发表于: 2018-03-14 22:44:15
1 577
今天完成的事情:(一定要写非常细致的内容,比如说学会了盒子模型,了解了Margin)
一、Log4j的学习
1.什么是log4j,有什么用
即log for java,可以理解为java的日志,是Apache为了帮助开发者记录程序日志信息而开发的一个操作包。
它可以设置日志输出的位置,级别,格式等,只需在配置文件中调整参数而不需在程序中修改代码。
2.如何使用默认配置
一般我们使用log4j有三种配置方式,即默认配置,properties文件配置,xml文件配置
默认配置由于格式、输出位置等因素固定,所以一般不使用,其在使用前一般进行下面几步
①导入jar包
②创建对象 static Logger logger = Logger.getLogger(TestLog4j.class);
③加载默认配置 BasicConfigurator.configure();
④设置级别 logger.setLevel(Level.DEBUG);
⑤利用对象logger调用方法输出信息
注:level是日志记录的优先级,一般通常分为四种,从高到低依次为error,warn,info,debug
3.如何配置log4j.properties及其中各字段含义
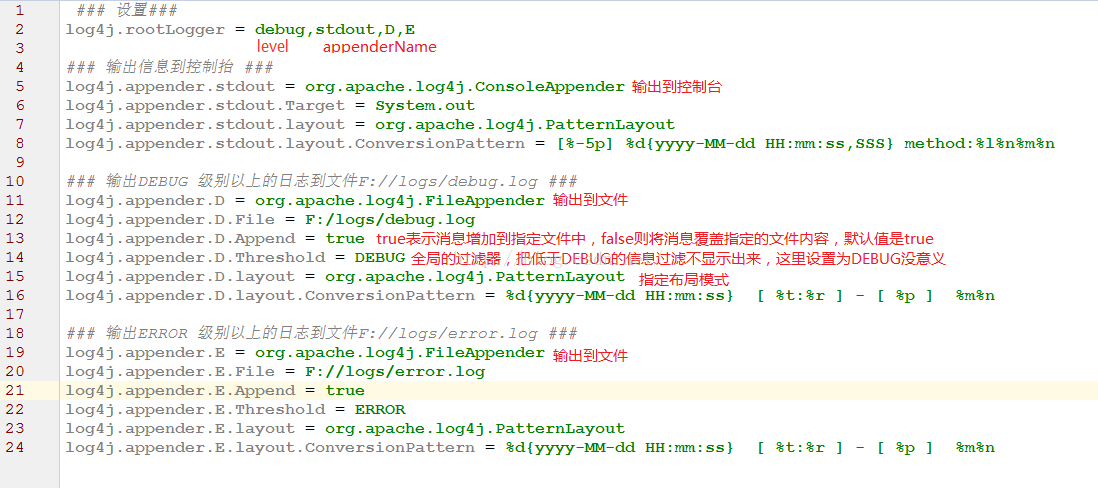
①在resorces下新建log4j.properties,示例配置如下
### 设置###
log4j.rootLogger = debug,stdout,D,E
### 输出信息到控制台 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
### 输出DEBUG 级别以上的日志到=F://logs/error.log ###
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = F://logs/debug.log
log4j.appender.D.Append = true
log4j.appender.D.Threshold = DEBUG
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
### 输出ERROR 级别以上的日志到=F://logs/error.log ###
log4j.appender.E = org.apache.log4j.DailyRollingFileAppender
log4j.appender.E.File =F://logs/error.log
log4j.appender.E.Append = true
log4j.appender.E.Threshold = ERROR
log4j.appender.E.layout = org.apache.log4j.PatternLayout
log4j.appender.E.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
②其中第一行debug为输出级别,stdout和D,E为自己起的输出目的地名称,可同时指定多个
③第二行指定stdout的输出位置,其中主要分为五种org.apache.log4j.ConsoleAppender(控制台)org.apache.log4j.FileAppender(文件),org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件),org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件),可通过log4j.appender.R.MaxFileSize=100KB设置文件大小,还可通过log4j.appender.R.MaxBackupIndex=1设置为保存一个备份文件。org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
④第四行layout配置日志信息格式,主要分为以下几种org.apache.log4j.HTMLLayout(以HTML表格形式布局),org.apache.log4j.PatternLayout(可以灵活地指定布局模式),org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串),org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
⑤第五行就是格式化的语句,主要包括以下几种
%m 输出代码中指定的消息;
%M 输出打印该条日志的方法名;
%p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL;
%r 输出自应用启动到输出该log信息耗费的毫秒数;
%c 输出所属的类目,通常就是所在类的全名;
%t 输出产生该日志事件的线程名;
%n 输出一个回车换行符,Windows平台为"rn”,Unix平台为"n”;
%d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyyy-MM-dd HH:mm:ss,SSS},输出类似:2015-12-14 16:25:55,921;
%l 输出日志事件的发生位置,及在代码中的行数。
⑥第七行需要将信心输出指定位置文件,之前需要自己新建log文件
4.在程序中使用
在昨天的PersonMapperTest中测试,
private static Logger logger = Logger.getLogger(PersonMapperTest.class);
