发表于: 2018-03-20 23:17:24
1 499
今天完成的事情:
28.数据库里插入100万条数据,对比建索引和不建索引的效率查别。再插入3000万条数据,然后是2亿条,别说话,用心去感受数据库的性能。
因为是大批量数据的插入,因此想到用sql的批量插入。
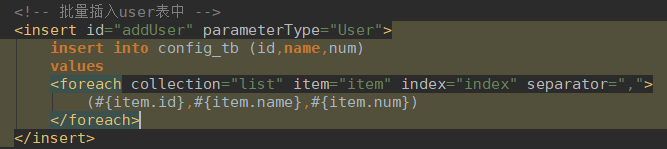
简单介绍下foreach标签:
foreach可以在SQL语句中进行迭代一个集合。
foreach元素的属性主要有 item,index,collection,open,separator,close。
Item | 表示集合中每一个元素进行迭代时的别名 |
Index | 指定一个名字,用于表示在迭代过程中,每次迭代到的位置 |
Open | 表示该语句以什么开始, |
Separator | 表示在每次进行迭代之间以什么符号作为分隔 符 |
Close | 表示以什么结束 |
collection | 该属性是必须指定的,但是在不同情况 下,该属性的值是不一样的,主要有一下3种情况: 如果传入的是单参数且参数类型是一个List的时候,collection属性值为list 如果传入的是单参数且参数类型是一个array数组的时候,collection的属性值为array 如果传入的参数是多个的时候,我们就需要把它们封装成一个Map了 |
插入100万条数据,无索引:
刚开始插入的时候,出现异常:Caused by: com.mysql.jdbc.PacketTooBigException: Packet for query is too large (4388918 > 1048576).
原因:MySQL根据配置文件会限制Server接受的数据包大小。有时候大的插入和更新会受 max_allowed_packet 参数限制,导致写入或者更新失败。
解决:
在mysql命令行中执行命令
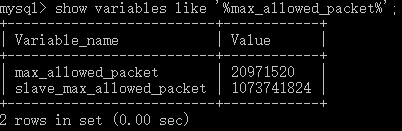
1.查看当前配置
show VARIABLES like '%max_allowed_packet%';
2.修改配置
