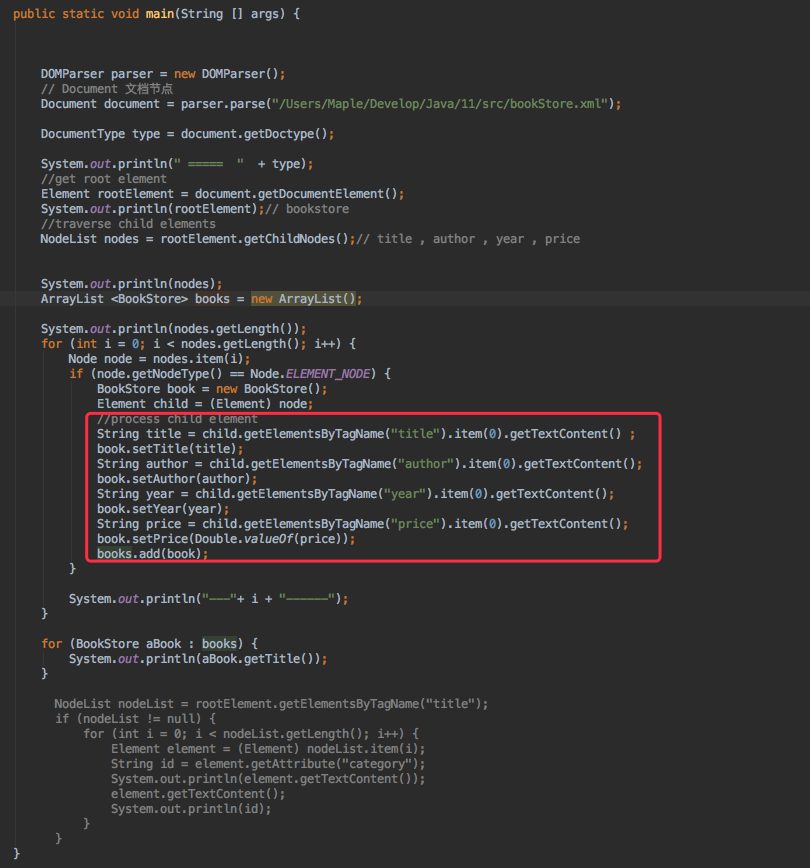
要想很好的使用DOM,必须了解 XML DOM中的内容,W3C 中是在网页的基础进行讲解,所以要知道一些HTML和JavaScript的基础然后将这种思想和方法从js中转换过来。
汗 ... ... 就这一种方式就逼着我去了XML DOM 课程,后面那两种方式放到明天吧。
第二部分: XML DOM认识
XML DOM -- XML Document Object Model 的缩写,即XML文档对象模型
为什么会有 XML DOM 这部分,在学习 Java 解析 XML 的时候,针对DOM解析方式,发现 Element、NodeList 这些概念陌生,所以就先来看先 XML DOM 课程。
1. XML DOM 简介
DOM , XML 文档对象模型定义了访问和操作XML文档的标准方法, DOM 将XML文档作为一个树形结构,而树叶被定义为节点。
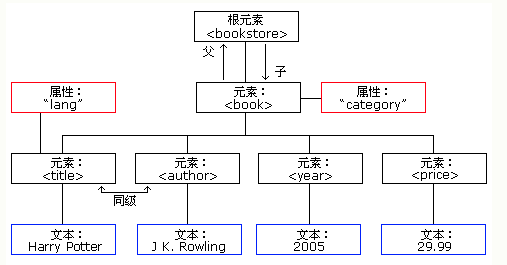
什么是 XML DOM ?
