发表于: 2018-03-13 17:37:20
2 592
今天完成的事情
步骤1:首先自然是先去看看报名贴的格式
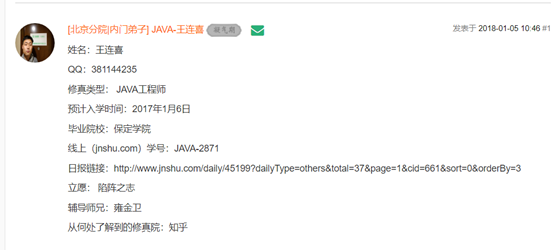
根据情况整理业务模型可知,其实学生的报名贴就是一个对象,而报名贴中的姓名、QQ、修真类型等就是对象的属性。感觉这里没有别的多的对象,如果非要说的话,学生报的班级是一个对象,但这里没有详细的数据,班级与学生的报名贴是以一对多的关系。
步骤2:由于之前学习过数据库的课程,所以mysql已经安装完成了,我安装的版本是5.7
我当时是在官网上下载的https://dev.mysql.com/downloads/mysql/。记得下载的过程中好像有设置root用户密码的过程,密码要记牢了,不然之后可能会很麻烦。
还有就是下载完成之后要配置环境变量,之前做这项事情的时候其实是懵逼的,因为不知道这么做有什么用,反正教程让我这么做就做了。但后来随着数据库的使用以及java的下载也是要配置环境变量的,也就渐渐理解了。根据我现在自己的理解,java和mysql的bin目录下有很多exe后缀的文件,这些文件的名字其实就是一条条指令,我们可以在命令行窗口执行这些指令,但你必须在bin目录下执行,否则系统并不认识这些指令。而环境变量就是将这些目录加入到系统默认路径中去,当你输入指令时,系统默认就会去这些路径下去找指令,接着看几个示范能有更深入的理解。

打开我的电脑,在上方输入cmd按下回车。

可看到当前路径,并不是mysql的bin目录,这时我们输入mysql

可以看出系统并不认识这条指令。
我们将路径切换,可以使用cd命令

也可以关闭命令行窗口,在我们需要的路径上方输入cmd
这时输入mysql

可看出提示信息变了,说明系统是认识这条指令的,这里出现错误是因为我没有开启mysql服务。

若我们设置好了环境变量

即使路径不对,系统也能认识这条命令。环境变量的作用也就显现出来了。
具体怎么设置环境变量百度一下都是,这里就不多说了,但我觉得我们要理解我们为什么要设置环境变量,这样才能灵活的运用。
步骤3:我下载的是navicat,百度一下就可以下到,不过navicat要收费,只能试用两个星期,我是在http://blog.csdn.net/Lian_Easel/article/details/78734240这上面下载的破解工具,很方便,一下就成功了。
还有一点我比较在意的是好像当初在官网下载mysql的时候其实附带着官方的数据库管理工具mysql workbench。我们当初上课的时候老师没让我们用,任务中也没提到。一般来说官方的应该会比较靠谱,可为什么没人用呢?带着这个问题我去百度了一下,发现其实对workbench好评的人也有很多,其实当然是有人用的。不过我想navicat收费自然有它收费的道理,孰优孰劣,或者说它们各自的强项,还是需要在以后的使用中来亲身体验一下。
步骤4:一开始看到的时候是很懵逼的,不知道具体要干什么。但看了看其他师兄的日报就明白了,就是将具体的对象属性转换成英文字符以及为它设置合理的类型。
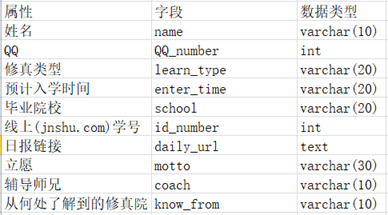
步骤5:按照步骤4所设计好的表很轻松的就在navicat中将表设计好了

