发表于: 2018-03-23 23:19:15
1 582
今天完成的事情:(一定要写非常细致的内容,比如说学会了盒子模型,了解了Margin)
一、try-catch
1.导致程序的正常流程被中断的事件,叫做异常。
2.当某一操作可能会导致异常发生时,即使用户明知一定不会发生异常,但是也得设定一定的手段来避免异常出现,否则编译器就会编译失败,在idea等编程软件中就会发现有错误提醒。
3.异常处理常见手段try catch finally throw
try
{
//1
code that might throw exception;
//2
}
catch (Exception e)
{
//3
show error message;
//4
}
finally
{
//5
in.close();
}
//6
4.①将需要执行的代码放在try中,若无异常发生,则执行完try中的语句之后转到finally中执行其中的语句,然后跳到try语句块之后继续执行,即上面的1256步;
②若在执行try中语句时抛出一个在catch子句中捕获的异常,则立即终止try中的执行语句,跳到catch子句中执行其中代码,若catch子句没有抛出异常,则执行13456步骤,若catch子句抛出异常,则执行135步骤;
③若在执行try中语句时抛出一个不是由catch捕获的异常,则会跳过try中剩余语句直接执行finally语句,即只执行15步
5.try语句可以只有catch语句也可以只有finally语句,finally语句中一般放断开连接的操作,以保证无论是否有异常,连接都会被中断,防止过度占用系统资源,因为finally中的操作无论是否有异常最后都会执行。
6.当捕捉异常时,catch中可以使用具体异常,亦可以使用父类异常即Expection来捕捉异常。
7.当可能抛出多种异常时,可以使用以下两种方法
①try
{
code that might throw exception;
}
catch(xxxException e)
{
show error message;
}
catch(yyyException e)
{
show error message;
}
②try
{
code that might throw exception;
}
catch(xxxException |yyyException e)
{
show error message;
}
方法②的代码更紧凑简洁,只是在抛出异常后若想知道异常种类就需要使用instance of来判断。
但是为了方便,一般直接使用父类Exception直接全部捕捉就好。。。
8.throw和throws
throw:抛出一个异常,一般在代码块内部
throws:一个方法可能抛出的异常,一般在方法声明中
9.异常分类:可查异常,运行时异常,错误
其中Throwable为父类,所以亦可以使用它来进行异常捕捉,但是子类却不能捕捉父类的异常
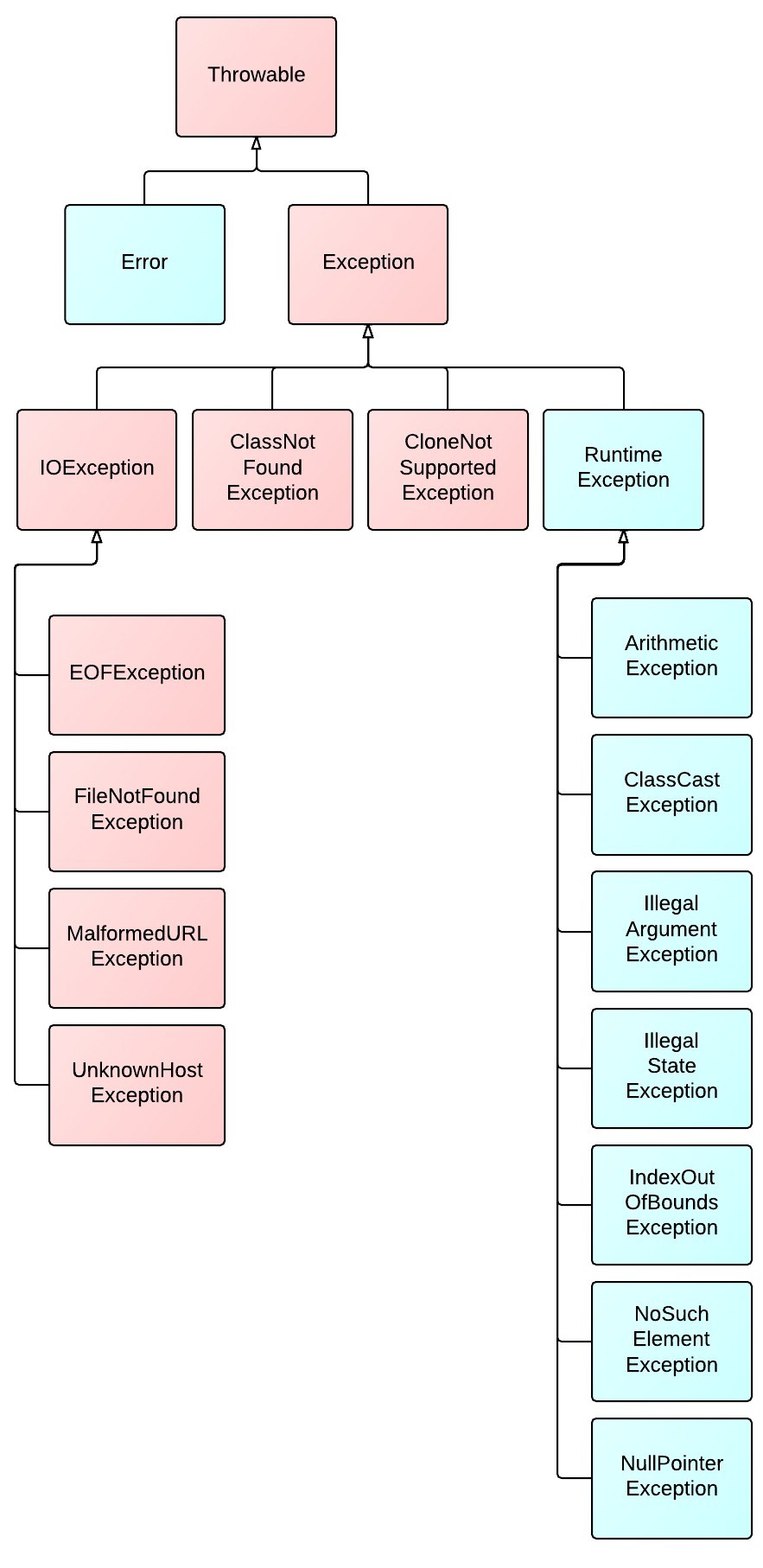
可查异常(粉色):在编译过程中编译器会检查的,在预料之内的异常,所以对于可能发生此异常的情况,编译器会要求我们进行预处理,即try-catch捕获或者直接throws抛出异常
运行时异常(蓝色):不是必须进行异常处理,即使不进行异常处理也不会产生编译错误,而是需要才需要自己去判断的异常,比如除数为0,空指针异常,下标越界等,为了程序代码的可读性,一般是不去做异常处理,真的遇到异常再报错。
错误:系统级别的异常,一般会使得内存被用完或者内部错误等,也不要求进行捕捉
10.带资源的try语句(try-with-resources)
try(Resource res=...)
{
work with res;
}
try退出时,会自动调用res.close,是对finally来关闭连接的一个优化,在前面的jdbc中就是用此方法
11.自定义异常类
定义的类派生于Exception或者其子类,其中应该包含两个构造器,一个是默认的构造器,一个是带有详细信息的构造器,在发生异常时,可以使用e.getMessage()来获知发生的异常的详细信息,方便调试