- 用于 XML 的标准对象模型
- 用于 XML 的标准编程接口
- 中立与平台和语言
- W3C 的标准
XML DOM 定义了所有XML 元素的对象和属性,以及访问它们的方法(接口)。
通俗的讲: XML DOM 是用于获取、更改、添加或者删除XML元素的标准。
2. XML DOM 节点
节点, 根据DOM, XML 文档中的每个成分都是一个节点。
- 整个文档是一个文档节点;
- 每个XML标签是一个元素节点;
- 包含在XML元素中的文本是文本节点;
- 每一个XML属性是一个属性节点;
- 注释属于注释节点
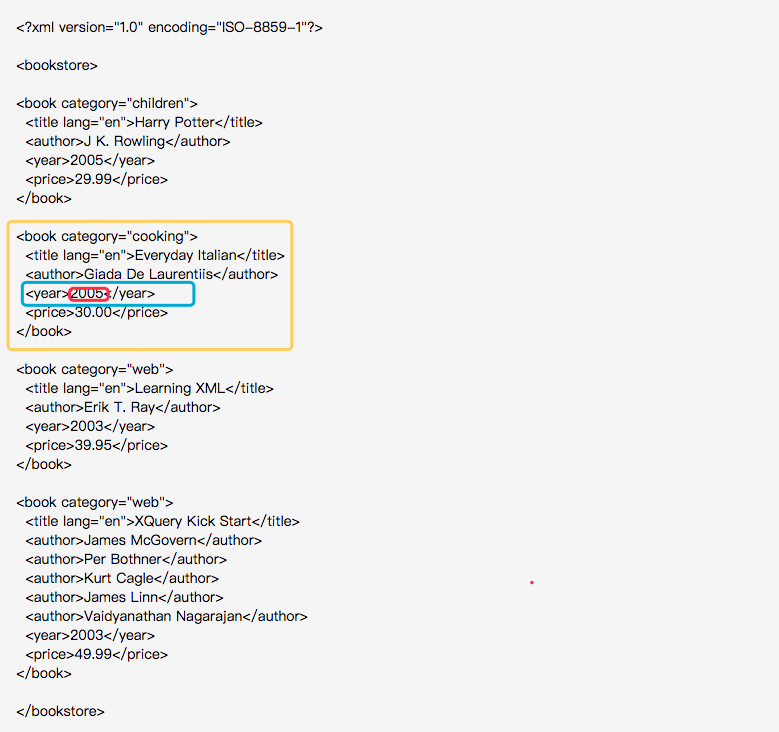
上面XML文件中,根节点是<bookstore>。该文档中的其他所有节点都被包含在其中。
在<bookstore>中有四个<book>节点,而<book> 节点中有四个节点:<title> <author><year><price>,这四个节点中都包含了文本节点。
注意一点: 文件总是存储在文本节点中,比如<year>2005</year> 拥有一个 “2005 ”的文本节点,“2005”不是<year> 元素的值。在java中通过
public String getTextContent()
throws DOMException;
获取文本节点中的值。
3. DOM 节点树
XML DOM 把 XML DOM 文档视为一棵节点树(node-tree).
树中的所有节点彼此之间都有关系。
可通过这棵树访问所有节点,可以修改删除或它们的内容,也可以创建元素。
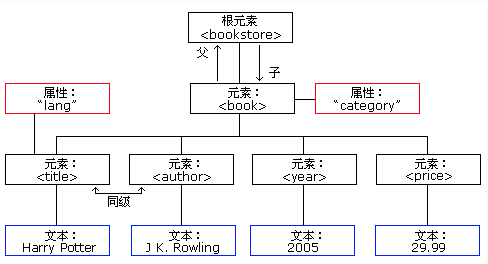
父子和同级节点:
节点树种的节点彼此之间都有等级关系,通过父、子和同级节点来描述这种关系。父节点拥有子节点,位于相同层级上的子节点称为同级节点(兄弟或姐妹)。
- 在节点树种,顶端的节点成为根节点;
- 根节点之外的每个节点都有一个父节点;
- 节点可以有任何数量的子节点;
- 叶子是没有子节点的节点;
- 同级节点是拥有相同父节点的节点
因为XML数据是按照树的形式进行构造的,所以可以再不了解树的确切结构且不了解其中包含的数据类型的情况下,对其进行遍历。
父节点: Parent Node 子节点: Children Node 同级节点: Sibling Node

<title> 是 <book> 元素的第一个节点,而<price> 元素是<book>的最后一个子节点。
此外,<book> 元素是<title> <author> <year> 以及 <price>元素的父节点。
第三部分 Hibernate 配置
进行中 ... 虽然没有做完,但是找到方案了,可喜可贺,不容易啊,这个东西用起来真的真的很麻烦
第四部分 JavaBean 是什么东西?
