发表于: 2018-03-25 23:19:27
1 440
今天完成的事情:(一定要写非常细致的内容,比如说学会了盒子模型,了解了Margin)
一、唯一索引
1.添加索引可以增加数据的查询速度,所以在经常需要查询的数据上可以选择添加索引,而唯一索引要求里面的内容不能有重复,否则就会报错
试验一下,首先在姓名栏添加唯一索引

然后在主程序先插入一条信息,再插入循环使得循环插入的信息中包含第一条姓名
public class Main {
public static void main(String[] args)throws Exception {
//创建logger对象,方便使用log功能
Logger logger=Logger.getLogger(Main.class);
//先增加一条数据并返回结果
PersonService personService = new PersonServiceImpl();
Person person = new Person(System.currentTimeMillis(),"wangxiao45", 25, "20111555");
Map<String,Object> parms=new HashMap<>();
parms.put("name","wang");
List<Person> people=personService.addAndList(person,parms);
for(Person p1:people){
logger.info(p1);
}
//利用循环插入100条数据,因为唯一索引姓名不能重复,所以增加try-catch捕捉异常
try{
for(int i=0;i<100;i++){
person=new Person(System.currentTimeMillis(),"wangxiao"+i,28,"2017777"+i);
logger.debug(personService.justAdd(person));//执行插入并返回插入后id
}
}catch(Exception e){
logger.info(e.getMessage());
logger.error("插入失败,姓名有重复");
}
//重置表格
// personService.deleteAll();
System.out.println("程序已运行结束");
}
}
结果如下
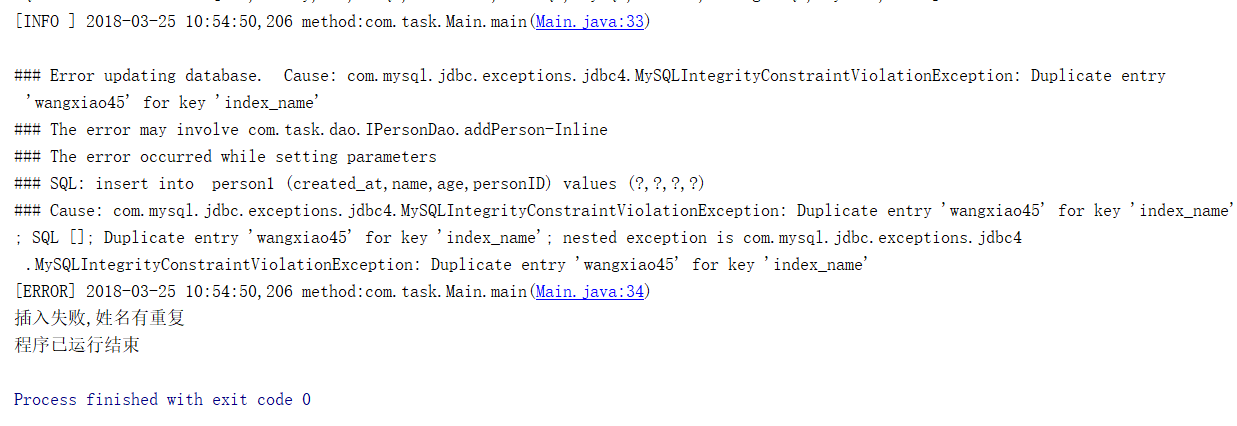
当因为唯一索引重复而发生Expection时,系统会自动退出try语句,而去执行catch语句中的内容,即输出错误具体信息,和定义的错误语句,然后跳出try-catch继续进行下一步。
可以看到唯一索引会在插入前自动判断插入的内容是否重复,如果重复就会 报错,此时,需要使用try-catch语句来处理,否则就无法运行后面的步骤,所以为了预防出现错误,最好在这种地方使用try-catch进行异常捕捉以防出现错误。类似的还有Update语句,因为更新信息时也涉及到姓名,而删除语句,查询语句则不需要。
将增删查改都写进主程序测试一遍
public class Main {
public static void main(String[] args)throws Exception {
//创建logger对象,方便使用log功能
Logger logger=Logger.getLogger(Main.class);
//先增加一条数据并返回结果
PersonService personService = new PersonServiceImpl();
Person person = new Person(System.currentTimeMillis(),"wangxiao", 25, "20111555");
Map<String,Object> parms=new HashMap<>();
parms.put("name","wang");
List<Person> people=personService.addAndList(person,parms);
for(Person p1:people){
logger.info(p1);
}
//利用循环插入100条数据,因为唯一索引姓名不能重复,所以增加try-catch捕捉异常
try{
for(int i=0;i<100;i++){
