发表于: 2018-03-25 23:49:41
2 456
今天完成的事情:(
1.今天看了下mybatis的源码
Configuration.xml:该配置文件是MyBatis的全局配置文件,在这个文件中可以配置诸多项目,但是一般项目中,并不会配置太多内容,常用的内容是别名设置,拦截器设置等,至于环境设置与Mapper映射文件的注册会转移到Spring配置文件中(SSM整合之后),而其余大部分的配置项都采用默认的配置。
XMLConfigBuilder:该类是XML配置构建者类,是用来通过XML配置文件来构建Configuration对象实例,构建的过程就是解析Configuration.xml配置文件的过程,期间会将从配置文件中获取到的指定标签的值逐个添加到之前创建好的默认Configuration对象实例中。
Configuration:该类是MyBatis的配置类,创建这个类的目的就是为了使用其对象作为项目全局配置对象,这样通过配置文件配置的信息可以保存在这个配置对象中,而这个配置对象在创建好之后是保存在JVM的Heap内存中的,方便随时读取。不然每次需要配置信息的时候都要临时从磁盘配置文件中获取,代码复用性差的同时,也不利于开发。
SqlSessionFactoryBuilder:该类是SqlSessionFactory(会话工厂)的构建者类,之前描述的操作其实全是从这里面开启的,首先就是调用XMLConfigBuilder类的构造器来创建一个XML配置构建器对象,利用这个构建器对象来调用其解析方法parse()来完成Configuration对象的创建,之后以这个配置对象为参数调用会话工厂构建者类中的build(Configuration config)方法来完成会话工厂对象的构建。
SqlsessionFactory:该接口是会话工厂,是用来生产会话的工厂接口,DefaultSqlSessionFactory是其实现类,是真正生产会话的工厂类,这个类的实例的生命周期是全局的,它只会在首次调用时生成一个实例(单例模式),就一直存在直到服务器关闭。
openSession():在最后的build(Configuration config)方法中会返回一个DefaultSqlSessionFactory类的实例,这个类是MyBatis提供的默认会话工厂类,而我们使用的也正是这个类中的来openSession()方法来完成SqlSession对象的创建。
SqlSession:该接口是会话,是项目与数据库之间的会话,类似于客户端与服务器之间的会话(session),这个SqlSession的生命周期是方法级的,因为他是非线程安全的,针对每一次数据库访问都要创建一个SqlSession,获取到返回结果之后,这个SqlSession就会被废弃。这区别于SqlSessionFactory的生命周期。
Executor:执行器接口,SqlSession会话是面向程序员的,而内部真正执行数据库操作的却是Executor执行器,可以将Executor看作是面向MyBatis执行环境的,SqlSession就是门面货,Executor才是实干家。通过SqlSession产生的数据库操作,全部是通过调用Executor执行器来完成的。
