发表于: 2018-03-26 20:55:32
2 407
今天完成的事情:
1, 补全深度思考
2, 测试关闭DB情况下,是否报错
3, 整理代码
深度思考:
1. maven是什么,和Ant有什么区别?
Maven是一个软件项目管理以及自动构建工具,是居于项目对象模型(POM)概念,能够利用一个中央信息片段管理一个项目的构建、报告和文档等步骤。
Ant是一个将软件编译、测试、部署等步骤联系在一起加以自动化的一个工具,大多用于java环境中的软件开发。默认情况下,他的buildfile名为build.xml
Ant为java技术开发项目提供跨平台构建任务,Maven本身描述项目的高级方面,它从Ant借用了绝大多数构建项目。
2. clean,install,package,deploy分别代表什么含义?
Maven clean 清除项目目录中的生成结果
Maven install 在本地Repository中安装jar
Maven package 根据项目生成jar
Maven deploy 在整合或者发布环境下执行,将最终版本的包拷贝到远程的repository,使得其他的开发者或者工程可以共享
3. 怎么样能让Maven跳过JUnit?
使用Surefire插件的skip参数,添加maven.test.skip参数即可。
4. 为什么要用Log4j来替代System.out.println?
System.out.println只能输出到控制台,而log4j之类的日志工具可以配置输出目标,输出等级,减少输出形式与程序的耦合。
5. 为什么DB的设计中要使用Long来替换掉Date类型?
Long类型方便计算
6. 自增ID有什么坏处?什么样的场景下不使用自增ID?
不存在连续性,数据重复了自增不会处理和提示,在面向对象时,不能保证完整性,分库的时候id就不唯一了。
7.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
数据库就像一本字典一样,原来你搜索数据的时候需要一页页翻。而给某个字段建索引就是把这个字段的数据都放到一起,然后写好对应的数据在第几页。这样再搜索的时候就只要翻这几页就可以了。速度自然快。
8.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
普通索引允许被索引的数据列包含重复的值,唯一索引保证数据记录的唯一性
9.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
MySQL会在有新记录插入数据表时,自动检查新记录的这个字段的值是否已经在某个记录的这个字段里出现过了;如果是,MySQL将拒绝插入那条新记录。
10.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
Createat是在创建用户时赋值,updateat是在更改用户信息时赋值。Updateat可以考虑开放给外部调用的接口。
11.修真类型应该是直接存储Varchar,还是应该存储int?
根据修真类型的案例,都是字符串,应该是存储varchar。
12.varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
在 MySQL5.0以上的版本中,varchar数据类型的长度支持到了65535,也就是说可以存放65532个字节的数据,起始位和结束位占去了3个字 节,也就是说,在4.1或以下版本中需要使用固定的TEXT或BLOB格式存放的数据可以使用可变长的varchar来存放,这样就能有效的减少数据库文 件的大小。MySQL 数据库的varchar类型在4.1以下的版本中,nvarchar(存储的是Unicode数据类型的字符)不管是一个字符还是一个汉字,都存为2个字节 ,一般用作中文或者其他语言输入,这样不容易乱码 ;varchar: 汉字是2个字节,其他字符存为1个字节 ,varchar适合输入英文和数字。
4.0版本以下,varchar(20),指的是20字节,如果存放UTF8汉字时,只能存6个(每个汉字3字节) ;5.0版本以上,varchar(20),指的是20字符,无论存放的是数字、字母还是UTF8汉字(每个汉字3字节),都可以存放20个,最大大小是65532字节 ;varchar(20)在Mysql4中最大也不过是20个字节。
varchar text longtext区别:
从存储上讲:
text 是要要进overflow存储。 也是对于text字段,不会和行数据存在一起。但原则上不会全部overflow ,会有768字节和原始的行存储在一块,多于768的行会存在和行相同的Page或是其它Page上。
varchar 在MySQL内部属于从blob发展出来的一个结构,在早期版本中
innobase中,也是768字节以后进行overfolw存储。
对于Innodb-plugin后: 对于变长字段处理都是20Byte后进行overflow存
储(在新的row_format下:dynimic compress)
2.从最大值上讲:
在Innobase中,变长字段,是尽可能的存储到一个Page里,这样,如果使用到这些大的变长字段,会造成一个Page里能容纳的行
数很少,在查询时,虽然没查询这些大的字段,但也会加载到innodb buffer pool中,等于浪费的内存。
(buffer pool 的缓存是按page为单位)(不在一个page了会增加随机的IO)
在innodb-plugin中为了减少这种大的变长字段对内存的浪费,引入了大于20个字节的,都进行overflow存储,
而且希望不要存到相同的page中,为了增加一个page里能存储更多的行,提高buffer pool的利用率。 这也要求我们,
如果不是特别需要就不要读取那些变长的字段。
那问题来了? 为什么varchar(255+)存储上和text很相似了,但为什么还要有varchar, mediumtext, text这些类型?
