发表于: 2018-03-18 15:38:35
1 643
1.maven是什么,和Ant有什么区别?
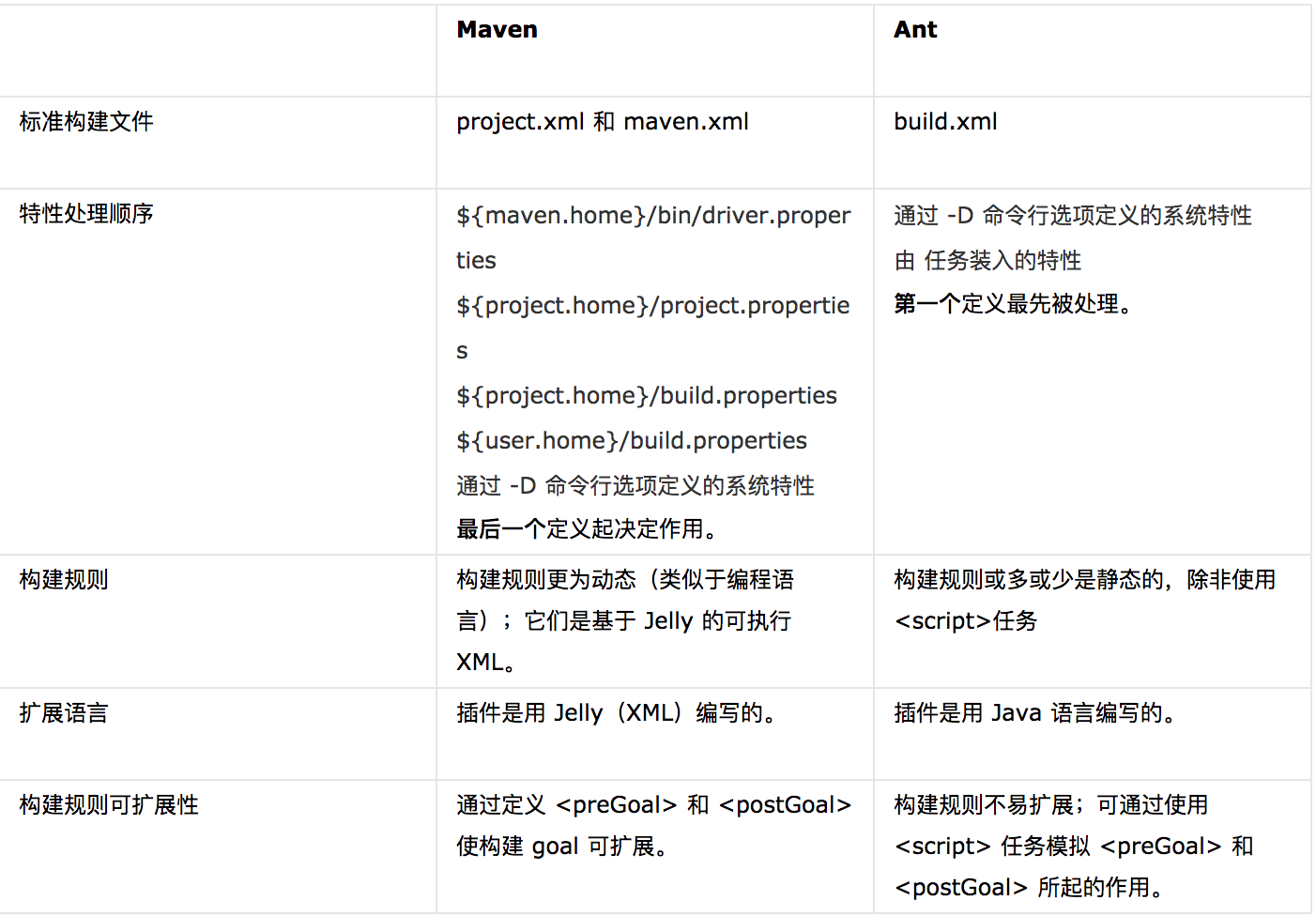
maven是什么:
2.clean,install,package,deploy分别代表什么含义?
mvn clean
说明: 清理项目生产的临时文件,一般是模块下的target目录
mvn package
说明: 项目打包工具,会在模块下的target目录生成jar或war等文件,如下运行结果。
mvn install
说明: 模块安装命令 将打包的的jar/war文件复制到你的本地仓库中,供其他模块使用 -Dmaven.test.skip=true 跳过测试(同时会跳过test compile)
mvn deploy
说明: 发布命令 将打包的文件发布到远程参考,提供其他人员进行下载依赖 ,一般是发布到公司的私服
3.怎么样能让Maven跳过JUnit?