维基百科: JavaBean 是 Java 中一种特殊的类,可以将多个对象封装到一个对象(bean)中。特点是可序列化,提供无构造器,提供 getter 方法 和 setter 方法访问对象的属性。名称中的 “Bean” 是用于 Java 的可重用软件组件的惯用叫法。
优点:
- Bean 可以控制它的属性、事件和方法是否暴露给其他程序(setter getter)
- Bean 可以接收来自其他对象的事件,也可以产生事件给其他对象
- 有软件可以用来配置 Bean
- Bean 的属性可以被序列化,以供日后重用
JavaBean 规范
要成为 JavaBean 类,则必须遵循关于命名、构造器、方法的特定规范。有了这些规范才能有可以使用、复用、替代和连接的JavaBean的工具。
规范:
- 有一个public的无参构造方法
- 属性可以通过get set is方法或者遵循特定的命名规范的其他方法访问
- 可序列化
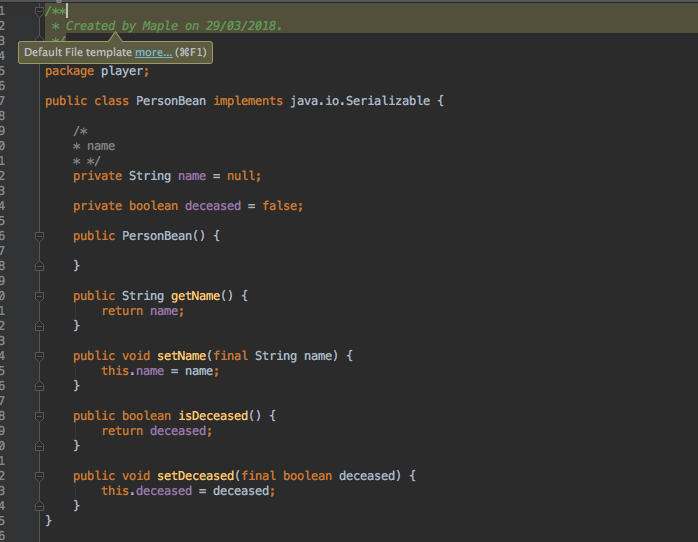
虽然上面解释了 JavaBean 但是还是不太理解,这了通过一个例子再来加深理解下:
这里,实现了以链表类,并且供当前工程使用,没问题后,将 JavaIntList 打成 Jar 包
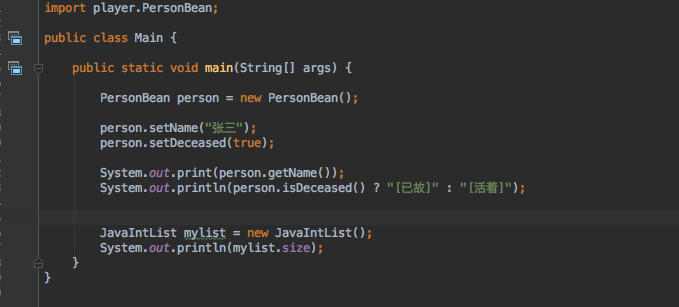
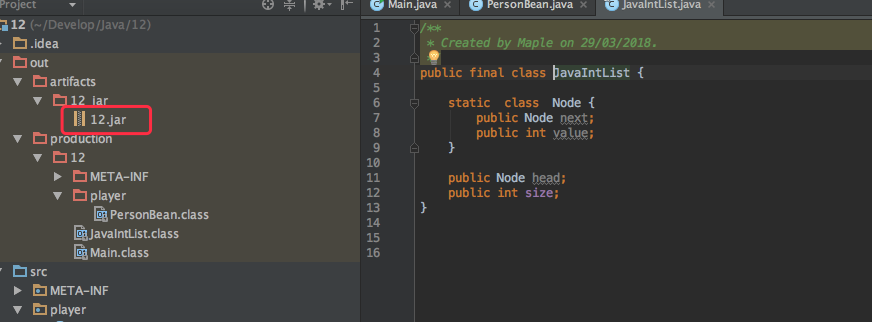
我重新建立了一个新的工程 JavaBeanTest,并且引入了12.jar 包
然后使用 JavaIntList 没问题

注意,JavaIntList 中有一个变量 size,这个是让使用者快速获取链表的大小的。但是如果有天12.jar 为了节省空间,将size变量去除,原来的代码就是:
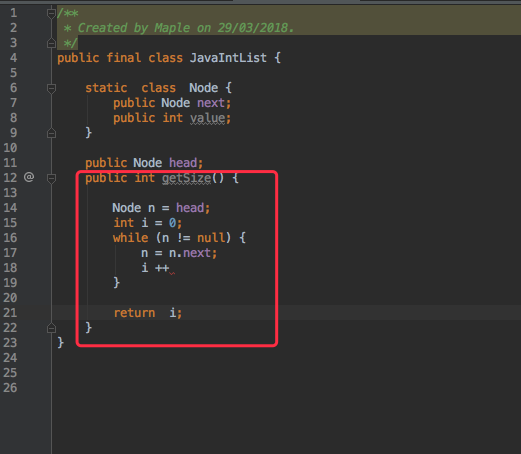