person=new Person(System.currentTimeMillis(),"wangxiao"+i,28,"2017777"+i);
logger.debug(personService.justAdd(person));//执行插入并返回插入后id
}
}catch(Exception e){
logger.info(e.getMessage());
logger.error("插入失败,姓名有重复");
}
//利用循环修改数据,因为修改数据涉及姓名所以也需要使用try-catch语句
try{
for (int i=0;i<105;i++){
person=new Person(i,System.currentTimeMillis(),"lisi"+i,25,"2018"+i);
if (personService.justUpdate(person)){
logger.debug("更新成功");
}else
logger.info("修改失败,无此条信息可以修改");
}
}catch (Exception e){
logger.error(e.getMessage());
logger.error("修改失败,姓名重复");
}
//利用循环删除信息,并返回目前表的信息
for (int i=5;i<105;i++){
if (personService.justDelete(i)){
logger.debug("第"+i+"条信息删除成功");
}else
logger.info("删除信息不存在,请查证后再删除");
}
Map parm=new HashMap();
List<Person> list=personService.justList(parm);
for(Person p1:list) {
System.out.println(p1);
}
//重置表格
personService.deleteAll();
System.out.println("程序已运行结束");
}
}
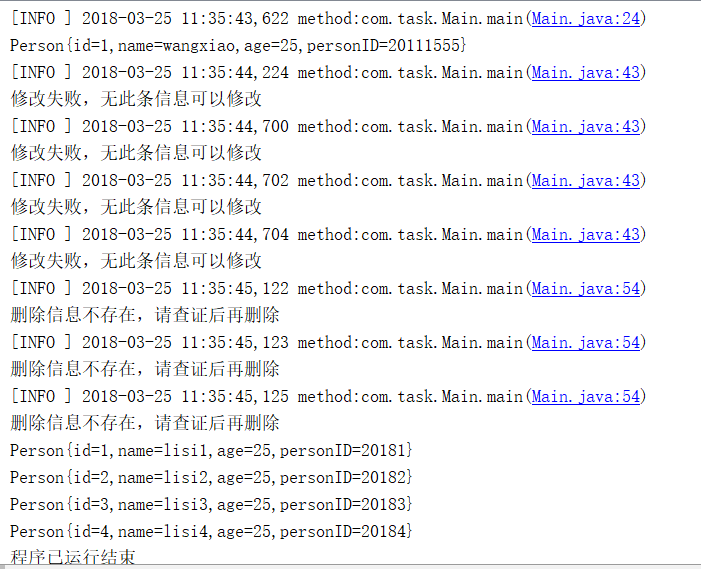
可以看到,是否有问题一目了然,对于运行成功这种经常出现的且不需要格外重视的结果,可以使用logger.debug()来输出,而失败的结果则需呀引起注意所以使用logger.info()。至于发生的错误更是要重视,所以使用logger.error().这里需要注意删除,修改操作如果对象为空是不发生错误,只是操作不成功返回值变为false而已。
二、泛型
1.当不使用泛型时,存储在某个集合中的类可以是多种多样的,当我们需要某个取出来时,需要对其进行类型的强制转换,这样就会降低程序的安全性和可读性。
2.当我们使用泛型后,则该集合就只能存储被声明过的类型和其子类,其余的类无法放进去,这样做不仅提高了程序的可读性,因为我们一眼就能知道集合中存储的是什么类型的数据,而且取出数据时不需要对其进行强制转换,所以也提高了其安全性。
3.语法 ArrayList<Type> type=new ArrayList<Type可省略>();其中Type可以存放类,抽象类,或是接口。
4.通配符
①.通配符ArrayList<? extends Type> type=new ArrayList<>();表示此中存放的泛型可能为Type,或是其任意子类,因此从type中取出来的对象一定可以转型为Type,因为向上转型一定是成功的,但是不能向type中添加新的对象,因为不能保证type中到底是什么类型的,所以添加对象可能会发生错误。
②.通配符ArrayList<? super Type> type=new ArrayList<>();表示此中存放的泛型可能为Type或者其父类,所以可以往其中插入Type及其子类,但是不能从其中取出数据,因为如果是父类的对象被取出来强转为Type类就会失败。
③.通配符ArrayList<?> type=new ArrayList<>();因为泛型类型是?,所以可以是Object及其所有子类,因此无法插入,因为不知道是哪个子类,而要取出也就只能强转为Object类型的对象才可以。
④.综上所述,
当我们希望只取出不添加,就可以用? extents Type;
当我们希望只添加不取出,就可以用? super Type;
如果我们希望又能取出又能添加,就不要用通配符?