在pom.xml中的build添加plugin元素
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
4.为什么要用Log4j来替代System.out.println?
1. Log4j就是帮助开发人员进行日志输出管理的API类库。它最重要的特点就可以配置文件灵活的设置日志信息的优先级、日志信息的输出目的地以及日志信息的输出格式。
2. Log4j除了可以记录程序运行日志信息外还有一重要的功能就是用来显示调试信息。
3. 程序员经常会遇到脱离java ide环境调试程序的情况,这时大多数人会选择使用System.out.println语句输出某个变量值的方法进行调试。这样会带来一个非常麻烦的问题:一旦哪天程序员决定不要显示这些System.out.println的东西了就只能一行行的把这些垃圾语句注释掉。若哪天又需调试变量值,则只能再一行行去掉这些注释恢复System.out.println语句。
使用log4j可以很好的处理类似情况。
5.为什么DB的设计中要使用Long来替换掉Date类型?
1. 因为DATE有固定的格式,不同的地区有不同的时间表示方法,而且外国有夏令时与冬令时之分,非常麻烦
2. 其实使用Long也能较为清晰的表示时间
3. 大多数时候我们并不关心某一个时间点,而是发生一个动作后,需要的时间,Long非常方便做减法而不用转化
6.自增ID有什么坏处?什么样的场景下不使用自增ID?
自增ID的坏处:不利于检索、外键关联,多数据库同步 读写分离 十分不方便。
若是能够有其他的字段作为主键保证唯一性,无需使用自增ID。
7.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
自己测试数据量设置的100万,此时有索引比无索引就快。
当数据量大时,就该对字段建索引
8.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
1、普通索引
普通索引(由关键字key或index定义的索引)的唯一任务是加快对数据的访问速度。因此,应该只为那些最经常出现在查询条件(wherecolumn=)或排序条件(orderbycolumn)中的数据列创建索引。只要有可能,就应该选择一个数据最整齐、最紧凑的数据列(如一个整数类型的数据列)来创建索引。普通索引允许被索引的数据列包含重复的值。比如说,因为人有可能同名,所以同一个姓名在同一个“员工个人资料”数据表里可能出现两次或更多次。
2、唯一索引
如果能确定某个数据列将只包含彼此各不相同的值,在为这个数据列创建索引的时候就应该用关键字UNIQUE把它定义为一个唯一索引。这么做的好处:一是简化了mysql对这个索引的管理工作,这个索引也因此而变得更有效率;二是mysql会在有新记录插入数据表时,自动检查新记录的这个字段的值是否已经在某个记录的这个字段里出现过了;如果是,mysql将拒绝插入那条新记录。也就是说,唯一索引可以保证数据记录的唯一性。事实上,在许多场合,人们创建唯一索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复。
什么情况下需要唯一索引?
1: 基本原则是如果表中某列在查询过程中使用的非常频繁,那就在该列上创建索引。如where条件后经常使用的字段,且字段数据唯一的话,最好建立唯一索引
2: 该字段的内容不是唯一的几个值。也就是不是什么情况都非得建索引不可,比如性别可能就只有两个值,建索引不仅没什么优势,还会影响到更新速度,这被称为过度索引
3: 字段内容不是频繁变化
4:表记录太少的肯定不需要
9.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
不需要,当插入数据的时候系统会进行检查,如果已经存在就会报错
10.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
CreateAt应该是在插入数据的时候赋值;UpdateAt应该是修改数据的时候赋值;会有通过框架进行数据库的操作,所以我认为应该开发。
11.修真类型应该是直接存储Varchar,还是应该存储int?
??????什么是修真类型
12.varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
一般预先估计下字段长度进行设置。长度不要超过5000,如果超过长度定义为text类型。
text最大为2^16,LongText为2^32
13.怎么进行分页数据的查询,如何判断是否有下一页?
使用limit进行分页查询,例如:
select * from tableName where fieldName like "%${value}%"limit 5
14.为什么不可以用Select * from table?