@Test
public void getPerson() {
PropertyConfigurator.configure("F:\\java\\IdeaProjects\\MybatisTest01\\src\\main\\resources\\log4j\\log4j.properties");
logger.info("测试输出信息");
System.out.println( personMapper.getPerson(1409));
但是操作后遇到如下提示,
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/E:/repository/org/slf4j/slf4j-nop/1.7.25/slf4j-nop-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/E:/repository/org/slf4j/slf4j-simple/1.7.5/slf4j-simple-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/E:/repository/org/slf4j/slf4j-log4j12/1.7.25/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.helpers.NOPLoggerFactory]
百度后发现意思是说这几个Jar包存在冲突
打开右边maven界面,选择dependenciens,ctrl+shift+alt+u可以调出maven的依赖树,ctrl+滚轮可以放大,其中红色的线就是起冲突的Jar包
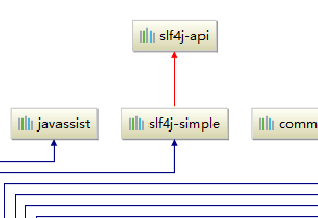
可以看到的确是这几个包起了冲突,删掉前两个包后继续运行可得到如下结果
[INFO ] 2018-03-14 16:32:06,023 method:mapper.PersonMapperTest.getPerson(PersonMapperTest.java:63)
测试输出信息
[DEBUG] 2018-03-14 16:32:06,045 method:org.apache.ibatis.transaction.jdbc.JdbcTransaction.openConnection(JdbcTransaction.java:138)
Opening JDBC Connection
[DEBUG] 2018-03-14 16:32:06,850 method:org.apache.ibatis.datasource.pooled.PooledDataSource.popConnection(PooledDataSource.java:387)
Created connection 609656250.
[DEBUG] 2018-03-14 16:32:06,854 method:org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:142)
==> Preparing: select * from person1 where id=?
[DEBUG] 2018-03-14 16:32:07,005 method:org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:142)
==> Parameters: 1409(Integer)
[DEBUG] 2018-03-14 16:32:07,099 method:org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:142)
<== Total: 1
Person{id=1409,name=lisi8,age=23,personID=20111111}
[DEBUG] 2018-03-14 16:32:07,190 method:org.apache.ibatis.transaction.jdbc.JdbcTransaction.close(JdbcTransaction.java:92)
Closing JDBC Connection [com.mysql.jdbc.JDBC4Connection@24569dba]
[DEBUG] 2018-03-14 16:32:07,190 method:org.apache.ibatis.datasource.pooled.PooledDataSource.pushConnection(PooledDataSource.java:344)
Returned connection 609656250 to pool.

可以看到的确是输出了想要的结果但是一些不影响运行的debug也太多了,看得眼花。。。所以可以适当提高级别到info来减少这些信息。
二、关于数组和集合类map,list,set分析对比
1.数组是大小固定的,并且同一个数组只能存放类型一样的数据(基本类型/引用类型),而JAVA集合可以存储和操作数目不固定的一组数据。 所有的 JAVA集合都位于 java.util包中! JAVA集合只能存放引用类型的的数据,不能存放基本数据类型。
- 世间上本来没有集合,(只有数组参考C语言)但有人想要,所以有了集合
- 有人想有可以自动扩展的数组,所以有了List
- 有的人想有没有重复的数组,所以有了set
- 有人想有自动排序的组数,所以有了TreeSet,TreeList,Tree**
- 而几乎有有的集合都是基于数组来实现的.
