发表于: 2018-03-15 22:44:11
1 531
今天完成的事情:(一定要写非常细致的内容,比如说学会了盒子模型,了解了Margin)
一、I/O
1.当不同的介质之间有数据交互的时候,JAVA就使用流来实现。
数据源可以是文件,还可以是数据库,网络甚至是其他的程序。
比如读取文件的数据到程序中,站在程序的角度来看,就叫做输入流,将内存看作我们的大脑,那么read看的过程就是输入的过程,write写的过程就是输出的过程
输入流: InputStream
输出流:OutputStream
InputStream和OutputStream是抽象类,只提供方法声明,不提供方法的具体实现,是所有对应输入输出类的超类。
2.建立了一个流对象相当于建立了一条从内存到目标文件的管道
如FileInputStream fis=new FileInputStream(f);意思是建立到文件f的管道fis,此管道可以将文件f的信息输送给内存
3.创建一个文件对象有三种构造方法
①File f=new File(String pathname);pathname为路径名称(包含文件名),如下例
②File f=new File(String parent,String child);parent为父路径字符串,child为子路径字符串(含文件名)
③File f=new File(File fp,String child);fp为父路径对象
4.一般可以将输入的过程分为三步
①创建目标文件,即我要从哪里把文件输入内存
②建立连接,即创建输入流对象
③以输入流对象调用输入的方法将数据输入内存中准备好的接收对象中
public class TestFile {
public static void main(String[] args) {
try {
//①准备文件lol.txt其中的内容是ab,对应的ASCII分别是97 98
File f =new File("e:/lol.txt");
//②创建基于文件的字节输入流
FileInputStream fis =new FileInputStream(f);
//创建字节数组,其长度就是文件的长度
byte[] all =new byte[(int) f.length()];
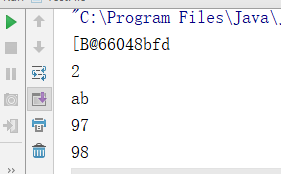
System.out.println(all); //从输出结果可以看到all本身是一个引用
System.out.println(fis.read(all)); //从输出结果可以看到fis.read(all)返回的是文件的长度,也就是上面的f.length()
//③以字节流的形式读取文件所有内容,其返回值是代表此数据长度的int类型的数,但是操作本身已经将数据存入了all的引用
fis.read(all);
System.out.println(new String(all,0,2)); //使用字符串的形式输出的话就可以输出ab了
for (byte b : all) {
//打印出来是97 98
System.out.println(b);
}
如果第②步创建的是字符输入流FileReader fr=new FileReader(f);并将所有byte改为char,那么for循环出来的就直接是ab而不是ASCII码了
5.以字符输出流的方式将字符存入文件
public class TestFile2 {
public static void main(String[] args) {
File f=new File("e:/lol2.txt");
try (FileWriter fw=new FileWriter(f)){
String s="12458uhjnh";
char[] cs=s.toCharArray(); //将其转化为一组字符
fw.write(cs);
fw.close();
}catch (Exception e){
}
}
}
6.FileReader使用的编码方式是系统默认编码方式的返回值,中文操作系统一般是GBK,所以若文件中使用的是非GBK的编码,就会产生乱码,而且FileReader是不能自己设置输出编码格式的,所以此时可以用InputStreamReader来代替。语法如下
new InputStreamReader(new FileInputStream(f),Charset.forName("UTF-8"));
7.以介质是硬盘为例,字节流和字符流的弊端:
在每一次读写的时候,都会访问硬盘。 如果读写的频率比较高的时候,其性能表现不佳。
为了解决以上弊端,采用缓存流。
