发表于: 2018-03-21 20:31:28
1 586
今天完成的事情:
完成昨天对于索引的影响
百万级别数据:
无索引,查询一百万条数据:
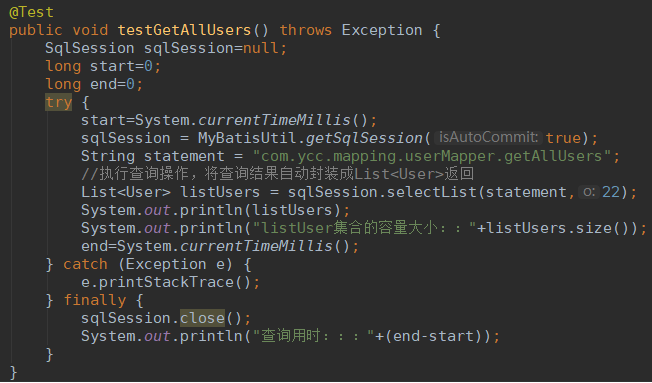

有索引,查询一百万条数据::
alter table users add index index_age(age);

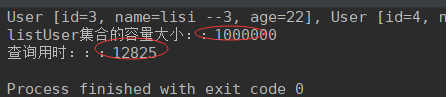
无索引,查询一条数据:
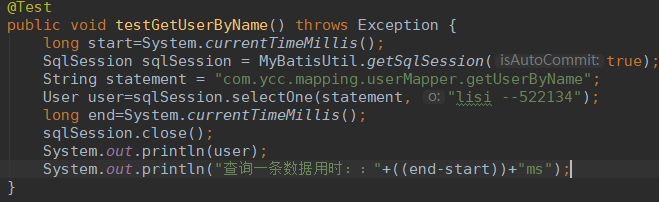
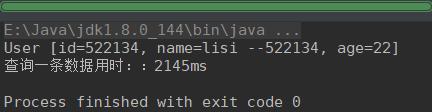
有索引,查询一条数据:

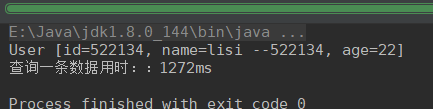
有索引,删除一条数据:

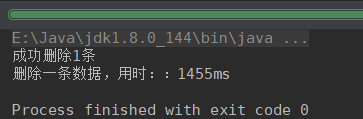
无索引,删除一条数据
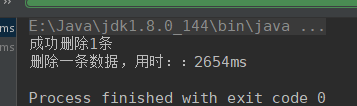
有索引,修改一条数据
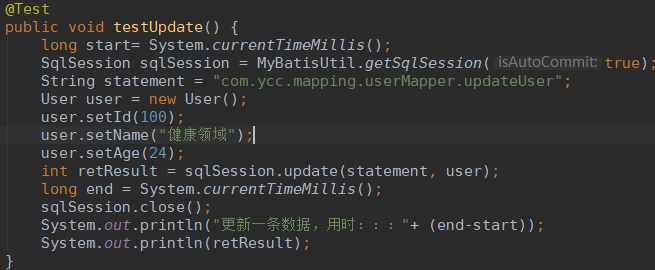

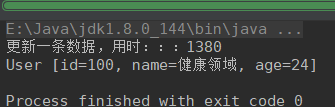
无索引,修改一条数据
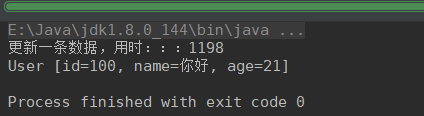
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
千万条数据
无索引,查询一条
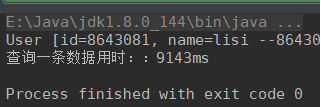
有索引,查询一条

有索引,修改一条
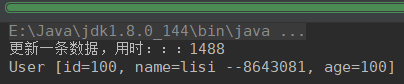
无索引,修改一条
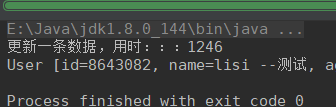
无索引,删除一条