set global max_allowed_packet = 2*1024*1024*10;
改成20M
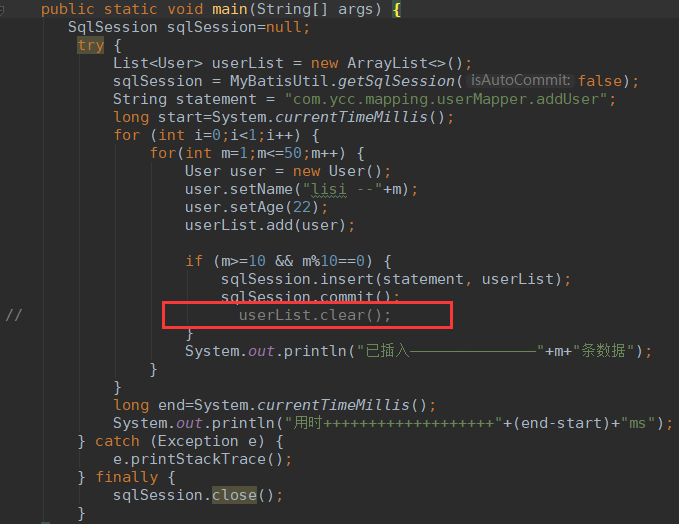
接着我在插入数据的时候发现每次插入的条数,总是跟预想的不一样。
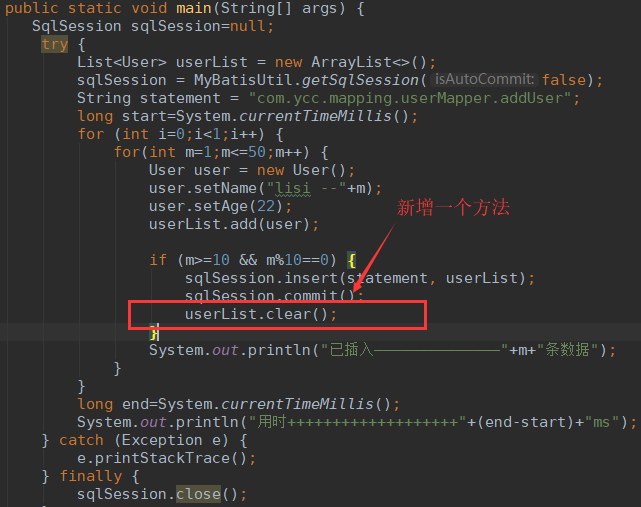
程序如下图,预计在表中插入50条数据,然后每10条数据提交一次。
程序运行的结果:
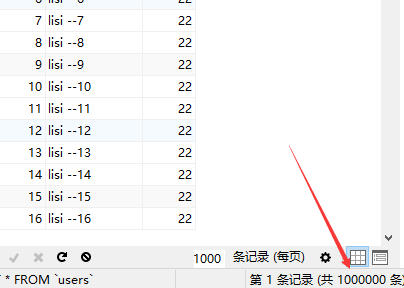
但是查看数据库表,可以看到实际插入了150条数据,并且插入的名字有重复的
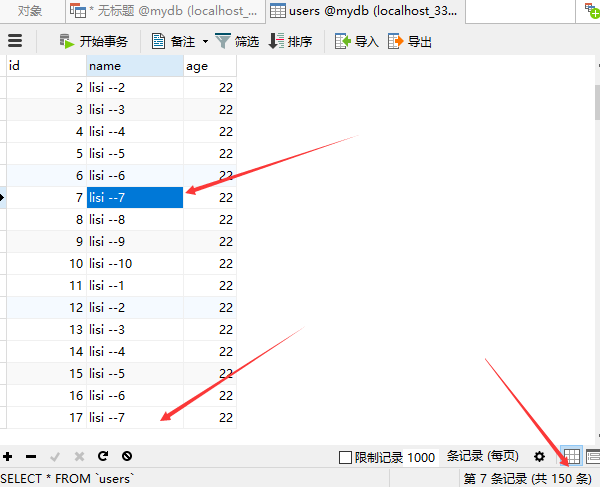
看了下程序代码,事务提交应该没有错,错误应该是处在用了List集合上::当后一批次的数据插入List集合中时,前一批次的数据还保留在List集合中,造成的结果就是每一次提交的数据条数比上一批次提交的数目要多10条,最终在数据库表中就插入了150条数据。
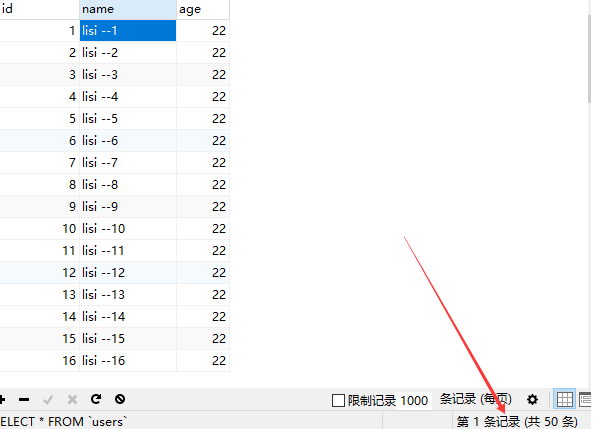
更改程序,在每次提交后,清空List集合中的内容:userList.clear();
运行结果如下,结果正常插入50条数据
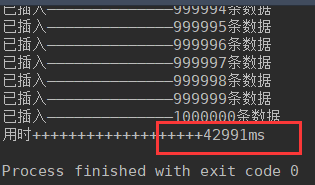
接下来,插入100万条数据,无索引:
程序如下,
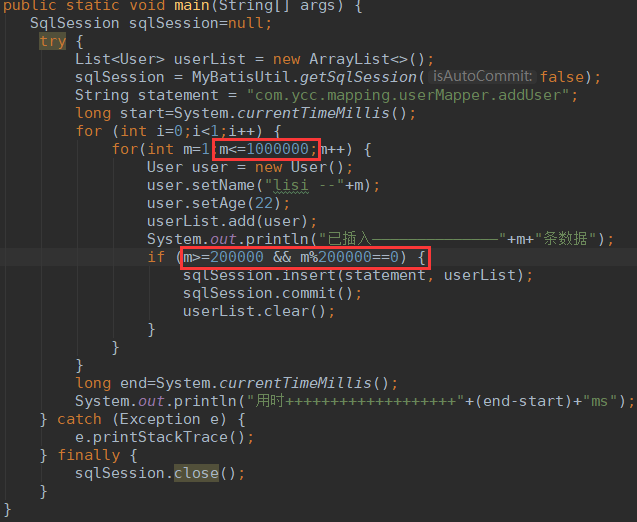
运行结果:
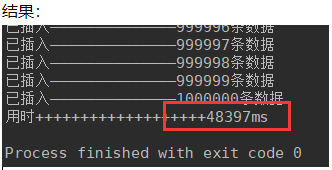
插入100万数据,有索引:
alter table users add INDEX index_name(name);

总结:
对于百万数据,建索引比不建索引多6秒中;
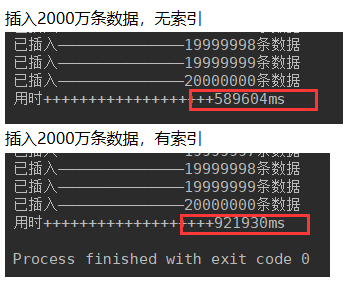
对于两千万数据,建索引比不建索引,需要的插入时间多了333秒。
因此对于有索引的表,插入大数据量所需的时间是大大增加的。
任务小结:
1,学习任务一最开始是下载各种工具和配置环境等,这个就只有靠自己了,遇到错误就百度,因为每个人遇到的问题可能千奇百怪。
