发表于: 2018-03-28 22:33:06
1 546
今天完成的事情:(一定要写非常细致的内容,比如说学会了盒子模型,了解了Margin)
13.怎么进行分页数据的查询,如何判断是否有下一页?
MySQL数据库提供了LIMIT函数。一般只需要直接写到sql语句后面就行了。
LIMIT子句可以用来限制由SELECT语句返回过来的数据数量,它有一个或两个参数,如果给出两个参数, 第一个参数指定返回的第一行在所有数据中的位置,从0开始(注意不是1),第二个参数指定最多返回行数。例如:
select * from table WHERE … LIMIT 10; #返回前10行
select * from table WHERE … LIMIT 0,10; #返回前10行
select * from table WHERE … LIMIT 10,20; #返回第10-20行数据
14.为什么不可以用Select * from table?
select * from table 查询的是这个表中的所有列,但是一般情况下我们只需要查询某一个或多个字段,而不需要所有字段都查询,这样会影响效率,所以在明确知道自己所需字段的情况下不推荐使用SELECT FROM TABLE。
另外如果是要查询总条数,也不推荐使用SELECT count(*) FROM TABLE; 而推荐使用SELECT count(0) FROM TABLE。
15.什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
贫血模型:是指领域对象里只有get和set方法,或者包含少量的CRUD方法,所有的业务逻辑都不包含在内而是放在Business Logic层。
优点是系统的层次结构清楚,各层之间单向依赖,Client->(Business Facade)->Business Logic->Data Access(ADO.NET)。当然Business Logic是依赖Domain Object的。似乎现在流行的架构就是这样,当然层次还可以细分。
该模型的缺点是不够面向对象,领域对象只是作为保存状态或者传递状态使用,所以就说只有数据没有行为的对象不是真正的对象。在Business Logic里面处理所有的业务逻辑,在POEAA(企业应用架构模式)一书中被称为Transaction Script模式。
充血模型:层次结构和上面的差不多,不过大多业务逻辑和持久化放在Domain Object里面,Business Logic只是简单封装部分业务逻辑以及控制事务、权限等,这样层次结构就变成Client->(Business Facade)->Business Logic->Domain Object->Data Access。
优点是面向对象,Business Logic符合单一职责,不像在贫血模型里面那样包含所有的业务逻辑太过沉重。
缺点是如何划分业务逻辑,什么样的逻辑应该放在Domain Object中,什么样的业务逻辑应该放在Business Logic中,这是很含糊的。即使划分好了业务逻辑,由于分散在Business Logic和Domain Object层中,不能更好的分模块开发。熟悉业务逻辑的开发人员需要渗透到Domain Logic中去,而在Domian Logic又包含了持久化,对于开发者来说这十分混乱。 其次,因为Business Logic要控制事务并且为上层提供一个统一的服务调用入口点,它就必须把在Domain Logic里实现的业务逻辑全部重新包装一遍,完全属于重复劳动。
贫血模型在实体类中没有逻辑,更适合大型项目开发和合作开发,解耦也方便后期维护。
16.Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
关于IOC在我之前的日报有一篇文章
https://www.zhihu.com/question/23277575
写的很通俗易懂
为什么要用IOC而不是New来创建实例?
调用者直接使用new创建被调用者的实例,两者之间的耦合度很高
要由调用者亲自创建被调用者的实例对象,不利于软件的移植与维护
17.为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
接口和实现类分离,一方面是为了封装,还有接口不一定只有一种实现,同一个方法也可能不止一个类调用。
这个时候用接口实现分离的方法更好实现,耦合度更低。
18.为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发 生一次?
异常exception
异常是程序中的一些错误,但并不是所有的错误都是异常,并且错误有时候是可以避免的。
异常发生的原因有很多,通常包含以下几大类:
1.用户输入了非法数据。
2.要打开的文件不存在。
3.网络通信时连接中断,或者JVM内存溢出。
Try/catch语法
使用 try 和 catch 关键字可以捕获异常。
try/catch 代码块放在异常可能发生的地方。try/catch代码块中的代码称为保护代码。
一个 try 代码块可以后面跟随多个 catch 代码块,叫多重捕获。
如果一个方法没有捕获一个检查性异常,那么该方法必须使用 throws 关键字来声明。throws 关键字放在方法签名的尾部。也可以使用 throw 关键字抛出一个异常,无论它是新实例化的还是刚捕获到的。
java提供了抛出异常捕获异常的逻辑用于处理异常,当程序抛出异常时,如果不存在捕获异常逻辑,正在执行的方法将停止执行,并将该异常向外抛出,调用该方法的程序进行同样的处理,如果也没有进行捕获,则将一层一层的向外抛出,直到到达当前线程处时将会终止线程的执行。
正常情况下mysql对于空闲的连接可能会8小时自动关闭。
然后今天做的 按照昨天了解的分层结构 重新调整一下mybatis +spring 设置了service 层 mapper层 modle层
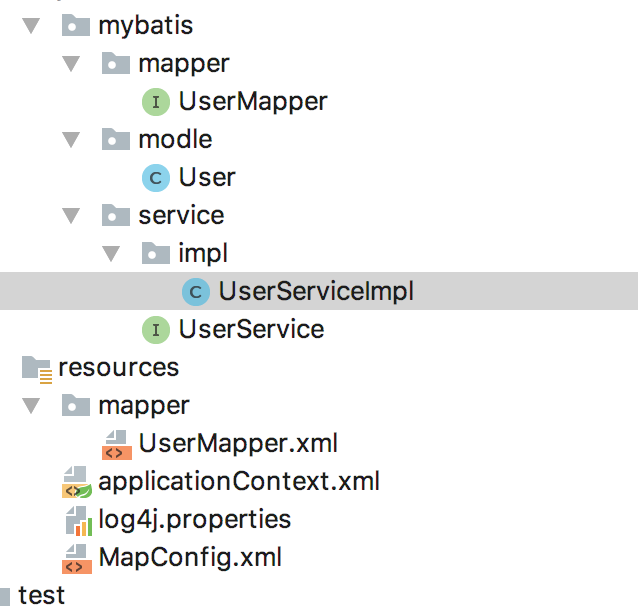
mapper层放UserMapper接口 通过这个类接触mysql 数据库 及调用UserMapper.xml里面基本的增删改查操作。
modle层放User 实体类。
service层 来处理一些逻辑上的业务。UserServiceImpl用来实现UserService 。UserService 接口和UserMapper接口 互不依赖。如果出了问题可以独自修改而不会影响到对方。
而service层是比mapper层更加高级。具体的说话就是
如果我要在查找命令中添加一些条件 那么就是在UserServiceImpl里调用UserMapper的方法的基础上增加方法.
然后经过师兄的指导。对一些基础上的知识也更加理解了
不过 报错了
死活装配不上去、

明天计划的事情:(想办法解决吧 然后写一遍Impl实体类尝试增加多条件接口)
遇到的问题:(报错报错)
收获:(通过今天的学习,学到了什么知识)




评论