- 因为集合是对数组做的封装,所以,数组永远比任何一个集合要快
- 但任何一个集合,比数组提供的功能要多
- 一:数组声明了它容纳的元素的类型,而集合不声明。这是由于集合以object形式来存储它们的元素。
- 二:一个数组实例具有固定的大小,不能伸缩。集合则可根据需要动态改变大小。
- 三:数组是一种可读/可写数据结构---没有办法创建一个只读数组。然而可以使用集合提供的ReadOnly方法,以只读方式来使用集合。该方法将返回一个集合的只读版本。
Java所有“存储及随机访问一连串对象”的做法,array是最有效率的一种。但它的容量固定且无法动态改变。
array还有一个缺点是,无法判断其中实际存有多少元素,length只是告诉我们array的容量
2.Java中有一个Arrays类,专门用来操作array。
arrays中拥有一组static函数,
equals():比较两个array是否相等。array拥有相同元素个数,且所有对应元素两两相等。
fill():将值填入array中。
sort():用来对array进行排序。
binarySearch():在排好序的array中寻找元素。
System.arraycopy():array的复制。
3.Collection是最基本的集合接口,声明了适用于JAVA集合(只包括Set和List)的通用方法。 Set 和List 都继承了Conllection。
4.Set是最简单的一种集合。集合中的对象不按特定的方式排序,并且没有重复对象。 Set接口主要实现了两个实现类:
- HashSet: HashSet类按照哈希算法来存取集合中的对象,存取速度比较快
- TreeSet :TreeSet类实现了SortedSet接口,能够对集合中的对象进行排序。
- 5.List的特征是其元素以线性方式存储,集合中可以存放重复对象。
- List接口主要实现类包括:
- ArrayList() : 代表长度可以改变得数组。可以对元素进行随机的访问,向ArrayList()中插入与删除元素的速度慢。
- LinkedList(): 在实现中采用链表数据结构。插入和删除速度快,访问速度慢。
- 6.Map 是一种把键对象和值对象映射的集合,它的每一个元素都包含一对键对象和值对象。 Map没有继承于Collection接口, 从Map集合中检索元素时,只要给出键对象,就会返回对应的值对象。
Map的功能方法
方法put(Object key, Object value)添加一个“值”(想要得东西)和与“值”相关联的“键”(key)(使用它来查找)。方法get(Object key)返回与给 定“键”相关联的“值”。可以用containsKey()和containsValue()测试Map中是否包含某个“键”或“值”。 标准的Java类库中包含了几种不同的Map:HashMap, TreeMap, LinkedHashMap, WeakHashMap, IdentityHashMap。它们都有同样的基本接口Map,但是行为、效率、排序策略、保存对象的生命周期和判定“键”等价的策略等各不相同。
7.Collection 和 Map 的区别
容器内每个为之所存储的元素个数不同。
Collection类型者,每个位置只有一个元素。
Map类型者,持有 key-value pair,像个小型数据库。8.List,Set,Map将持有对象一律视为Object型别。
Collection、List、Set、Map都是接口,不能实例化。 继承自它们的 ArrayList, Vector, HashTable, HashMap是具象class,这些才可被实例化。
这也是为什么昨天操作时是List list=new ArrayList();Map map=New HashMap();
9.① 如果涉及到堆栈,队列等操作,应该考虑用List,对于需要快速插入,删除元素,应该使用LinkedList,如果需要快速随机访问元素,应该使用ArrayList。
② 如果程序在单线程环境中,或者访问仅仅在一个线程中进行,考虑非线程安全的类,其效率较高,如果多个线程可能同时操作一个类,应该使用线程安全的类。③ 在除需要排序时使用TreeSet,TreeMap外,都应使用HashSet,HashMap,因为他们 的效率更高。
④容器类仅能持有对象引用(指向对象的指针),而不是将对象信息copy一份至数列某位置。一旦将对象置入容器内,便损失了该对象的型别信息。
- ⑤Collection没有get()方法来取得某个元素。只能通过iterator()遍历元素。
- ⑥Set和Collection拥有一模一样的接口。
- ⑦List,可以通过get()方法来一次取出一个元素。使用数字来选择一堆对象中的一个,get(0)...。(add/get)⑧Map用 put(k,v) / get(k),还可以使用containsKey()/containsValue()来检查其中是否含有某个key/value。HashMap会利用对象的hashCode来快速找到key。⑨Map中元素,可以将key序列、value序列单独抽取出来。使用keySet()抽取key序列,将map中的所有keys生成一个Set。使用values()抽取value序列,将map中的所有values生成一个Collection。为什么一个生成Set,一个生成Collection?那是因为,key总是独一无二的,value允许重复。
- 三、线程安全和非线程安全
- 线程安全就是多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时,进行保护,其他线程不能进行访问直到该线程读取完,其他线程才可使用。不会出现数据不一致或者数据污染。
- 线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据。
- 线程安全一般都涉及到synchronized 就是一段代码同时只能有一个线程来操作 不然中间过程可能会产生不可预知的结果
- 为了线程安全的目的,会限制多线程同时访问同一对象,这就势必造成了程序运行速度降低,所以我们应在线程速度和安全性上酌情考虑使用线程安全的还是非线程安全的。非线程安全!=不安全,所以即使使用的是多线程,但是只要不同时访问同一对象,那么非线程安全的也不会不安全,也是可以使用的。
明天计划的事情:(一定要写非常细致的内容)
看了下spring涉及I/O流和框架,所以这两个基本知识明天先看一下吧
遇到的问题:(遇到什么困难,怎么解决的)
log4j操作过程中遇到好多问题,总算勉强解决了,还是要争取知其所以然才好
收获:(通过今天的学习,学到了什么知识)
1.以后没事不要瞎点更新,今天早上登陆idea看见有个更新,酷酷的选择了现在更新并重启,点完的瞬间我就后悔了,果然,破解没了。。。到期时间又到了四月份,无奈,只能再去找破解,然后上次的jar破解故技重施居然不行了,估计是被idea公司封杀了,于是又去找其他办法,墨迹了一个多小时,总算是通过修改hosts文件(中间发现权限不够又去找办法改权限)然后使用注册码的办法重新破解了,在感谢那些大神的同时不得不感叹,这种破解版还是能不更新就不更新吧,毕竟我们没交钱,没底气啊。
2.成功输出log4j,虽然暂时对我还没啥用




评论