有索引,删除一条

总结::
之前在网上看到说建立索引的情况下,增删改的速度变慢,查询的速度变快。
但是根据测试,查询的速度确实变慢了,删除数据在有索引的情况下速度还要快些(这是为什么)!!
下边这张表是实际测试的时间,
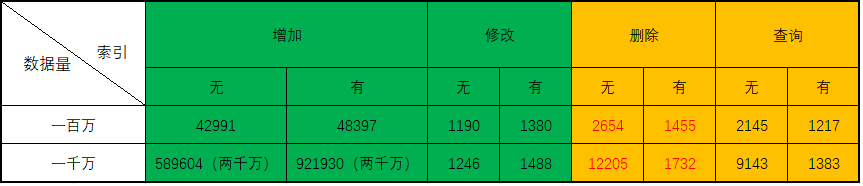
深度思考
- 普通索引
- 唯一索引(UNIQUE索引)
- varchar (N)中的N指的是该字段最多能存储多少个字符(characters),不是字节数。不管是一个中英文字符或者数字、或者一个汉字,都当做一个字符。
- varchar最多能存储65535个字节的数据。65535并不是一个很精确的上限,可以继续缩小这个上限。65535个字节包括所有字段的长度,变长字段的长度标识(每个变长字段额外使用1或者2个字节记录实际数据长度)、NULL标识位的累计。
- NULL标识位,如果varchar字段定义中带有default null允许列空,则需要1bit来标识,每8个bits的标识组成一个字段。一张表中存在N个varchar字段,那么需要(N+7)/8 (取整)bytes存储所有的NULL标识位。
- 如果数据表只有一个varchar字段且该字段DEFAULT NULL,那么该varchar字段的最大长度为65532个字节,即65535-2-1=65532 bytes。
- 如果数据表只有一个varchar字段且该字段NOT NULL,那么该varchar字段的最大长度为65533个字节,即65535-2=65533bytes。
- varchar在定义的时候需要指定长度,text不用指定长度,如果写了的话,不会报错,但指定的长度也不会其作用,超过你指定的长度还是可以正常插入。varchar是受存储限制的,而text不受存储限制,在超过varchar最大长度的时候,就用text。longtext和text类似,只是容量更大。
1.maven是什么,和Ant有什么区别?
Maven是一个项目管理工具,主要用于项目构建,依赖管理,项目信息管理。
ant和maven相同点:都是项目构建管理工具。
不同点有:
1. Maven约定了目录结构,而Ant没有。
2. Maven是申明式的,用pom.xml文件;而Ant是程序式的,构建过程需要自定义,用builder.xml.
3. Maven是有生命周期的,而Ant没有。
4. Maven内置依赖管理和Repository来实现依赖的管理和统一存储;而Ant没有。Maven第一次install的时候会把依赖的jar包和构件从中央仓库(统一存储maven可以解释的文件资源)下载到本地库(先从本地仓库找)。Maven还可以管理传递依赖。
5.Maven配置比较简单,有很多的约定、规范、标准,可以用较少的代码干更多的事;而Ant配置比较麻烦,需要配置整个构建的过程(但Ant配置灵活)。
2.clean,install,package,deploy分别代表什么含义?
mvn clean:清理项目生产的临时文件,一般是模块下的target目录。
mvn install:将打包的jar/war文件复制到你的本地仓库中,供其他模块使用。
mvn package:打包到本项目的target下。(如果a项目依赖于b项目,打包b项目时,只会打包到b项目下target下,编译a项目时就会报错。)
mvn deploy:打包上传到远程仓库,提供其他人员进行下载依赖。
3.怎么样能让Maven跳过JUnit?
第一种是在命令行下,转到要编译的项目目录下
(1)mvn install -Dmaven.test.skip=true,不执行测试用例,也不编译测试用例类。
(2)-DskipTests,不执行测试用例,但编译测试用例类生成相应的class文件至target/test-classes下。
第二种是在pom文件中修改
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
第三种也是修改pom文件,配置包含与排除测试用例
<plugin>
<groupId>org.apahce.maven.plugins<groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<includes>
<include>**/*Tests.java</include>
</includes>
</configuration>
</plugin>
4.为什么要用Log4j来替代System.out.println?
1,提供应用程序运行上下文,方便跟踪调试.这对开发人员很有帮助,特别是调试的时候,我们不再需要用System.out.println()来帮忙了,调试好之后再费心的把它去掉.特别是在系统测试的时候,有了它很容易跟踪和调试.
2,把记录的日志输送到多种方式上.包括命令行,控制台(调试的时候马上就能看到哪里有问题),文件(把完整的日志信息保存起来,以利于整个系统的维护,统计),回卷文件、内存等.
3,可以动态控制日志记录级别,在效率和功能中进行调整.当执行等级小于设定等级时就不输出.
4,所有配置可以通过配置文件进行动态调整.
Log4j有三个主要的组件:日志类别(Loggers)、输出源( Appenders)和布局(Layouts)。这三种类型的组件一起工作使得开发员可以根据信息的类型和级别记录它们,并且在运行时控制这些信息的输出格式和位置。
5.为什么DB的设计中要使用Long来替换掉Date类型?
