发表于: 2018-03-21 23:13:24
1 664
今日完成:
一,继续学习SSM框架.
1.1、Spring
Spring是一个开源框架,Spring是于2003 年兴起的一个轻量级的Java 开发框架,由Rod Johnson 在其著作Expert One-On-One J2EE Development and Design中阐述的部分理念和原型衍生而来。它是为了解决企业应用开发的复杂性而创建的。Spring使用基本的JavaBean来完成以前只可能由EJB完成的事情。然而,Spring的用途不仅限于服务器端的开发。从简单性、可测试性和松耦合的角度而言,任何Java应用都可以从Spring中受益。 简单来说,Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架。
1.2、SpringMVC
Spring MVC属于SpringFrameWork的后续产品,已经融合在Spring Web Flow里面。Spring MVC 分离了控制器、模型对象、分派器以及处理程序对象的角色,这种分离让它们更容易进行定制。
1.3、MyBatis
MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis 。MyBatis是一个基于Java的持久层框架。iBATIS提供的持久层框架包括SQL Maps和Data Access Objects(DAO)MyBatis 消除了几乎所有的JDBC代码和参数的手工设置以及结果集的检索。MyBatis 使用简单的 XML或注解用于配置和原始映射,将接口和 Java 的POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
二,了解了Spring中Bean的含义.
如:<bean id="userAction" class="com.neusoft.gmsbs.gms.user.action.UserAction"
scope="prototype">
<property name="userBO" ref="userBO" />
</bean>
<bean id="userBO" class="com.neusoft.gmsbs.gms.user.bo.impl.UserBOImpl">
<property name="userDAO" ref="userDAO" />
</bean>
我个人的理解,觉得bean就相当于定义一个组件,这个组件是用于具体实现某个功能的。这里的所定义的bean就相当于给了你一个简洁方便的方法来调用这个组件实现你要完成的功能。
对于我们的spring最主要的应该就是由这些bean组成的bean工厂,每个bean实现一个功能
例如:你写的第一个bean
<bean id="userAction" class="com.neusoft.gmsbs.gms.user.action.UserAction"
scope="prototype">
<property name="userBO" ref="userBO" />
</bean>
id相当于定义了你的这个bean的别名,如果你需要他的话只要关联这个别名就可以了,也就相当于下面的<property name="userBO" ref="userBO" />一样,在你的userAction中需要实现userBO这个功能,我关联它,那么在action中set注入就可以使用了!
至于其他的属性看下面:
Id : 标识该bean的名称,通过factory.getBean(“id”)来获得实例。
Class : 该bean的类路径。
Singleton : 默认为true,即单实例模式,每次getBean(“id”)时获取的都是同
一个实例,如果设置为false,即原型模式,则每次获取的是新创建
的实例。
Init-method : 在bean实例化后要调用的方法(bean里定义好的方法)。
Destroy-method : bean从容器里删除之前要调用的方法。
Autowire : 其属性要通过何种方法进行属性的自动装配。
对于上述的各个属性,id和class是必要的,其他的则可以省略。例如如果设置了autowire的值,则表明需要自动装配,否则是手动装配。
Spring中Bean的命名
1、每个Bean可以有一个id属性,并可以根据该id在IoC容器中查找该Bean,该id属性值必须在IoC容器中唯一;
2、可以不指定id属性,只指定全限定类名,如:
<bean class="com.zyh.spring3.hello.StaticBeanFactory"></bean>
此时需要通过接口getBean(Class<T> requiredType)来获取Bean;
如果该Bean找不到则抛异常:NoSuchBeanDefinitionException
如果该类型的Bean有多个则抛异常:NoUniqueBeanDefinitionException
3、如果不指定id,只指定name,那么name为Bean的标识符,并且需要在容器中唯一;
4、同时指定name和id,此时id为标识符,而name为Bean的别名,两者都可以找到目标Bean;
5、可以指定多个name,之间可以用分号(“;”)、空格(“ ”)或逗号(“,”)分隔开,如果没有指定id,那么第一个name为标识符,其余的为别名;若指定了id属性,则id为标识符,所有的name均为别名。如:
<bean name="alias1 alias2;alias3,alias4" id="hello1" class="com.zyh.spring3.hello.HelloWorld">
<constructor-arg index="0" value="Rod"></constructor-arg>
</bean>
此时,hello1为标识符,而alias1,alias2,alias3,alias4为别名,它们都可以作为Bean的键值;
6、可以使用<alias>标签指定别名,别名也必须在IoC容器中唯一,如:
<bean name="bean" class="com.zyh.spring3.hello.HelloWorld"/>
<alias alias="alias1" name="bean"/>
<alias alias="alias2" name="bean"/>
ref和idref之间的区别
在Spring中,idref属性和ref属性都可以用在constructor-arg元素和property元素中完成注入,那么它之间有什么区别呢?
