今天完成的事情:
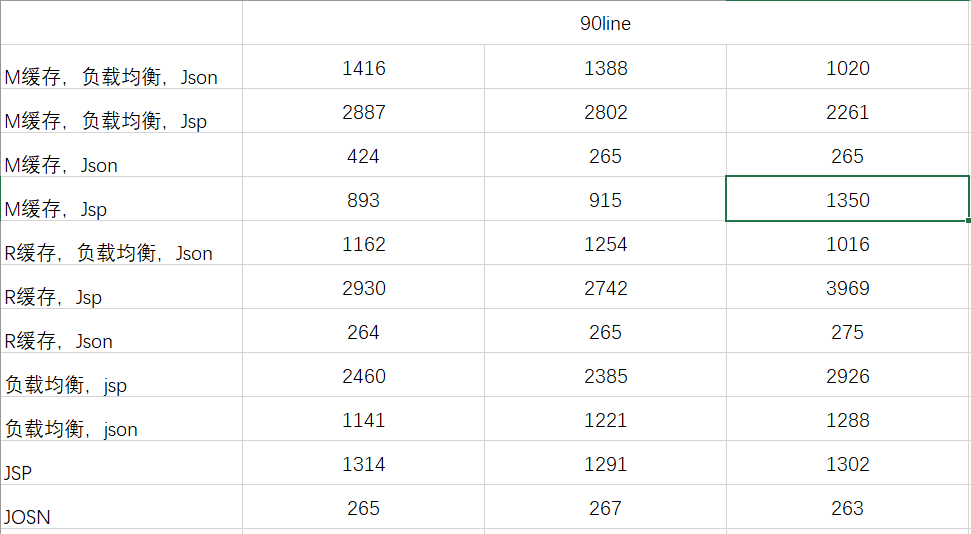
早上着重做了一下压力测试,但是逻辑出错,只好重新新建了一下系统,整理好了逻辑重新做了一下压测。大致的结果如下:
然后看了看验收,还有缓存穿透。
首先我们来看看缓存穿透的定义:
缓存穿透是指查询一个一定不存在的数据,由于缓存不命中,并且出于容错考虑, 如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
也就是客户在读取数据的时候,向服务器提交了一个不存在于数据库的数据申请,不存在的数据是不会写入数据库,也就不会出现在缓存中,于是就会导致读取数据就要去数据库读取。那结合下面遇到的问题,缓存也就失去了意义。
就像下图一样

这只是读取一次读取一条的时候,如果是大量的数据呢?那简直不可想象。
那么如何防止这种状况呢?
处理方式之一是,在将空数据作为缓存写入缓存层,来避免查询数据库。

返回的结果如下:
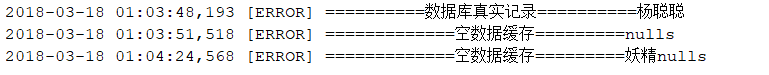
明天计划的事情:完成任务六最后的步骤,然后开始任务六。
遇到的问题:
1.因为在初步判断缓存的时候,使用了count数据库记录,但是师兄说,count也是遍历了数据库的,这样建立的缓存形同虚设。然后大概查了一下关于count与select的性能对比。除了两者的操作不同(一般情况下,Clustered Index Seek的速度应该快于Index Scan),CPU Cost是近似的,Number of Rows是一样的,最大的差别在I/O Cost上,前者是后者的5倍!
究其原因,主要是因为SQL Server执行Count操作的策略。当建有索引时,而且Count的参数是*或者Not Null类型的字段时,SQL Server会对所有索引列中体积最小的索引进行Scan。而istrue字段是bit类型的,只占1个字节,[date]字段是smalldatetime类型的,占4个字节。检索前者的I/O自然远远小于检索后者的,在同样的内存条件下,通过前者检索花费的时间也要远小于后者。
当然,如果Count的参数是某个Null类型的字段,SQL Server则只能对该字段进行Scan,因为这时该字段为Null的记录不记录的。所以,一个优化建议是,尽量少用Null类型字段,使用默认值+bit类型的索引字段会提高Count检索的效率。
另外:关于where条件
COUNT时的WHERE
简单说下,就是COUNT的时候,如果没有WHERE限制的话,MySQL直接返回保存有总的行数
而在有WHERE限制的情况下,总是需要对MySQL进行全表遍历。
优化总结:
1.任何情况下SELECT COUNT(*) FROM tablename是最优选择;
2.尽量减少SELECT COUNT(*) FROM tablename WHERE COL = ‘value’ 这种查询;
3.杜绝SELECT COUNT(COL) FROM tablename WHERE COL2 = ‘value’ 的出现。
2.在服务器使用redis缓存的时候,无法连接到服务器,然后360浏览器就不断的处在连接状态。
然后如果服务端没有启动redis也会报错:
这种就需要在服务器端启动redis之后,启动redis客户端,输入:
config set protected-mode "no"
然后重新链接服务器就好。
收获:
1.在编写程序逻辑的时候,要尽量多想想程序可能被使用的情况,这样才能够编写适应性更强的逻辑处理。
进度:
任务开始时间:2018年02月08日
预计demo时间:2018年03月17日
http://task.ptteng.com/zentao/project-task-490.html
.png)
.png)




评论