发表于: 2018-03-26 22:14:54
4 531
任务一今天算是弄完了吧,可惜jar包依然不能在服务器上运行,报错如下:
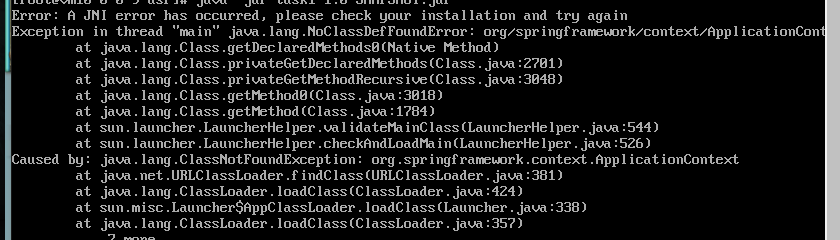
解决方法:
(1)重新装JDK,不行
(2)更改打包方式,不行
(3)没啥办法了。。。但是本地确实是可以运行的
昨天问题的解决办法:
按照网上的多声明了一个service层然后最后在controller层中实现主方法。代码如下:
@Service
public class StudentService {
@Autowired
private StudentMapper studentMapper;
@Controller
public class StudentAction {
@Autowired
private StudentService studentService;
然后通过studentService.studentMapper中的方法就可以实现sql语句了,也算实现了autowired的功能,这个github的desktop有点卡,代码传不上去。
看下深度思考:
1.maven是什么,和Ant有什么区别?
maven是用来管理项目的一种工具,在maven项目下可以更轻松的编写程序,因为maven自带很多隐形规则不用自己实现,再有就是maven可以更好的实现depency依赖文件的配置,还定义了生命周期,clean、install、package等命令(用maven打包项目还是很容易的,依赖这个自己使用很多也能明显感受到,其他网上说的太深奥了,没有用到的功能还不能理解)
ant没用过,但是看了网上的文章,ant的功能maven都可以实现。
2.clean,install,package,deploy分别代表什么含义?
clean清理了target中以前生成的文件,感觉是用来重新生成的时候更方便,不会因为以前有东西就很乱。
install是可以在maven本地仓库下生成可以运行的jar包。
package是可以通过自己配置文件来生成jar包。
deploy没用过,百度是将最终版本的包拷贝到远程的repository,使得其他的开发者或者工程可以共享,这样的。
3.怎么样能让Maven跳过JUnit?
maven中这样配置:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
如果有需要具体跳过哪个test可以:
<include>**/Test1.java</include>
4.为什么要用Log4j来替代System.out.println?
会用到很多System,out.println,然而你并不知道在哪个类哪行输出了里面的东西,一旦这东西数量很多你就会发现你在控制台上根本不知道你需要测试的东西到底是否运行了没有。日志文件好处是你甚至可以得知输出的具体时间,而且可以设置logger等级,在测试阶段使用logger.debug调试代码,发布的时候使用logger.error,不用再去一步步删除System.out.println
15.什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
原来我们正常生成实体类的方法就叫做贫血模型,百度了才知道,即实体类中仅有getter和setter方法,没有业务逻辑,现在主流的框架也是将业务逻辑全部放在service层,而在controller和实体类中都没有具体的业务逻辑,至于为啥强制使用,个人感觉这也是松耦合的一种体现吧,还是说有其他的原因,思考的不深,不太懂。
至于充血模型,就是基本反过来,大部分业务逻辑都体现在实体类中,这样看着会很乱,而且一旦想要修改实体类这些业务逻辑基本是没法修改的,改起来很大工作量。
16.Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
IOC,讲术语是反转控制..我理解是一种控制方法,然后与之相关的DI即依赖注入则是实现反转控制的一种方法,我对spring理解还很不到位,只知道你给它注入它需要的东西他就帮你生成,autowired也是这样,可以直接帮你生成接口的实现对象,功能很强,但是对于初学者来说这也是最难的一步,他中间的过程是怎样的,已经全都被spring通过bean完成,而我们只需要配置bean,这种抽象概念理解起来确实很难,而我这9天的学习也仅仅是大概会用,但是它是怎样实现的,如果autowired失败了要怎那么修改bean我是没有理解到位,任务一我们只需要写一个接口,一个接口配置文件,甚至连业务逻辑层都可以没有,但是一旦后面东西多了bean的配置繁琐起来那很可能spring会出错,所以说还是要抽空理解一下源码?spring自动扫描功能很强)
至于为什么不要用new来创建实例,spring为我们提供了一种松耦合的方法,那就肯定要避免new的紧密耦合方式(可是我想要把autowire应用在static静态块中还是被迫使用了new,感觉有点南辕北辙的意思,师兄说以后的项目不一定要有main方法,那就可以实现自动装配了)。
两者的区别:spring在你拿到它输出的对象的时候该对象已经通过bean装配好了属性,new对象在你得到对象的时候他什么都没有。
17.为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
没看懂这里实体类的含义,是说直接把接口里面的方法拿出来直接定义入参和返回的参数,里面写的很详细那种?那就还是我们需要松耦合,而不是把各个过程紧紧联系在一起,那样修改起来特别费事,其实实体类有一个好处,知道入参,知道返回参数,可以很清楚的理解这个类中的方法在干什么,而不是像接口那样直接就生成了一个接口的实体对象,但是这样既不利于我们自己写代码,也不利于修改。
接口和接口的实现类好处是什么,想修改接口中的方法直接改实现类就行(没有实现类的也会对应一个xml配置文件,直接在xml文件中作修改就可以),而不是在一个实体类中慢慢修改。
18.为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发 生一次?
处理异常,我碰到的最多的是要判断返回值为空的情况,JDBC中的Class.for.name以及创建statement后都要有一个异常捕获,如果不捕获这个异常那么这个程序就会报错,IDEA很智能,都直接会提示该方法需要一个try&catch环绕。
Try&Catch的使用,我自己完成的任务一中,在dao层为了完成任务一的要求返回值的时候抛出了异常,这样就需要在下一级也就是service层队之前的异常进行捕获,try你要执行的dao接口的方法,如果该语句执行成功则返回true,然后catch异常,如果该语句执行失败则执行catch中的false,另外可以在最后加上finally,我在日志logger输出中同样使用的是try&catch来输出,这样可以准确定位到底是哪步出了错误。
真实系统中,会不会出现网络中断,网上师兄的答案:正常情况下mysql对于空闲的连接可能会8小时自动关闭。我觉得这里有点问题,按理说对于一个需要被频繁查询的数据来讲连接应该永远不被关闭,那么这个中断错误是mysql中内置的规定?然后会重连?
19.日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
之前回答过了,我觉得在我自己做的任务一中在测试类中打出几个方法是否成功执行即可。
20.为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
单步调试,可以获得每一步的返回值,我自己没有真正应用Debug模式,对这里理解还是有点模糊,希望做以后几个任务的时候可以多用用这个。
21.可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
我觉得不可以链接到线上直接调试,要在本地确认好除了连接部分其他地方都不报错的时候在放到线上调试,真实项目中遇到问题应该按日志排查错误。
ps:代码链接贴上去了师兄能看到么




评论