发表于: 2018-03-21 23:01:12
2 613
一、今天做的事情
1、根据他人的日报,结合我自己的理解,针对数据库表进行修改.png)
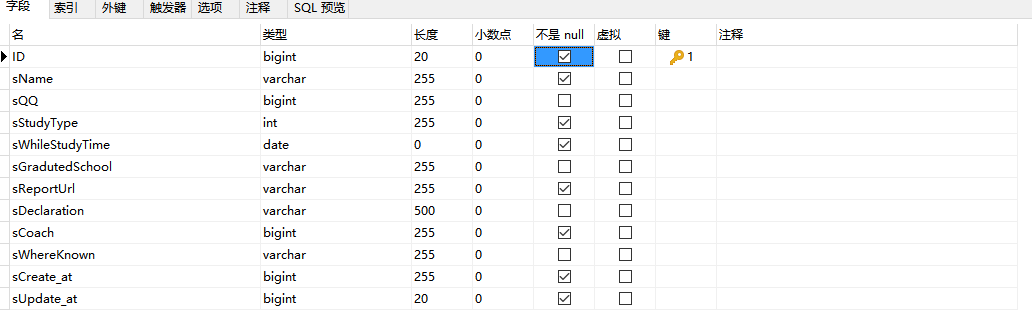
开始设计的表如上图所示,犯了几个问题:
1)、忽略了线下报名表是个人填写,不应将个人的学号用作表的主键,虽然个人的学号也是唯一值。作为主键的ID应该是自增的,在插入每一条报名的信息的时候自动生成。
2)、没有对字段的类型长度进行约束,过多使用默认长度,会导致空间浪费。虽然小项目不碍事,但是大项目每一寸空间都是必争之地。
3)、凭帖子的要求推断学号应该是int,但是看到实际报名帖的时候,发现还需要带上班号,甚至是修真类型,遂改为varchar类型。
其实对于类型是有我自己的设计在里面,我看到深入思考的部分有问,等到时候再返回来写为什么想要设置成这样的类型,虽然不一定是正确的。
经过重新设计的表如下图
.png)
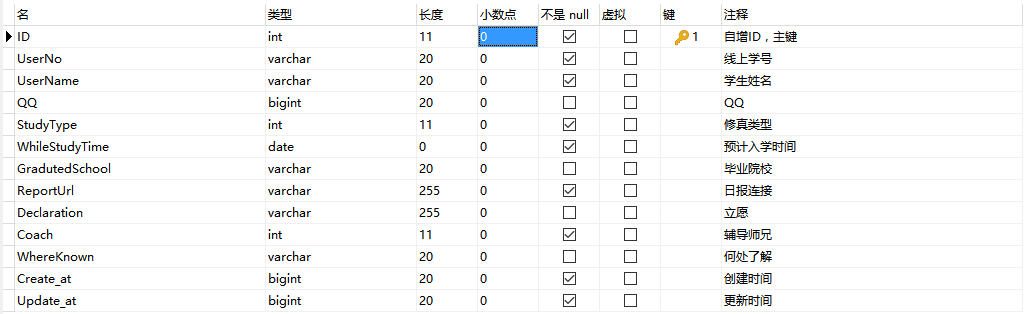
2、之前没有设计辅导师兄的表,今天一并补上。
.png)