1. 因为DATE有固定的格式,而且外国有夏令时与冬令时之分,另外时区的不同导致不同时区的时间不一致。
2. 使用BigInt也能较为清晰的表示时间
3. 大多数时候我们并不关心某一个时间点,而是发生一个动作所需要的时间,BigInt非常方便做减法而不用转化。
6.自增ID有什么坏处?什么样的场景下不使用自增ID?
坏处:
(1)不存在连续性
(2)数据重复了,自增不会处理和提示
(3)在面对对象时,不能保证完整性
(4)分库的时候ID就不唯一了
(1)因为自动增长,在手动要插入指定ID的记录时会显得麻烦,尤其是当系统与其它系统集成时,需要数据导入时,很难保证原系统的ID不发生主键冲突(前提是老系统也是数字型的)。特别是在新系统上线时,新旧系统并行存在,并且是异库异构的数据库的情况下,需要双向同步时,自增主键将是你的噩梦;
(2)在系统集成或割接时,如果新旧系统主键不同是数字型就会导致修改主键数据类型,这也会导致其它有外键关联的表的修改,后果同样很严重;
(3)若系统也是数字型的,在导入时,为了区分新老数据,可能想在老数据主键前统一加一个字符标识(例如“o”,old)来表示这是老数据,那么自动增长的数字型又面临一个挑战。
什么场景下不适用自增ID:
(1)自增id的作用是唯一地标识表中的某一条记录,如果有其他能唯一标识该行数据的列,就不用设置自增id了。
(2) 分布式数据库,要求数据同步时,这种自增ID就会出现严重的问题,因为你无法用该ID来唯一标识记录。同时在数据库做移植时,也会出现各种问题,总之,对此自增ID有依赖的情况,都有可能出现问题。
7.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
什么是DB的索引
一个索引是存储的表中一个特定列的值的数据结构(最常见的是B-Tree)。索引是在表的列上创建。所以,要记住的关键点是索引包含一个表中列的值,并且这些值存储在一个数据结构中,索引是一种数据结构,一般是B-TREE 。
多大的数据量下建索引会有性能的差别
插入千万级数据的时候,差别会比较大
什么样的情况下该对字段建索引
主键,外键,where中的字段,order by ,group by
8.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
唯一索引和普通索引的区别是什么
最基本的索引类型,没有唯一性之类的限制。
普通索引的唯一任务是加快对数据的访问速度。因此,应该只为那些最经常出现在查询条件(where)或排序条件中(orderby)的数据列创建索引。
只要有可能,就应该选择一个数据最整齐、最紧凑的数据列(如一个整数类型的数据列)来创建索引。
唯一索引是不允许其中任何两行具有相同索引值的索引。
当现有数据中存在重复的键值时,大多数数据库不允许将新创建的唯一索引与表一起保存。数据库还可能防止添加将在表中创建重复键值的新数据。对某个列建立UNIQUE索引后,插入新纪录时,数据库管理系统会自动检查新纪录在该列上是否取了重复值。
当表中的某一列不允许有重复的值时,应该创建唯一索引,比如身份证号。
9.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
不需要,若插入的数据与已有的数据重复,MySQL会报错使得插入失败。
10.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
CreateAT在数据创建的时候赋值,UpdateAt在每次更新数据的时候赋值;
是否应该开放给外部调用的接口?
不应该开放,这两项分别是数据创建和修改时录入数据库的时间,不需要进行修改
11.修真类型应该是直接存储Varchar,还是应该存储int?
由于修真类型只有有限的几种,可以用特定的数字代表某个类型,因此可以用int以节省空间。
12.varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
13.怎么进行分页数据的查询,如何判断是否有下一页?
MySQL数据库实现分页比较简单,提供了 LIMIT函数。一般只需要直接写到sql语句后面就行了。
LIMIT子 句可以用来限制由SELECT语句返回过来的数据数量,它有一个或两个参数,如果给出两个参数, 第一个参数指定返回的第一行在所有数据中的位置,从0开始(注意不是1),第二个参数指定最多返回行数。例如:
select * from table WHERE … LIMIT 10; #返回前10行
select * from table WHERE … LIMIT 0,10; #返回前10行
select * from table WHERE … LIMIT 10,20; #返回第11-30行数据
14.为什么不可以用Select * from table?
select * 语句会取出表中的所有字段,当数据量大的时候,这样会造成资源的浪费。
15.什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
领域模型分为4大类:1.失血模型 2.贫血模型 3.充血模型 4.胀血模型
贫血模型
是指领域对象里只有get和set方法,或者包含少量的CRUD方法,所有的业务逻辑都不包含在内而是放在Business Logic层。
优点是系统的层次结构清楚,各层之间单向依赖,Client->(Business Facade)->Business Logic->Data Access(ADO.NET)。当然Business Logic是依赖Domain Object的。似乎现在流行的架构就是这样,当然层次还可以细分。
