发表于: 2018-03-13 23:37:56
1 756
今日完成:
1. 简单写一个AOP实现查询所有学生信息,如果memcached存在,则直接从缓存获取,如果缓存中不存在,则从数据库中获取,并且将数据添加到缓存中;如果对数据库进行增,删,改操作,则更新缓存中所有学生信息(这种方法显然逻辑上有错误,因为每次增删改都需要更新缓存)
注解AOP类
@Aspect
@Component
public class MemcachedAspect {
注解注入MemcachedClient
@Autowired
private MemcachedClient memcachedClient;
切点,排除查询单个学生情况
@Pointcut("execution(* com.myitschool.service.StudentService.*(..)) && !execution(* com.myitschool.service.StudentService.selectStudent(..))")
public void studentService() {
}
使用@Around
@Around("studentService()")
public Object studentServiceAround(ProceedingJoinPoint pjp) throws Throwable {
Object result = null;
获取方法
Signature signature = pjp.getSignature();
MethodSignature methodSignature = (MethodSignature) signature;
Method method = methodSignature.getMethod();
try catch防止memcached不可用的情况,例如进程奔溃等,flog判断是否对数据库进行过增删改操作
if ("allStudent" != method.getName()) {
result = pjp.proceed();
flag = true;
} else {
try {
if(flag) {
memcachedClient.set("allStudent", 0, pjp.proceed());
}
result = memcachedClient.get("allStudent");
logger.info("search all from memcached");
} catch (Exception e) {
result = pjp.proceed();
logger.info("search all from mysql");
}
flag =false;
}
return result;
}
停止memcached服务


开启memcached服务


日志:

2. 查看监听端口
最常用的方法:
1,netstat -an
2,lsof -i
以上两个命令通过查询网络堆栈列举正在监听网络的端口。
eg:检查某一端口的监听信息
netstat -anp | grep 端口号
lsof -i | grep 端口号
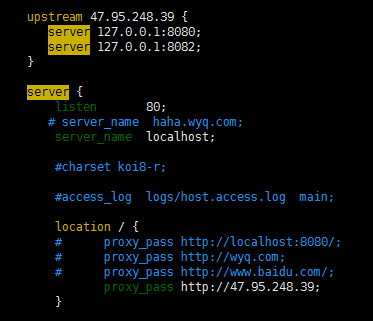
3. 部署两个web服务器
负载均衡+memcached:

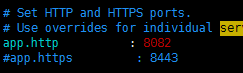
tomcat使用默认8080端口,部署项目
resin使用8082端口,防火墙和阿里云都开放该端口
firewall-cmd --zone=public --add-port=8082/tcp –permanent
netstat anp|grep
nginx负载均衡
4. 缓存穿透http://blog.csdn.net/zeb_perfect/article/details/54135506
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
解决方案
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
5. 缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决方案
缓存失效时的雪崩效应对底层系统的冲击非常可怕。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线 程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。这里分享一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
6. 缓存击穿
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案
1.使用互斥锁(mutex key)
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
2. "提前"使用互斥锁(mutex key):
在value内部设置1个超时值(timeout1), timeout1比实际的memcache timeout(timeout2)小。当从cache读取到timeout1发现它已经过期时候,马上延长timeout1并重新设置到cache。然后再从数据库加载数据并设置到cache中。
3. "永远不过期":
这里的“永远不过期”包含两层意思:
(1) 从redis上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
(2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期
从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。
4. 资源保护:
采用netflix的hystrix,可以做资源的隔离保护主线程池,如果把这个应用到缓存的构建也未尝不可。
明日计划:
1. 将Memcache替换成Redis,重复以步骤。最后生成一份压测报告,同样的发布到自媒体里。
2. 整理任务6知识点
遇到的问题:
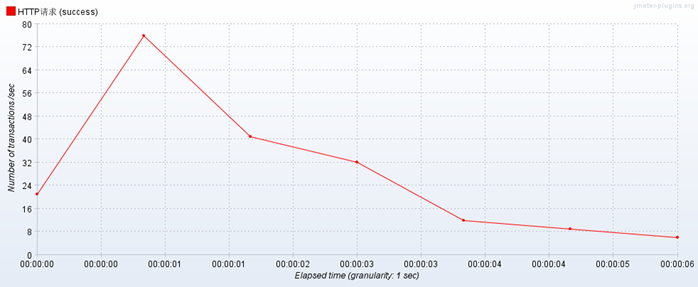
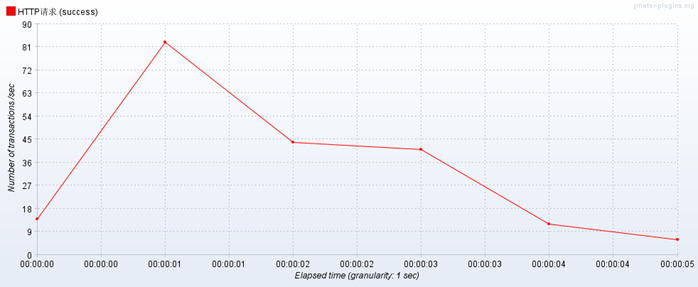
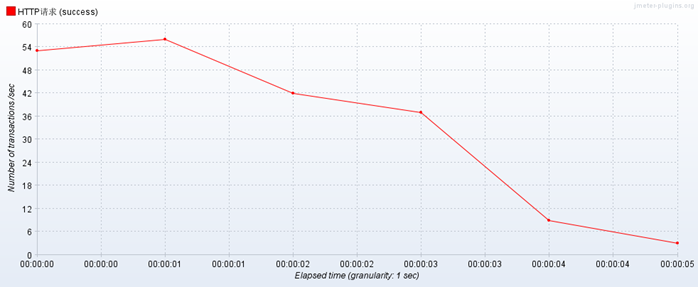
1. 使用nginx做负载均衡,性能测试10线程20循环,前几次很平稳,后来测试相当卡,但是不通过负载均衡,压测单个web项目不会出现这种情况
收获:
1. 编写简单AOP实现memcached针对数据库处理的缓存机制
2. nginx负载均衡,配置resin和tomcat,各部署一个项目,并通过压测




评论