缓存流在读取的时候,会一次性读较多的数据到缓存中,以后每一次的读取,都是在缓存中访问,直到缓存中的数据读取完毕,再到硬盘中读取。
就好比吃饭,不用缓存就是每吃一口都到锅里去铲。用缓存就是先把饭盛到碗里,碗里的吃完了,再到锅里去铲
缓存流在写入数据的时候,会先把数据写入到缓存区,直到缓存区达到一定的量,才把这些数据,一起写入到硬盘中去。按照这种操作模式,就不会像字节流,字符流那样每写一个字节都访问硬盘,从而减少了IO操作
public class IoTest {
public static void main(String[] args) {
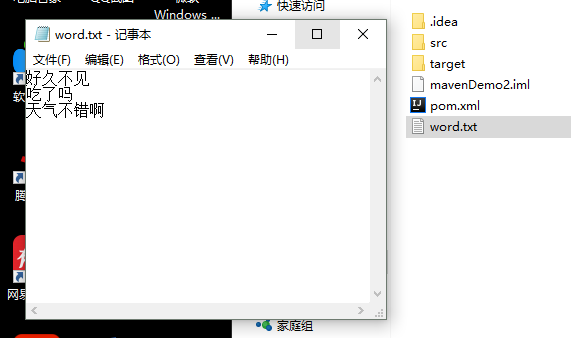
String content[]={"好久不见","吃了吗","天气不错啊"};
File file=new File("word.txt");
try{
FileWriter fw=new FileWriter(file);
BufferedWriter bufw=new BufferedWriter(fw); //可以看出BufferedWriter是要在新建FlieWriter对象后继续针对此对象新建对象的
for(int i=0;i<content.length;i++){
bufw.write(content[i]); //分步写入数据
bufw.newLine();
}
bufw.close();
fw.close();
}catch (Exception e){
e.printStackTrace();
}try{
FileReader fr=new FileReader(file);
BufferedReader bufr=new BufferedReader(fr);
String s=null;
int k=0;
while((s=bufr.readLine())!=null){ //当此行不为空则进入循环输出读取的这一行的内容
k++;
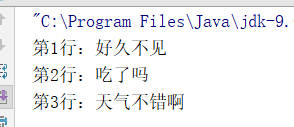
System.out.println("第"+k+"行:"+s);
}
bufr.close();
fr.close();
}catch (Exception e){
e.printStackTrace();
}
}
}
使用flush();方法可在输出信息时不等缓存直接全部写入
8.使用数据流的writeUTF()和readUTF() 可以进行数据的格式化顺序读写
注:要用DataInputStream 读取一个文件,这个文件必须是由DataOutputStream 写出的,否则会出现EOFException,因为DataOutputStream 在写出的时候会做一些特殊标记,只有DataInputStream 才能成功的读取。
并且必须按照写入的顺序进行读出。通过数据流输出保存在文档中的信息是乱码的,不能直接看,却可以通过数据流输入重新在Java中读出来,如下
public class IoTest1 {
public static void main(String[] args) {
try{
FileOutputStream fs=new FileOutputStream("word.txt");
DataOutputStream ds=new DataOutputStream(fs);
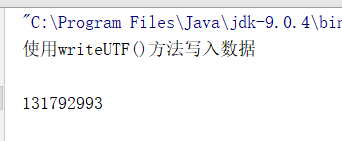
ds.writeUTF("使用writeUTF()方法写入数据");
ds.writeInt(2011);
ds.writeChar('a');
ds.close();
FileInputStream fis=new FileInputStream("word.txt");
DataInputStream dis=new DataInputStream(fis);
System.out.println(dis.readUTF());
System.out.println(dis.readChar()); //这里调换了读出的顺序
System.out.println(dis.readInt());
}catch (Exception e){
e.printStackTrace();
}
}
}
明天计划的事情:(一定要写非常细致的内容)
明天看spring了,在这个上面墨迹了一天
遇到的问题:(遇到什么困难,怎么解决的)
有的概念理解还不是太清楚,比如那几种方式创建对象的过程
收获:(通过今天的学习,学到了什么知识)
了解一些关于数据流的比较浅层的知识点




评论