必备的字段,其他字段遇到以后再添加。
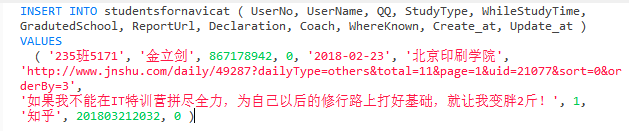
3、用SQL语句插入一条数据
姓名:金立剑
QQ:867178942
修真类型:前端工程师
预计入学时间:2018年2月23日
毕业院校:北京印刷学院
线上(jnshu.com)学号:235班5171
日报链接:http://www.jnshu.com/daily/49287?dailyType=others&total=11&page=1&uid=21077&sort=0&orderBy=3
立愿:如果我不能在IT特训营拼尽全力,为自己以后的修行路上打好基础,就让我变胖2斤!
辅导师兄:黄苏威
从何处了解到的修真院:知乎
使用SQL语句插入该数据
.png)
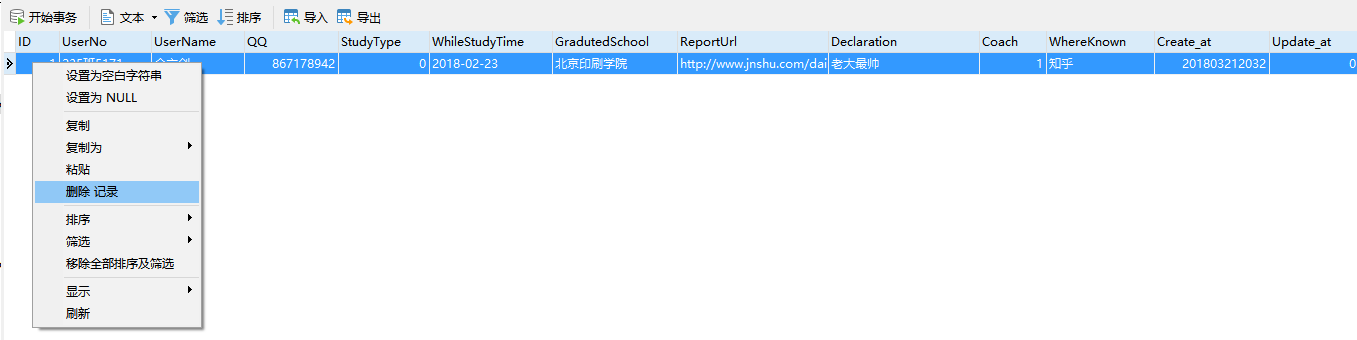
4、用不同方式将报名宣言改成老大最帅
1)使用SQL语句修改
.png)

2)使用Navicat修改
.png)

5、将该条数据导出成SQL文件,并尝试用不同方式进行删除后还原
1)使用SQL语句进行删除
.png)

2)使用Navicat进行删除
.png)
.png)
6、给姓名建索引
.png)