5.虽然子类对象可以转化为父类对象,但是子类和父类泛型无法相互转化。因为主要是泛型里面存的还包括子类,不能只看到表面上这个类。
比如说ArrayList<Object> arrayList1=new ArratList<>();
arrayList1.add(new Object);
ArrayList<String> arrayList2=arrayList1;
此时,第三行语句会编译错误,因为如果没有错误的话,当调用arrayList2.get()只能返回String对象,但是实际上arrayList1中还有Object对象,所以就会出现ClassCastException.
第二种ArrayList<String> arrayList1=new ArratList<>();
arrayList1.add(new String);
ArrayList<Object> arrayList2=arrayList1;
此方法也会编译报错,虽然取出时不会有影响,可是,这样做有什么意义呢,泛型出现的原因,就是为了解决类型转换的问题。我们使用了泛型,到头来,还是要自己强转,违背了泛型设计的初衷。所以java不允许这么干。
6.泛型类型变量不能是基本数据类型
7.泛型类中的静态方法和静态变量不可以使用泛型类所声明的泛型类型参数。因为泛型类中的泛型参数的实例化是在定义泛型类型对象(例如ArrayList<Integer>)的时候指定的,而静态变量和静态方法不需要使用对象来调用。对象都没有创建,如何确定这个泛型参数是何种类型,所以当然是错误的。
8.在编译期间,所有的泛型信息都会被擦除,List<Integer>和List<String>类型,在编译后都会变成List类型(原始类型)。Java中的泛型基本上都是在编译器这个层次来实现的,这也是Java的泛型被称为“伪泛型”的原因。
三、贫血模型,充血模型
1.贫血模型是指Model中只有基本的成员变量(属性)和它们对应的get/set方法,却不包括具体方法(行为),采用这种设计时,需要分离出DB层,专门用于数据库操作。即在基本的pojo上面要有Dao层,只包含CURD等基本方法的接口类和重写接口类中方法的实现类,再上面是Service层,来进行基本的逻辑业务操作。
2.充血模型是指Model中不仅有基本的成员变量还有具体方法,所以说充血方法是更符合面向对象思想的。其只有包含了属性和方法的Model层和具体实现的Service层。
3.贫血模型优点是系统的层次结构清楚,各层之间单向依赖。缺点是不够面向对象。
充血模型优点是面向对象,Business Logic符合单一职责,不像在贫血模型里面那样包含所有的业务逻辑太过沉重。缺点是比较复杂,对技术要求更高。
所以,如果可以,还是应该尽量使用贫血模型来写代码,这样代码逻辑层面上比较干净清楚,但是,充血模型毕竟是最符合面向对象编程这一特点,所以也有其独特之处,理解两种方法的内涵之后,看情况选择才是最好的。
四、关于单元测试
1.单元测试(unit testing),是指对软件中的最小可测试单元进行检查和验证。对于单元测试中单元的含义,一般来说,要根据实际情况去判定其具体含义,如C语言中单元指一个函数,Java里单元指一个类,图形化的软件中可以指一个窗口或一个菜单等。总的来说,单元就是人为规定的最小的被测功能模块。单元测试是在软件开发过程中要进行的最低级别的测试活动,软件的独立单元将在与程序的其他部分相隔离的情况下进行测试。
2.单元测试(模块测试)是开发者编写的一小段代码,用于检验被测代码的一个很小的、很明确的功能是否正确。通常而言,一个单元测试是用于判断某个特定条件(或者场景)下某个特定函数的行为。
3.Bug发现的越晚,修改它所需的费用就越高,因此从经济角度来看, 应该尽可能早的查找和修改Bug。在修改费用变的过高之前,单元测试是一个在早期抓住Bug的机会。
4.相比后阶段的测试,单元测试的创建更简单,维护更容易,并且可以更方便的进行重复。从全程的费用来考虑, 相比起那些复杂且旷日持久的集成测试,或是不稳定的软件系统来说,单元测试所需的费用是很低的。
5.请牢记这一条 JUnit 最佳实践:测试任何可能的错误。单元测试不是用来证明您是对的,而是为了证明您没有错。
明天计划的事情:(一定要写非常细致的内容)
1.研究在服务器上面布置相关配置
2.在服务器上跑通流程
遇到的问题:(遇到什么困难,怎么解决的)
发现对一些小知识点的掌握还不是很好,只能慢慢查漏补缺了
收获:(通过今天的学习,学到了什么知识)
1.体会到牵涉唯一索引时在进行CRUD操作时需要注意的点
2.详细感受了try-catch捕捉到异常后的流程顺序
3.了解了泛型的作用以及转换规则
4.了解了贫血充血模型及其优缺点
5.对单元测试必要性有了更直观的认识




评论