12.分析堆栈轨迹元素
堆栈轨迹(stack trace)是一个方法调用过程的列表,它包含了程序执行过程中方法调用的特定位置。
一般可以调用Throwable中的printStackTrace方法访问堆栈轨迹的文本描述信息。
13.使用异常机制的技巧
①异常处理不能代替简单的测试,应该只在异常情况下使用异常机制。
②不要过分细化异常,一些能合并的地方尽量合并
③利用异常层次结构,能使用子类尽量使用子类,否则代码会更难读,更难维护
④不要压制异常
⑤在检测异常时,“苛刻”要比放任更好,抛出趁早
⑥不要羞于传递异常,捕获宜晚
二、断言
1.断言机制允许在测试期间向代码中插入一些检查语句。当测试完毕,代码发布时,这些插入的检测语句将会被自动地移走。断言只应该用于在测试阶段确定程序内部的错误位置。
2.java中一般使用关键字assert,其有两种形式:
①assert 条件;
这里condition是一个必须为真(true)的表达式。如果表达式的结果为true,那么断言为真,并且无任何行动。如果表达式为false,则断言失败,则会抛出一个AssertionError对象。这个AssertionError继承于Error对象
②assert 条件:表达式;
这里condition是和上面一样的,这个冒号后跟的是一个表达式,通常用于断言失败后的提示信息,说白了,它是一个传到AssertionError构造函数的值,如果断言失败,该值被转化为它对应的字符串,并显示出来。
三、连接池
1.传统连接方式每个线程建立一次连接,使用完毕就关闭,由于开启和关闭都很废时间,所以多线程并发的时候,会大量占用系统资源导致卡顿等情况,而且连接数目是有限的,当总数被用完,后续的连接就会失败。
2.与传统方式不同,连接池在使用之前,就会创建好一定数量的连接。如果有任何线程需要使用连接,那么就从连接池里面借用,而不是自己重新创建。使用完毕后,又把这个连接归还给连接池供下一次或者其他线程使用。倘若发生多线程并发情况,连接池里的连接被借用光了,那么其他线程就会临时等待,直到有连接被归还回来,再继续使用。整个过程,这些连接都不会被关闭,而是不断的被循环使用,从而节约了启动和关闭连接的时间。
3.几个基本概念:
最小连接——应用启动后随即打开的连接数以及后续最小维持的连接数
最大连接数——应用能够使用的最多连接数
连接增长数——应用每次新打开的连接个数
4.例子:假设设置了最小和最大的连接为10,20,那么应用一旦启动则首先打开10个数据库连接,但注意此时数据库连接池的正在使用数字为0--因为你并没有使用这些连接,而空闲的数量则是10。然后你开始登录,假设登录代码使用了一个连接进行查询,那么此时数据库连接池的正在使用数字为1、空闲数为9,这并不需要从数据库打开连接--因为连接池已经准备好了10个给你留着呢。登录结束了,当前连接池的连接数量是多少?当然是0,因为那个连接随着事务的结束已经返还给连接池了。然后同时有11个人在同一秒进行登录,会发生什么:连接池从数据库新申请(打开)了一个连接,连同另外的10个一并送出,这个瞬间连接池的使用数是11个,不过没关系正常情况下过一会儿又会变成0。如果同时有21个人登录呢?那第21个人就只能等前面的某个人登录完毕后释放连接给他(相当于游戏服务器登陆人数过多时需要排队的原理)。这时连接池开启了20个数据库连接--虽然很可能正在使用数量的已经降为0,那么20个连接会一直保持吗?当然不,连接池会在一定时间内关闭一定量的连接还给数据库,在这个例子里数字是20-10=10,因为只需要保持最小连接数就好了,而这个时间周期也是连接池里配置的。
5.几款常用连接池简单比较
①dbcp,配置方便,开源,使用最多,基本功能都有,稳定性还行,速度稍慢,大并发量时性能会下降,无法提供连接池监控。
②c3p0,开源,基本功能都有,稳定性很好,大并发量下稳定性也不错,无法提供连接池监控。三种中比较推荐
③proxool,开源,使用较少,基本功能都有,稳定性有一定问题,相比另外两个容易出现错误,但是!提供连接池监控!