该模型的缺点是不够面向对象,领域对象只是作为保存状态或者传递状态使用,所以就说只有数据没有行为的对象不是真正的对象。
充血模型
充血模型和第二种模型差不多,所不同的就是如何划分业务逻辑,即认为,绝大多业务逻辑都应该被放在domain object里面(包括持久化逻辑),而Business Logic层应该是很薄的一层,仅仅封装事务和少量逻辑,不和DAO层打交道。
缺点是如何划分业务逻辑,什么样的逻辑应该放在Domain Object中,什么样的业务逻辑应该放在Business Logic中,这是很含糊的。即使划分好了业务逻辑,由于分散在Business Logic和Domain Object层中,不能更好的分模块开发。熟悉业务逻辑的开发人员需要渗透到Domain Logic中去,而在Domian Logic又包含了持久化,对于开发者来说这十分混乱。 其次,因为Business Logic要控制事务并且为上层提供一个统一的服务调用入口点,它就必须把在Domain Logic里实现的业务逻辑全部重新包装一遍,完全属于重复劳动。
16.Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
IOC(Inversion of Control)即控制反转,是一种设计思想:通俗的讲就是如果在什么地方需要一个对象,你自己不用去通过new 生成你需要的对象,而是通过spring的bean工厂为你产生这样一个对象。IOC是把以前在工厂方法里写死的对象生成代码,改变为由XML文件来定义,也就是把工厂和对象生成这两者独立起来,目的是提高灵活性和可维护性。
IOC的优点:传统方式new对象,对象和对象之间的由严重的依赖关系,耦合度非常高,项目不易修改和维护。当我们用来IOC之后,我们不再需要自己负责创建对象,管理对象生命周期以及维护对象的依赖关系,这些都由Spring替我们完成了。
17.为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
Java接口是一系列方法的声明,是一些方法特征的集合,一个接口只有方法的特征没有方法的实现,因此这些方法可以在不同的地方被不同的类实现,而这些实现可以具有不同的行为。因此提高了可维护性和扩展性。
18.为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发 生一次?
java中的异常机制不能被忽略,它需要程序员在适当位置捕获异常,倘若该异常没有及时捕获,那么当java虚拟机执行到异常时就会中断,而不能继续执行下面的代码,这是我们不希望看到的。
使用try/catch捕获异常的情景主要有:
(当不使用这种try结构时,代码报错退出就无法继续执行。有的代码出错就应该退出,有的出错尚可以补救,就不应该退出。对于这种出错不应该退出的就需要使用这种结构,在catch中进行补救。)
1. 程序块中语句可能的异常不能引起其他逻辑中断;
例如:缓存逻辑不能影响正常的逻辑运行,故缓存逻辑应该放在try/catch块中。
2. 必须对异常进行处理,否则会降低用户使用体验。
例如:异常到了Controller层,若不处理则会返回404或500错误页面,因此,必须使用try/catch处理各种异常。
mysql与程序连接,在一定时间内没有出现连接超过mysql的连接等待时间(wait_timeout)会出现断开连接情况,跟数据库配置有关。
mysql默认连接等待时间是为(28800s)即8h,
19.日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
什么时候应该打日志
1,当你遇到问题的时候,只能通过debug功能来确定问题,你应该考虑打日志,良好的系统,是可以通过日志进行问题定为的。
2,当你碰到if…else 或者 switch这样的分支时,要在分支的首行打印日志,用来确定进入了哪个分支
3,经常以功能为核心进行开发,你应该在提交代码前,可以确定通过日志可以看到整个流程
位置:1. 对外部的调用封装 2.状态变化 3.系统入口与出口 4.业务异常 5.非预期执行 6.很少出现的else情况
参数:1. 程序运行时间 2. 大批量数据的执行进度 3.关键变量及正在做哪些重要的事情
20.为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
单步调试可以清晰看到参数的值和传递路径或方法的调用,找到程序出错的地方。
21.可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
一个项目的发布应该分为开发,测试,线上。远程调试一般在于开发后中的集中测试。
真实项目中通过远程连接进行调试,服务端执行代码,而本地通过远程连接,到服务器获取数据和运行结果的方法。
明天计划的事情:
明天整理一下代码,看看能否提交,这两天要准备小课堂,感觉好紧张。
遇到的问题:
还是关于有无索引的情况下,删除数据的时间跟网上说法有出入,有时间的话再测试一下把。
收获:
体验了索引对CRUD的影响,深度思考加深了对任务一中的知识点。
进度:任务一步骤30
任务开始时间:3.10
预计demo时间:3.23
是否延期:否
禅道地址:http://task.ptteng.com/zentao/project-task-562.html




评论