发表于: 2018-03-16 23:31:38
1 665
今天完成的事情:
一、基础知识
1.重写toString方法后,直接输出对象名后就会输出该对象重写的属性,如重写了name和age,那么输出的就是name和age,personID就不会输出,而如果没有重写toString方法的话,输出的就是该变量名指向的引用。
2.ArrayList常用方法
①add:增加一个新对象到容器中
第一种是直接add对象,把对象加在最后面heros.add(new Hero("hero"+i));
第二种是在指定位置加对象,heros.add(3,specialHero);
②contains:判断一个对象是否在容器中
判断标准: 是否是同一个对象,而不是name是否相同
③get:获取指定位置的对象,下标越界就会报错
④indexOf:判断一个对象在容器中所处的位置,不存在就返回-1
⑤remove:用于把对象从容器中删除,可以使用下标,也可以使用对象名
⑥set:用于替换指定位置的元素,注意区别add的第二种
heros.set(5,new Hero("lasthero"));
⑦size:获取容器大小,返回一个int值
⑧toArray:把一个ArrayList对象转换为数组
⑨addAll:将另一个容器所有对象加在当前容器后面
heros.addAll(anotherHeros);
⑩clear:清空一个容器
3.泛型Generic
不指定泛型的容器,可以存放任何类型的元素,如List heros=new ArrayList();里面可以放各种类型对象
指定了泛型的容器,只能存放指定类型的元素以及其子类,List<Hero> heros=new ArrayList<>();里面只能放Hero以及其子类
4.LinkedList实现了双向链表结构,只能在队首和队尾插入移除对象,
5.序列分先进先出FIFO,先进后出FILO
FIFO在Java中又叫Queue 队列 ,类似排队打饭
FILO在Java中又叫Stack 栈,类似子弹夹上弹
6.二叉树由各种节点组成
二叉树特点:每个节点都可以有左子节点,右子节;每一个节点都有一个值
二叉树可以对插入数据进行排序,插入基本逻辑是,小、相同的放左边,大的放右边,再将插入的数据遍历输出即可
二叉树的遍历分左序,中序,右序
左序即: 中间的数遍历后放在左边
中序即: 中间的数遍历后放在中间
右序即: 中间的数遍历后放在右边
7.HashMap储存数据的方式是—— 键值对
对于HashMap而言,key是唯一的,不可以重复的。
所以,以相同的key 把不同的value插入到 Map中会导致旧元素被覆盖,只留下最后插入的元素。
不过,同一个对象可以作为值插入到map中,只要对应的key不一样
8.Collections是一个类,容器的工具类,就如同Arrays是数组的工具类
①reverse:使List中的数据发生反转
②shuffle:打乱list中数据的顺序
③sort:对List中的数据进行排序
④swap: 交换两个数据的位置 Collections.swap(numbers,0,5);
⑤rotate :把List中的数据,向右滚动指定单位的长度 Collections.rotate(numbers,2);
⑥synchronizedList:把非线程安全的List转换为线程安全的List, Collections.synchronizedList(numbers);
二、Spring
1.Spring是一个基于IOC和AOP的结构J2EE系统的框架
IOC 反转控制 是Spring的基础,Inversion Of Control
简单说就是创建对象由以前的程序员自己new 构造方法来调用,变成了交由Spring创建对象
DI 依赖注入 Dependency Inject. 简单地说就是拿到的对象的属性,已经被注入好相关值了,直接使用即可。
创建HelloWorld类,一个用传统方式创建,一个使用spring创建
public class HelloWorld { //创建HelleWorld类
private String name; //基本属性name及设置方法
public void setName(String name){
this.name=name;
}
public void sayHello(){ //基本方法
System.out.println("Hello"+name);
}
}
public class Test1 { //传统方式
public static void main(String[] args) {
HelloWorld helloWorld=new HelloWorld(); //①先创建HelloWorld类对象,利用构造方法new一个新对象出来
helloWorld.setName("Spring"); //②设置新对象的姓名为Spring
helloWorld.sayHello(); //③适用对象调用方法
}
}
在src文件下的spring-config.xml里添加设置
<bean id="hellospring" class="HelloWorld"> //id(即name)为获取bean时的对应口令,相当于mybatis-config.xml中的id
<property name="name" value="Spring"></property> //对name属性赋值Spring
</bean>
<bean id="helloworld" class="HelloWorld"> //class是此条bean作用的类,可以写完整路径,同一个包中也可以缩写
<property name="name" value="World"></property>
</bean>
public class Test2 {
public static void main(String[] args) {
ApplicationContext context=new ClassPathXmlApplicationContext("spring-config.xml");//连接xml文件创建IOC容器
HelloWorld helloWorld=(HelloWorld) context.getBean("helloworld"); //通过id从IOC中获取Bean实例
helloWorld.sayHello(); //直接使用对象调用方法
HelloWorld helloSpring=(HelloWorld) context.getBean("hellospring");
helloSpring.sayHello();
}
}
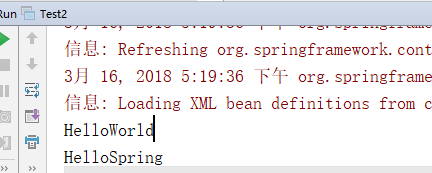
可以看到Spring帮我们完成了前2步,也就是创建实例对象以及设置对象的属性,也就是说我们可以把对象的创建和管理工作交给Spring去完成,不需要自己去new对象,也不要去设置对象的属性,只要写好Spring的配置文件,Spring就可以帮我们去做,当我们需要对象的时候,直接去找Spring去要就行。
IOC是反转控制 (Inversion Of Control)的缩写,就像控制权从本来在自己手里,交给了Spring。
打个比喻:
传统方式:相当于你自己去菜市场new 了一只鸡,不过是生鸡,要自己拔毛,去内脏,再上花椒,酱油,烤制,经过各种工序之后,才可以食用。
用 IOC:相当于去馆子(Spring)点了一只鸡,交到你手上的时候,已经五味俱全,你就只管吃就行了。
2.当一个类中包含另外一个子类时,可以使用ref代替value,将子类对象注入这个类中,即注入的是一个类对象而不是单纯的属性时,使用ref代替value
但是也需要在xml中设置子类的id和class