2,刚开始做任务会 涉及到很多的陌生的名词,遇到不懂的及时去百度,我们要充分发挥自己的主观能动性,毕竟这也是我们来修真院的目的。不过这个过程肯定是困难的,我们还要有筛选优秀教程的能力。
3,当任务需要我们去操作数据库的时候,我们就要去学习sql语句。比如最基本的建库,删库,建表,删表,以及对数据的增删改查;有些时候数据库会出现异常,这时候就会需要用到一些查看参数的命令比如:show vriables like '%max_allowed_packet%';等等。
4,当做到步骤17的时候,我们需要大量的查阅资料了,当然你首先要知道基础的Java语法,然后我做的时候是先去了解DAO(Data Access Object):专门用来封装对于实体类的数据库的访问,即增删改查,不加业务逻辑。
5,接着去了解了JdbcTemplate是spring对于jdbc的封装,因此我第一步先是在网上找教程实现JDBC连接数据库,当了解了最基本的连接数据库的方式后,再去找关于JDBCTemplate和Mybatis的资料学习,然后学习配置连接池,配置文件等等。
6,然后就是买服务器,在服务器上部署环境;接着需要在本地连接远程服务器。
7,最后就是学习大批量的插入数据,来观察表有无索引的情况下,插入数据的效率。当然插入几百上千万条数据,是需要批量插入的,对基于xml文件方式实现连接和话,需要在insert语句中加入<foreach>标签,代码实现的时候最好是分批提交来提高效率。
明天计划的事情:
完成任务一,深度思考,学习github
遇到的问题:
就是关于之前用List集合来批量提交事务时,出现的实际插入的数据错误,这个困惑出现主要是自己的基础不牢,很多知识需要掌握的运行机制和基本用法不了解。
收获:
了解数据库对于大数据量插入数据的时候,有无索引的区别。总结了任务一的学习过程,从做任务的过程中也意识到有些细节的知识点就会把你卡很久,自己以后还要加强这方面的知识掌握。
进度:任务一29
任务开始时间:3.10
预计demo时间:3.23
是否延期:否
禅道地址:http://task.ptteng.com/zentao/project-task-562.html




评论