通过公开了一个 getSize 的方法,将size变量省去了。在自己的工程中将 size 替换成 getSize() 测试一下没问题
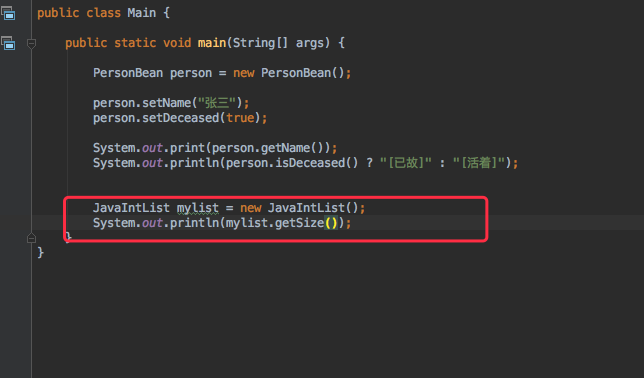
于是将目前的程序打成 jar 包,然后给 TestJavaBean 使用:(当然按照前面打jar的方式不能完成,因为工程里已经有了一个 xxx 文件,我直接把之前的删除了,应该还有其他方式,先不去管了)
 打出 2_0 的包,然后交付给TestJavaBean 使用,替换jar包,运行:
打出 2_0 的包,然后交付给TestJavaBean 使用,替换jar包,运行:
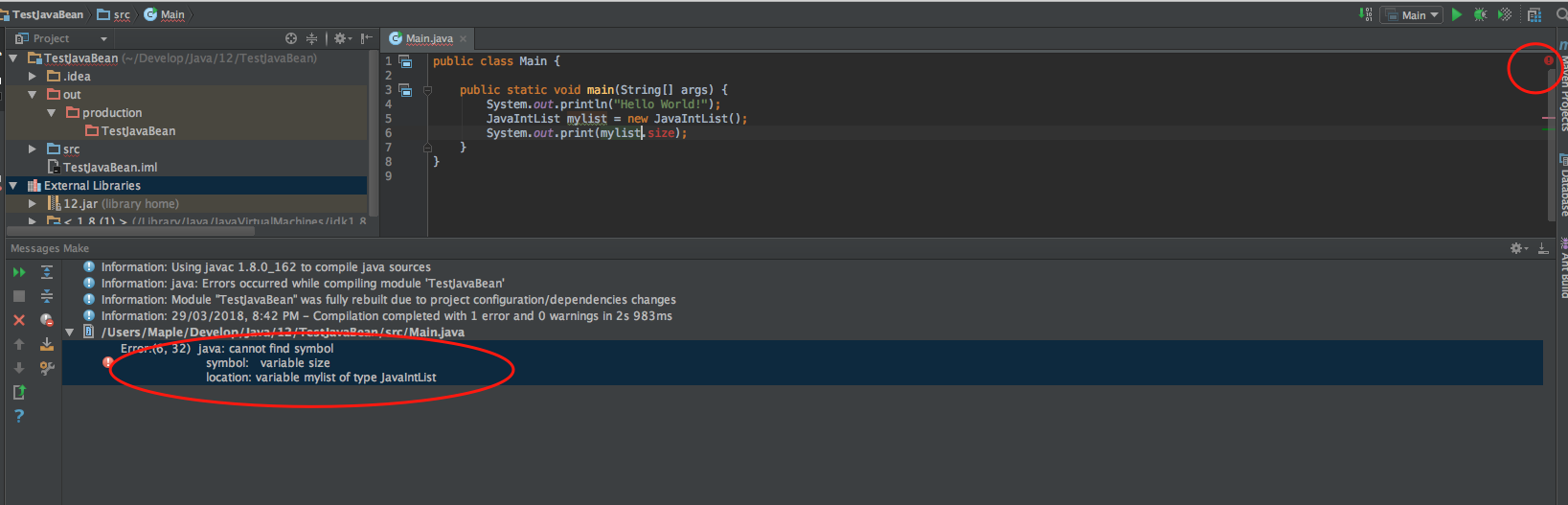
这种就是在开发公开库的时候,接口不能向后兼容造成的问题。
在Java标准库中一开始就会是
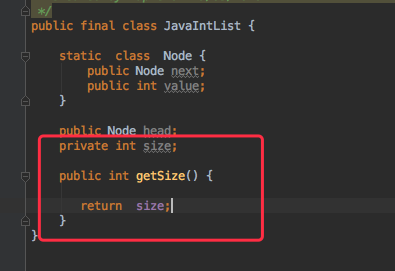 ,JavaTestBean 工程一开始就使用 getSize() 方法获取大小,这样以后如果12.jar包中修改了 getSize() 的实现,也不会影响其他地方的使用,不破坏向后兼容。而这种手法就叫做 JavaBean
,JavaTestBean 工程一开始就使用 getSize() 方法获取大小,这样以后如果12.jar包中修改了 getSize() 的实现,也不会影响其他地方的使用,不破坏向后兼容。而这种手法就叫做 JavaBean
来源:https://www.zhihu.com/question/19773379
当然,知乎上这位提出了 Scala 和 C## 这两种语言,我就不晓得了,哈哈。
还有位概括回答的:

从知乎上有了解到了: POJO EJB DTO VO PO 这些概念,感觉就是规范分层处理业务这么一些东西。
JavaBean 不够强大 出来了 EJB ,EJB 太复杂又出来POJO,置于后面的哪几个应该是针对特定领域的规范了。