</bean>
<bean name="c" class="Category">
<property name="name" value="category 1" />
</bean>
<bean name="p" class="Product">
<property name="name" value="product1" />
<property name="category" ref="c" />
</bean>
3.什么是注解
传统的Spring做法是使用.xml文件来对bean进行注入或者是配置aop、事物,这么做有两个缺点:
①如果所有的内容都配置在.xml文件中,那么.xml文件将会十分庞大;如果按需求分开.xml文件,那么.xml文件又会非常多。总之这将导致配置文件的可读性与可维护性变得很低
②在开发中在.java文件和.xml文件之间不断切换,是一件麻烦的事,同时这种思维上的不连贯也会降低开发的效率
为了解决这两个问题,Spring引入了注解,通过"@XXX"的方式,让注解与Java Bean紧密结合,既大大减少了配置文件的体积,又增加了Java Bean的可读性与内聚性。
4.@Autowired
@Autowired顾名思义,就是自动装配,其作用是为了消除代码Java代码里面的getter/setter与bean属性中的property。当然,getter看个人需求,如果私有属性需要对外提供的话,应当予以保留。
首先需要在配置文件中添加
<context:annotation-config/> //需加此声明
<bean name="c" class="Category">
<property name="name" value="category 1" />
</bean>
<bean name="p" class="Product">
<property name="name" value="product1" />
<!-- <property name="category" ref="c" /> --> //此处可通过注解来注入
</bean>
告诉spring要使用注解的方式来配置了
public class Product {
private int id;
private String name;
@Autowired //在上下文找到Category,然后注入到Product中
private Category category;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Category getCategory() {
return category;
}
/* @Autowired //也可以在此处添加注解,效果一样,但是setCategory是可以删除不影响的
public void setCategory(Category category) {
this.category = category;
}*/
}
public class TestSpring {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext(new String[] { "spring-config.xml" });
Product p = (Product) context.getBean("p");
System.out.println(p.getName());
System.out.println(p.getCategory().getName());
}
}
这里@Autowired注解的意思就是,当Spring发现@Autowired注解时,将自动在代码上下文中找到和其匹配(默认是类型匹配)的Bean,并自动注入到相应的地方去。
5. @Resource的作用相当于@Autowired,只不过@Autowired按byType自动注入,而@Resource默认按 byName自动注入罢了。@Resource有两个属性是比较重要的,分是name和type,Spring将@Resource注解的name属性解析为bean的名字,而type属性则解析为bean的类型。所以如果使用name属性,则使用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。如果既不指定name也不指定type属性,这时将通过反射机制使用byName自动注入策略。
@Resource装配顺序
①如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常
② 如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常
③ 如果指定了type,则从上下文中找到类型匹配的唯一bean进行装配,找不到或者找到多个,都会抛出异常
④ 如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配;
6.@Autowired 与@Resource的区别:
① @Autowired与@Resource都可以用来装配bean. 都可以写在字段上,或写在setter方法上。
② @Autowired默认按类型装配(这个注解是属于spring的),默认情况下必须要求依赖对象必须存在,如果要允许null值,可以设置它的required属性为false,如:@Autowired(required=false) ,如果我们想使用名称装配可以结合@Qualifier注解进行使用,如下:
@Autowired()
@Qualifier("baseDao")
private BaseDao baseDao;
③@Resource(这个注解属于J2EE的),默认安装名称进行装配,名称可以通过name属性进行指定,如果没有指定name属性,当注解写在字段上时,默认取字段名进行安装名称查找,如果注解写在setter方法上默认取属性名进行装配。当找不到与名称匹配的bean时才按照类型进行装配。但是需要注意的是,如果name属性一旦指定,就只会按照名称进行装配。
@Resource(name="baseDao")
private BaseDao baseDao;
推荐使用:@Resource注解在字段上,这样就不用写setter方法了,并且这个注解是属于J2EE的,减少了与spring的耦合。这样代码看起就比较优雅。
7.上面这个例子,还可以继续简化,因为spring的配置文件里面还有两个bean,下一步的简化是把这两个bean也给去掉,使得spring配置文件里面只有一个自动扫描的标签,增强Java代码的内聚性并进一步减少配置文件。
<context:component-scan base-package="com.spring"/>
配置文件中只留这个表明Bean都在此包下。
为Product类加上@Component注解,即表明此类是bean
@Component("p")
public class Product {
为Category 类加上@Component注解,即表明此类是bean
@Component("c")
public class Category {
因为没有自动填充属性所以属性在定义时就需要对其初始化
private String name="product1";
private String name="category1";
此时,TestSpring结果与上面是一样的
明天计划的事情:(一定要写非常细致的内容)
继续奋战spring
遇到的问题:(遇到什么困难,怎么解决的)
对于注解的原理还是理解的不太透彻,然后对spring介绍里说的优点处于迷蒙状态
收获:(通过今天的学习,学到了什么知识)
对spring有了一个初步的了解




评论