前一个UserName表示的是索引的名字,后一个UserName表示的是在表中的列名
7、插入10条语句比较速度
可能是数据量太小的问题,差别不大
8、关于MySql的深度思考问题
1) 为什么DB的设计中要使用Long来替换掉Date类型?
经过百度,感觉应该是因为保存的是本地时间,不是服务器时间,如果需要服务器时间的话,还需要对date数据进行时区的转换。并且有些国家存在夏令时的问题,比较麻烦。我们设立时间戳主要是为了方便记录操作的时间,long类型的进行计算比较容易。
2) 自增ID有什么坏处?什么样的场景下不使用自增ID?
众说纷纭,比较靠谱的说法就是自增ID在创建分布式数据库的时候会导致数据库的主键值不唯一,平常正常使用为了节省开发时间,避免计算ID的影响,使用自增ID也没太大的关系。在我写.net的经验看来,使用自增ID在应对绝大多数的情况下都没什么问题。还未开发过分布式数据库的系统,需要具体问题具体分析。
3) 什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
看到一个应该是之前师兄写的思考,我觉得很对,其中我自己想到的用斜体加下划线标出。
一个索引是存储的表中一个特定列的值数据结构(最常见的是B-Tree)。
索引是在表的列上创建。所以,要记住的关键点是索引包含一个表中列的值,并且这些值存储在一个数据结构中,索引是一种数据结构,一般是B-TREE 。
在数据量达到几万时,性能差别就比较直观。
使用索引的原则:
1、装载数据后再建立索引。
2、频繁搜索的列可以作为索引。
3、在联接属性上建立索引(主外键)。
4、经常排序分组的列。
5、删除不经常使用的索引。
6、指定索引块的参数,如果将来会在表上执行大量的insert操作,建立索引时设定较大的ptcfree。
7、指定索引所在的表空间,将表和索引放在不同的表空间上可以提高性能。
8、对大型索引,考试使用NOLOGGING子句创建大型索引
4) 唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。
因此,应该只为那些最经常出现在查询条件(WHEREcolumn=)或排序条件(ORDERBYcolumn)中的数据列创建索引。
只要有可能,就应该选择一个数据最整齐、最紧凑的数据列(如一个整数类型的数据列)来创建索引。
mysql > ALTER TABLE {table_name} ADD INDEX index_name ( {column} )
唯一索引与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
在对该列进行增或改时,首先会检查是否重复,在执行增改操作,否则报出duplica错误,拒绝操作。
mysql > ALTER TABLE {table_name} ADD UNIQUE index_name ( {lolumn} )
5) 如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
不需要,如果做了唯一索引,mysql会自动判断有没有一样的值。
6) CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
CreateAt在第一次插入数据的时候赋值,UpdateAt是在每一次修改完数据之后赋值。不应该开放调用接口,这两个字段不参与业务,属于记录所用。
7) 修真类型应该是直接存储Varchar,还是应该存储int?
这个问题我在设计数据库结构的时候就一直在考虑,再三思量过后决定设为int类型。有如下几个原因:
1、修真类型在实际项目中可以使用枚举进行表示,每个int数字对应一个修真类型。保证修真类型的唯一,确保规范,因为人来填写会写出各种各样的类型,哪怕给他们规范的写法。
2、作为int型的字段,在查询中相对于字符串来说有更高的效率。
3、也算是增加了项目中属性的保密性吧。
8) varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
创建表的时候会填写最大存放长度,这个长度是字符数不是字节数。
原则是我找的资料。
varchar目前的mysql版本最高支持65535字节,按照不同编码规则,对应20000左右或30000个左右的中文字符。
text的长度为存放最大长度为 65,535 个字符的字符串。
longtext存放最大长度为 4,294,967,295 个字符的字符串。
9) 怎么进行分页数据的查询,如何判断是否有下一页?
相比较SQLServer来说,MySQL的分页方式比较简单。它提供了LIMIT函数。
LIMIT子 句可以用来限制由SELECT语句返回过来的数据数量,它有一个或两个参数,如果给出两个参数, 第一个参数指定返回的第一行在所有数据中的位置,从0开始(注意不是1),第二个参数指定最多返回行数。例如:
select * from table WHERE … LIMIT 10; #返回前10行
select * from table WHERE … LIMIT 0,10; #返回前10行
select * from table WHERE … LIMIT 10,20; #返回第10-20行数据
对于如何判断是否有下一页,我的猜想是,知道当前页的最后一行数据的ID,判断在整个数据库的位置,是否在最后一个分页中。
10) 为什么不可以用Select * from table?
主要是效率问题,我们针对某项功能的时候,很少会用到全部的列,只需要知道某几个列就好,针对某几个列进行查询更为快速。
二、明天要做的事情
正式开始对Java的学习,预计能完成12-18的任务。
三、遇到的问题
主要是数据库部分,针对字段的类型设计拿不准主意,有时候觉得应该从项目的全局角度去看数据库字段的设计,但是看到线下报名帖的时候,又觉得应该简单的都设置为varchar。不过最后还是坚持了从全局出发的想法。后来回到网站中任务界面的任务叙述中看到 根据修真院的线下报名贴,去设计DB。无论做什么项目,从需求出发,设计对应的表结构都是一项基础的能力。就感觉自己做对了。
再一个是对MySQL的基础不太牢固,需要再仔细看看。
四、今天的收获
对MySQL了解了更多了,而且也熟悉了Navicat的使用方式。在做深入思考的时候,拓展了自己的思考空间,也丰富了知识面。




评论