这两篇也很不错,通读后对 Bean 有了深刻的理解,应该是bean家族系列
https://mp.weixin.qq.com/s?__biz=MzAxOTc0NzExNg==&mid=2665513115&idx=1&sn=da30cf3d3f163d478748fcdf721b6414#rd
https://mp.weixin.qq.com/s?__biz=MzAxOTc0NzExNg==&mid=2665513118&idx=1&sn=487fefb8fa7efd59de6f37043eb21799#rd
到这里,对JavaBean彻底认识了,一个规范的类,因为遵循了规范所以被用作接口的设计。
总结:
1. 解析XML内容,其实如果对树的结构比较了解的话,理解XML很容易。因为整个XML文档就是一棵树,XML中包含的内容就在树的每个节点上。当然,XML的这种设计也是通过分层的思想将复杂的结构简单化,非常nice的设计;
2. 认识了下 XML DOM,因为解析 XML 文档让不开这块东西的,因为你用的是面向对象的方式进行解析吗。 当然如果能够读 JS 和 HTML 好的了解的话对这块应该有很大的帮助,反之亦然。
3. JavaBean 好早之前那就遇到了,看着书上时候怎么怎么样。对这个概念很陌生,今天完全知道了,就是执行了标准规范的类,尤其是从开方 jar 包那里入手,加深了理解。当然,如果对 JSP 有了解的话,理解起来更简单了就。通过 JavaBean理解了新的一些概念 POJO 什么的
4. Hibernate 真的好麻烦,不光配置麻烦,而且用起来 ... 天哪 ... 不过也许是刚开始看的缘故,估计后面看完了,练几次就感觉不到了。
明日计划:
1. XML 解析方式 (IBM)
2. Hibernate 争取会用
3. mybatis 涉及一下




评论