步骤6:进入mysql,用sql语句将最近报名的学生的信息用sql语句插入

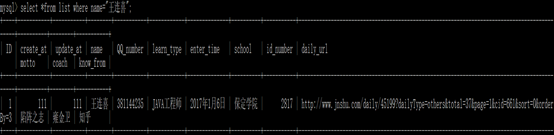
可以通过姓名查出这条记录。
步骤7:在navicat中更改非常简单

只需将蓝色框中的内容改为老大最帅即可。
在mysql中修改,我们需要使用sql语句
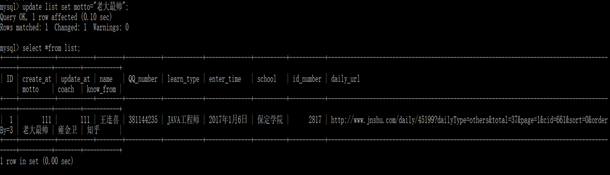
也可以成功修改宣言
步骤8:成功将表导出成sql文件

使用navicat下方的减号即可删除记录

找了半天发现没有哪里可以执行sql脚本,果断百度,原来是在表的结构右键,会弹出运行sql文件选项,执行之前的sql文件即可恢复该条记录。
接着我们去用sql语句删除记录
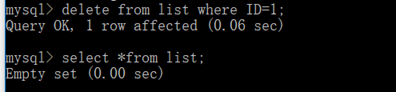
可以看到记录被成功删除了。
步骤9:因为当初学数据库的时候对索引没有深入的了解,所以在做这一步骤之前先去网上补了补课,对索引有了一个大致的了解,这样也方便回答后面的问题。

在navicat中为name添加索引,由于只是处于了解阶段,暂时还不清楚哪种索引类型和方法适用,所以就先随意选择了。
步骤10:
有索引时使用的时间
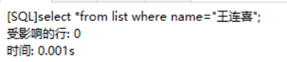
无索引时使用的时间
可以看出,在只有10条记录的情况下,有索引的搜索时间比无索引的快了0.001秒,而现实中我们数据库中存放的往往是成千上万条记录。这个时候使用索引的好处就能够明显的体现出来了。
根据我从网上了解到的关于索引的知识,索引其实就是一种数据结构,它存储的是列的值,根据我的理解它能提前将列中的值按照一定的逻辑分好,当我们需要查询该列的某个值时,不需要遍历表中的每条记录,可能只需要查询一半的记录,就可以找到我们需要找的值。就像之前我们根据姓名来对表中的记录进行检索,由于我们对姓名加了索引,所以我们在以姓名为条件来查询时就可以变快。可能有人会想,索引既然这么好,那我们给所有字段都加上不就好了。其实不然,既然索引是一种数据结构,那么自然要占用额外的存储空间,而且一旦我们对表中的记录进行增删改等操作,索引也要跟着更新,那么性能就会变慢。也就是说索引可以让我们的查询变的更快,但可能会牺牲我们更新记录时的性能。所以,我们只能给我们最需要的地方加索引,也就是可能成为我们查询时条件的字段。根据这个条件我觉得我们还可以给“修真类型”加上索引,因为我们可能想查询报名java工程师的学生,或者报名css的学生。我觉得还可以给“辅导师兄”加上索引,因为我们可能想查询某个师兄他门下有几个好学向上的学生。
明天计划的事情
步骤11:先将深度思考中的几个问题列出
1:为什么DB的设计中要使用Long来替换掉Date类型?
2:自增ID有什么坏处?什么样的场景下不使用自增ID?
3:什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
4:唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
5:如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
6:CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
7:修真类型应该是直接存储Varchar,还是应该存储int?
8:varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
9:怎么进行分页数据的查询,如何判断是否有下一页?
10:为什么不可以用Select * from table?
想对这些问题好好的探索一下,所以就把这些问题留到明天吧,如果明天能很快的解决掉,就完成后面的步骤。
遇到的问题
没遇到什么太大的问题,因为之前还是有一定的数据库基础的。
收获
复习了数据库相关的知识,使用了新的数据库管理工具navicat,能将实际对象转换成数据模型并在数据库中建表与之对应,插入、修改数据等。




评论