(从存储上来讲大于255的varchar可以说是转换成了text.这也是为什么varchar大于65535了会转成mediumtext)
我理解:这块是一方面的兼容,另一方面在非空的默认值上varchar和text有区别。从整体上看功能上还是差别的。
这里还涉及到字段额外开销的:
varchar 小于255byte 1byte overhead
varchar 大于255byte 2byte overhead
tinytext 0-255 1 byte overhead
text 0-65535 byte 2 byte overhead
mediumtext 0-16M 3 byte overhead
longtext 0-4Gb 4byte overhead
备注 overhead是指需要几个字节用于记录该字段的实际长度。
从处理形态上来讲varchar 大于768字节后,实质上存储和text差别不是太大了。 基本认为是一样的。
另外从8000byte这个点说明一下: 对于varcahr, text如果行不超过8000byte(大约的数,innodb data
page的一半) ,overflow不会存到别的page中。基于上面的特性可以总结为text只是一个MySQL扩展出
来的特殊语法有兼容的感觉。
3.从默认值上讲:
于text字段,MySQL不允许有默认值。
varchar允许有默认值
总结:
根据存储的实现: 可以考虑用varchar替代tinytext
如果需要非空的默认值,就必须使用varchar
如果存储的数据大于64K,就必须使用到mediumtext , longtext
varchar(255+)和text在存储机制是一样的
需要特别注意varchar(255)不只是255byte ,实质上有可能占用的更多。
特别注意,varchar大字段一样的会降低性能,所以在设计中还是一个原则大字段要拆出去,主表还是要尽量的瘦小
13.怎么进行分页数据的查询,如何判断是否有下一页?
1,LIMIT
2,NOT IN
3,MAX
4,ROE_NUMBER
判断是否有下一页:先获取数据总条数,根据每页显示的数据计算出总页数,然后就可以判断是否为最后一页。
14.为什么不可以用Select * from table?
调用命令,会解析更多的对象,字段,权限,属性县官,对资源的极大浪费,对优化和效率,以及对服务器的性能产生一定影响。
15.什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
贫血模型:是指领域对象里只有get和set方法,或者包含少量的CRUD方法,所有的业务逻辑都不包含在内而是放在Business Logic层。
优点是系统的层次结构清楚,各层之间单向依赖,Client->(Business Facade)->Business Logic->Data Access(ADO.NET)。当然Business Logic是依赖Domain Object的。似乎现在流行的架构就是这样,当然层次还可以细分。
该模型的缺点是不够面向对象,领域对象只是作为保存状态或者传递状态使用,所以就说只有数据没有行为的对象不是真正的对象。在Business Logic里面处理所有的业务逻辑,在POEAA(企业应用架构模式)一书中被称为Transaction Script模式。
充血模型:层次结构和上面的差不多,不过大多业务逻辑和持久化放在Domain Object里面,Business Logic只是简单封装部分业务逻辑以及控制事务、权限等,这样层次结构就变成Client->(Business Facade)->Business Logic->Domain Object->Data Access。
它的优点是面向对象,Business Logic符合单一职责,不像在贫血模型里面 那样包含所有的业务逻辑太过沉重。
缺点是如何划分业务逻辑,什么样的逻辑应该放在Domain Object中,什么样的业务逻辑应该放在Business Logic中,这是很含糊的。即使划分好了业务逻辑,由于分散在Business Logic和Domain Object层中,不能更好的分模块开发。熟悉业务逻辑的开发人员需要渗透到Domain Logic中去,而在Domian Logic又包含了持久化,对于开发者来说这十分混乱。 其次,因为Business Logic要控制事务并且为上层提供一个统一的服务调用入口点,它就必须把在Domain Logic里实现的业务逻辑全部重新包装一遍,完全属于重复劳动。
16.Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
使一个对象依赖其他对象时通过被动的方式传入进来,而不是手动创建,解耦,交由第三方创建。
17.为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
产生一个完全抽象的类,可以方便解耦。
18.为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发 生一次?
需要保证程序的健壮性,将错误进行区分,再汇报。
出现异常,更换逻辑或者提示错误,保证正常退出。
19.日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
把某一类的日志单独输出到某个文件中,以达到某一类的操作,对应相应的日志文件。
打印日志的目的一般有两个:定位问题和显示程序运行状态。
记录日志时机:编程语言提示异常,业务流程预期不符,系统核心角色、组建关键动作,系统初始化。
日志内容:时间,日志级别,会话标识,功能标识,精炼的内容,其他信息。
20.为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
为了寻找程序中的bug,一步一步跟踪程序执行的流程,更具变量的值,找出错误的原因。
21.可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
Idea可以通过tomcat对线上项目进行调试
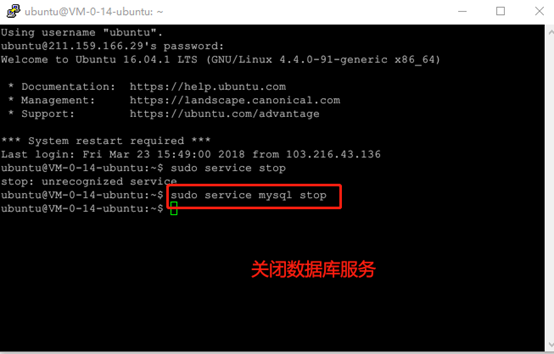
运行程序
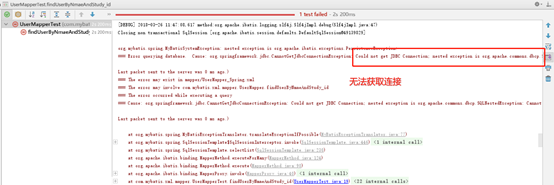
明天计划完成的事情:
1, 开始任务二
2, 任务一如若有遗漏项的话,补全。
遇到的问题:
收获:深度思考大部分是网络所找,不是特别清楚,日后希望多多熟悉。以及通过断断续续半个月的学习,算是对spring,mybatis等有了一个相对粗浅的认识,还有很多不规范的地方,希望以后能慢慢养成良好的习惯。




评论