使用*会查询所有字段,会降低查询效率
15.什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
领域模型是领域内的概念类或现实世界中对象的可视化表示,又称为概念模型或分析对象模型,它专注于分析问题领域本身,发掘重要的业务领域概念,并建立业务领域概念之间的关系。
贫血模型是指使用的领域对象中只有setter和getter方法(POJO),所有的业务逻辑都不包含在领域对象中而是放在业务逻辑层。有人将我们这里说的贫血模型进一步划分成失血模型(领域对象完全没有业务逻辑)和贫血模型(领域对象有少量的业务逻辑),我们这里就不对此加以区分了。充血模型将大多数业务逻辑和持久化放在领域对象中,业务逻辑(业务门面)只是完成对业务逻辑的封装、事务和权限等的处理。下面两张图分别展示了贫血模型和充血模型的分层架构。更加细粒度的有失血模型,贫血模型,充血模型,胀血模型。贫血模型就是domain ojbect包含了不依赖于持久化的领域逻辑,而那些依赖持久化的领域逻辑被分离到Service层。失血模型简单来说,就是domain object只有属性的getter/setter方法的纯数据类,所有的业务逻辑完全由business object来完成(又称Transaction Script),这种模型下的domain object被Martin Fowler称之为“贫血的domain object”。充血模型和第二种模型差不多,所不同的就是如何划分业务逻辑,即认为,绝大多业务逻辑都应该被放在domain object里面(包括持久化逻辑),而Service层应该是很薄的一层,仅仅封装事务和少量逻辑,不和DAO层打交道。
16.Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
IOC的另一种说法是“控制反转”,通俗的理解是:平常我们new一个实例,这个实例的控制权是我们程序员,而控制反转是指new实例工作不由我们程序员来做而是交给spring容器来做。
使用IOC的原因:在传统的程序设计过程中,调用者直接使用new创建被调用者的实例,调用者和被调用者之间的耦合度很高,要由调用者亲自创建被调用者的实例对象,不利于软件的移植与维护
17.为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
Java只允许一个类只能继承一个抽象类,而一个类可以继承多个接口,接口与实现不分离,则只能继承一个抽象类,但有时候需要继承多个。因此这些方法可以在不同的地方被不同的类实现,而这些实现类,可以具有不同的行为。接口是个规范,接口进行了抽象,实现多态。将Dao层和程序上面的其他部分分开了,当需要调用的时候也只是调用的接口的引用。
18.为什么要处理异常,Try/Catch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发 生一次?
异常exception
异常是程序中的一些错误,但并不是所有的错误都是异常,并且错误有时候是可以避免的。
异常发生的原因有很多,通常包含以下几大类:
1.用户输入了非法数据。
2.要打开的文件不存在。
3.网络通信时连接中断,或者JVM内存溢出。
Try/catch语法
使用 try 和 catch 关键字可以捕获异常。
try/catch 代码块放在异常可能发生的地方。try/catch代码块中的代码称为保护代码。
一个 try 代码块可以后面跟随多个 catch 代码块,叫多重捕获。
如果一个方法没有捕获一个检查性异常,那么该方法必须使用 throws 关键字来声明。throws 关键字放在方法签名的尾部。也可以使用 throw 关键字抛出一个异常,无论它是新实例化的还是刚捕获到的。
java提供了抛出异常捕获异常的逻辑用于处理异常,当程序抛出异常时,如果不存在捕获异常逻辑,正在执行的方法将停止执行,并将该异常向外抛出,调用该方法的程序进行同样的处理,如果也没有进行捕获,则将一层一层的向外抛出,直到到达当前线程处时将会终止线程的执行。
正常情况下mysql对于空闲的连接可能会8小时自动关闭。
19.日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
在业务执行中,每一个步骤判断执行成功与否都要打日志,对于异常,视情况记录日志并进行相应处理。
需要打印出当前执行操作的如id,正在操作的对象,异常的具体内容等等。
20.为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
单步调试是指程序开发中,为了找到程序的bug,通常采用的一种调试手段,一步一步跟踪程序执行的流程,根据变量的值,找到错误的原因。
21.可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
在本地写代码时,如果程序出现问题了,在程序中打的各种log,可以帮助我们调试,找出问题,修改,测试,部署到服务器,再测试。但如果在真实项目中的呢,这样做虽然也可以,显然是不方便的。
真实项目中通过远程连接进行调试,服务端执行代码,而本地通过远程连接,到服务器获取数据和运行结果的方法。方式有很多如web、ide等。




评论