StatementHandler:该类是Statement处理器,封装了Statement的各种数据库操作方法execute(),可见MyBatis其实就是将操作数据库的JDBC操作封装起来的一个框架,同时还实现了ORM罢了。
ResultSetHandler:结果集处理器,如果是查询操作,必定会有返回结果,针对返回结果的操作,就要使用ResultSetHandler来进行处理,这个是由StatementHandler来进行调用的。这个处理器的作用就是对返回结果进行处理。
2.整合spring +mybatis的时候 
用的 Mapper开发方式配置
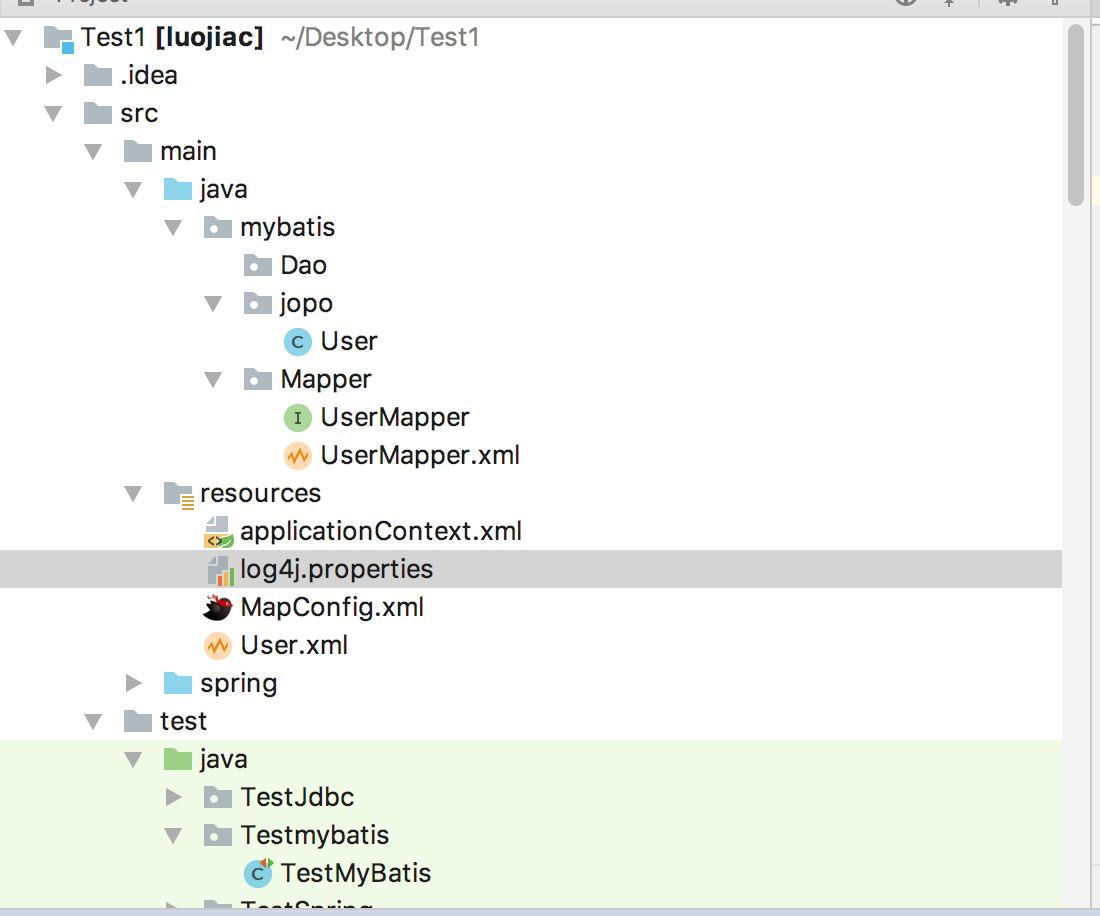
百度后说是 idea无法读取放在scr其他包里的xml文件
需要加在pom中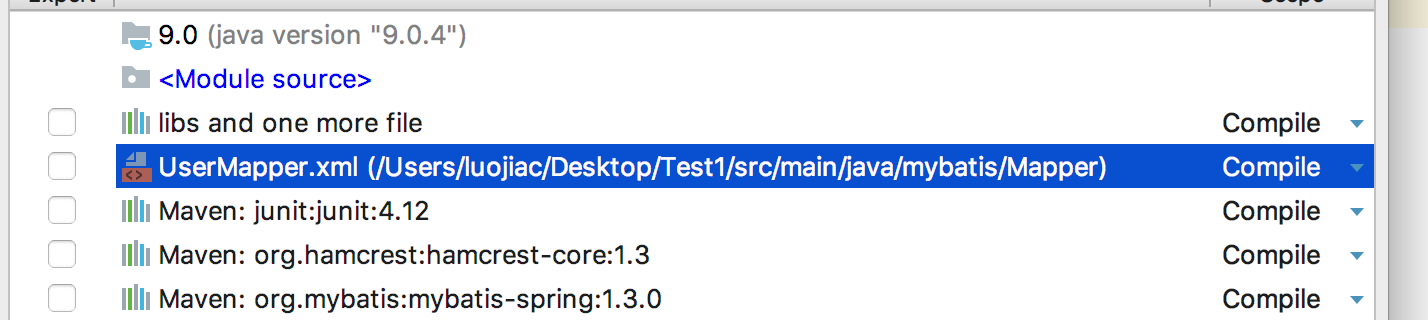
然而也没什么用
如果把UserMapper.xml放在resoure中的话。mybatis的配置文件能读到 但是UserMapper和 UserMapper不放在一起就无法被spring扫描出来
搜一了一下说是idea的bug 上面的办法也没成功
3.然后我尝试用原始DAO开发方式来整合
提示无效版本 5
我觉得可能是我jar包有问题。明天重新整理一下。
4.继续做深度思考
自增ID有什么坏处?什么样的场景下不使用自增ID?
<1.自增id不存在连续性
比如删掉id (3) 那么3就没有了
数据重复了不会提示 因为id没重复
在面对对象时不能保证完整性。
分库的时候ID就不唯一了
<2如果有其他唯一标识该行数据的列,就不用设置自增id了。
在做分布式数据库的时候,要求同步自增id就会出现严重的问题
5.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
1.索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。
索引的一个主要目的就是加快检索表中数据的方法,亦即能协助信息搜索者尽快的找到符合限制条件的记录ID的辅助数据结构。
2.100万?
3.字段为主键时
6.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
普通索引
普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。
因此,应该只为那些最经常出现在查询条件(WHEREcolumn=)或排序条件(ORDERBYcolumn)中的数据列创建索引。
只要有可能,就应该选择一个数据最整齐、最紧凑的数据列(如一个整数类型的数据列)来创建索引。
唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
在对该列进行增或改时,首先会检查是否重复,在执行增改操作,否则报出duplica错误,拒绝操作。
7. 如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
影响性能。可以在插入语句后加ON DUPLICATE KEY UPDATE 添加了唯一索引的字段名 = VALUES(添加了唯一索引的字段名) 然后判断他的返回值
)
明天计划的事情:(整合!)
遇到的问题:(对spring不够了解)
收获:(通过今天的学习,学到了什么知识)




评论