6.以下为使用阿里巴巴的Druid进行数据连接池配置
简介:Druid与其他数据库连接池使用方法基本一样(与DBCP非常相似),将数据库的连接信息全部配置给DataSource对象,阿里巴巴推出的国产数据库连接池,据网上测试对比,比目前的DBCP或C3P0数据库连接池性能更好。
<!-- 连接jdbc数据库所需要的数据信息-->
<bean name="dataSource" class="com.alibaba.druid.pool.DruidDataSource"
init-method="init" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://127.0.0.1:3306/test"/>
<property name="username" value="root"/>
<property name="password" value="1024"/>
<!--初始连接数-->
<property name="initialSize" value="1" />
<!--最小连接数-->
<property name="minIdle" value="5" />
<!--最大连接数-->
<property name="maxActive" value="20" />
<!-- 配置获取连接等待超时的时间 -->
<property name="maxWait" value="60000" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="300000" />
<!--用来检测是否有效的sql,要求为查询语句-->
<property name="validationQuery" value="SELECT 'x'" />
<!--宕机时申请检测,不会影响性能-->
<property name="testWhileIdle" value="true" />
<!--申请连接时检测连接是否有效,会影响性能-->
<property name="testOnBorrow" value="false" />
<!--归还连接时检测连接是否有效,会影响性能-->
<property name="testOnReturn" value="false" />
<!-- 打开PSCache,对支持游标的数据库性能提升巨大 -->
<property name="poolPreparedStatements" value="true" />
<!--打开PSCache后配置其连接数量-->
<property name="maxPoolPreparedStatementPerConnectionSize" value="20" />
<!-- 配置监控统计拦截的filters -->
<property name="filters" value="stat" />
</bean>
然后测试一下开连接池的情况下和不开连接池的情况下同样插入10000条数据的差别,下为main函数
public class Main {
public static void main(String[] args)throws Exception {
//增加信息并返回新增加的id
PersonService ps=new PersonServiceImpl();
//设置起始时间t1
long t1=System.currentTimeMillis();
for(int i=0;i<10000;i++){
Person p=new Person("wangdada"+i,25,"20111"+i);
ps.justAdd(p);
}
//设置结束时间t2
long t2=System.currentTimeMillis();
//输出持续时间
System.out.println(t2-t1);
}
}
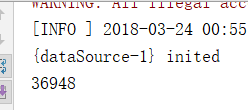
开连接池结果如图
不开连接池如图
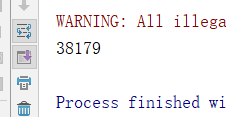
可以看到基本上没有什么差别,和预料中的节约时间不一样啊。其实仔细看就会发现这个是正常的,因为开了连接池之后在多线程情况下是可以节约开关连接的时间的,但是此时我是单线程,所以只有一次开关连接可以节约,自然就相差不大了。开了连接池最主要的原因还是起到保护的作用,防止突然很多用户同时登陆,被耗完内存,节约开关时间还是次要功能。
明天计划的事情:(一定要写非常细致的内容)
1.明天准备先学习一下creat_at和update_at的相关属性和添加方法然后把creat_at和update_at字段加入表中
2.学习debug调试
3.log4j好好研究下,关于哪些东西需要储存到本地
遇到的问题:(遇到什么困难,怎么解决的)
对于什么时候该用try-catch,什么时候该用throws还是不太搞得清楚,明天试验下
收获:(通过今天的学习,学到了什么知识)
1.了解了try-catch
2.了解了连接池基本原理和基本属性
3.小课堂了解了varchar具体存储长度相关




评论