考虑如下一段配置:
<bean id="bea" class="java.lang.String">
<constructor-arg index="0"><value>testString</value></constructor-arg>
</bean>
<bean id="beanID" class="com.zyh.spring3.hello.HelloWorld">
<constructor-arg name="name"><idref bean="bea" /></constructor-arg>
<property name="id">
<ref local="bea" />
</property>
<property name="age" value="25"></property>
</bean>
其实,idref注入的是目标bean的id而不是目标bean的实例,同时使用idref容器在部署的时候还会验证这个名称的bean是否真实存在。其实idref就跟value一样,只是将某个字符串注入到属性或者构造函数中,只不过注入的是某个Bean定义的id属性值。所以上面的代码中
<constructor-arg name="name"><idref bean="bea" /></constructor-arg>
其实等同于
<constructor-arg name="name"><value>bea</value></constructor-arg>
而ref则是完全地不同,ref元素是将目标Bean定义的实例注入到属性或构造函数中,ref元素有三个属性,区别如下:
1、local 只能指定与当前配置的Bean在同一个配置文件中的Bean定义的名称;
2、parent 只能指定位于当前容器的父容器中定义的对象引用;
3、bean 基本上通吃,即包括以上两种情况都可以,所以,通吃情况下,直接使用bean来指定对象引用就可以了。
所以,上面那段配置代码中,beanID这个Bean中构造函数的参数name注入的只是“bea”这个字符串;而其id属性注入的则是testString这个字符串。
构造器注入的好处
先来看看Spring在文档里怎么说:
The Spring team generally advocates constructor injection as it enables one to implement application components as immutable objects and to ensure that required dependencies are not
null. Furthermore constructor-injected components are always returned to client (calling) code in a fully initialized state.
咳咳,再来简单的翻译一下:这个构造器注入的方式啊,能够保证注入的组件不可变,并且确保需要的依赖不为空。此外,构造器注入的依赖总是能够在返回客户端(组件)代码的时候保证完全初始化的状态。
下面来简单的解释一下:
- 依赖不可变:其实说的就是final关键字,这里不再多解释了。不明白的园友可以回去看看Java语法。
- 依赖不为空(省去了我们对其检查):当要实例化FooController的时候,由于自己实现了有参数的构造函数,所以不会调用默认构造函数,那么就需要Spring容器传入所需要的参数,所以就两种情况:1、有该类型的参数->传入,OK 。2:无该类型的参数->报错。所以保证不会为空,Spring总不至于传一个null进去吧 :-(
- 完全初始化的状态:这个可以跟上面的依赖不为空结合起来,向构造器传参之前,要确保注入的内容不为空,那么肯定要调用依赖组件的构造方法完成实例化。而在Java类加载实例化的过程中,构造方法是最后一步(之前如果有父类先初始化父类,然后自己的成员变量,最后才是构造方法,这里不详细展开。)。所以返回来的都是初始化之后的状态。
等等,比较完了setter注入与构造器注入的优缺点,你还没用说使用field注入与构造器的比较呢!那么我们再回头看一看使用最多的field注入方式:
1 2 3 4 | //承接上面field注入的代码,假如客户端代码使用下面的调用(或者再Junit测试中使用)//这里只是模拟一下,正常来说我们只会暴露接口给客户端,不会暴露实现。FooController fooController = new FooController();fooController.listFoo(); // -> NullPointerException |
如果使用field注入,缺点显而易见,对于IOC容器以外的环境,除了使用反射来提供它需要的依赖之外,无法复用该实现类。而且将一直是个潜在的隐患,因为你不调用将一直无法发现NPE的存在。
还值得一提另外一点是:使用field注入可能会导致循环依赖,即A里面注入B,B里面又注入A:
1 2 3 4 5 6 7 8 9 | public class A { @Autowired private B b;}public class B { @Autowired private A a;} |
如果使用构造器注入能够避免上述循环依赖这种情况。
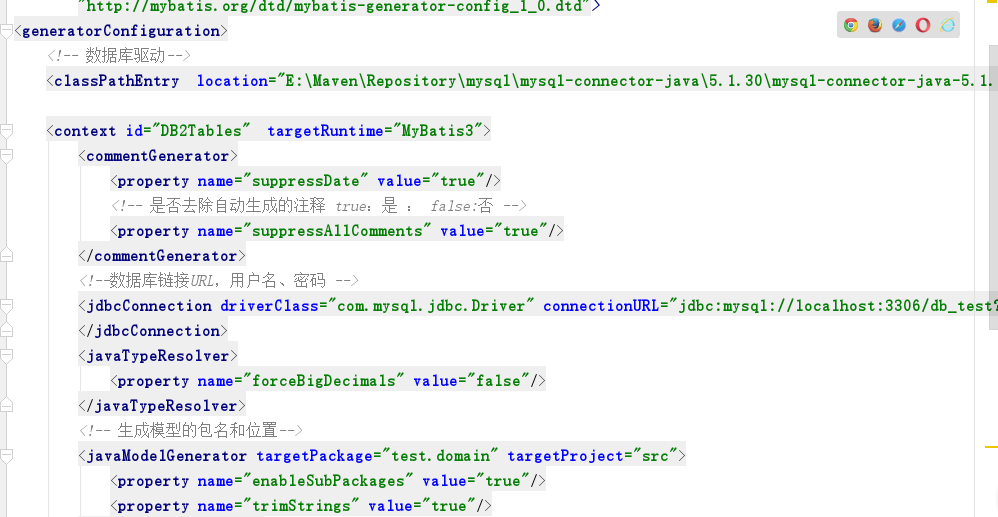
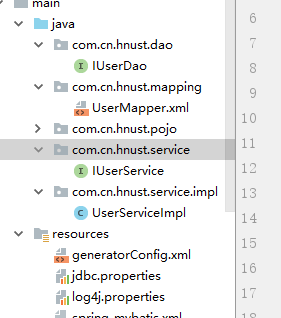
三,学习了使用Mybatis自动生成pojo,dao,mapper.xml文件.
明日计划:
完成任务二.
问题:导入jar包时路径出错.解决办法用shift点右键 复制jar包的绝对路径,粘贴到location中.
收获:
学习了SSM框架实现数据库连接的接口,学习了配置文件中ref,value,class的含义以及bean组件之间联系是怎么实现的.




评论