发表于: 2018-03-10 23:34:03
1 731
今日完成:
1. 安装JMeter官方TPS图像插件并测试
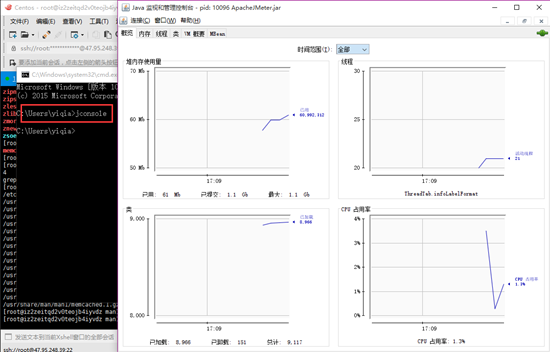
2. JDK自带的测试工具JConsole,位于JDK\bin\JConsole,此工具主要观察堆、JVM、CPU的使用情况
3. 查看yum安装位置
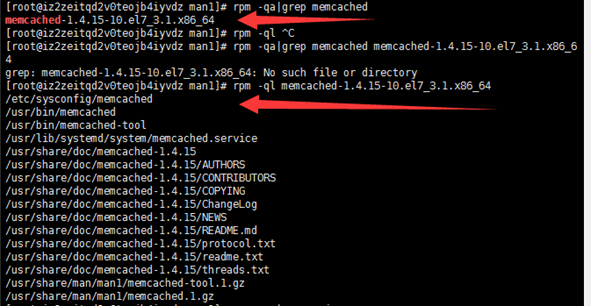
查询一个包是否被安装
# rpm -q < rpm package name>
列出所有被安装的rpm package
# rpm –qa
列出该包中有哪些文件
# rpm -ql < rpm package name>
4. Memcached(http://blog.csdn.net/lulidaitian/article/details/51712893)端口11211
基本介绍:
memcached是一套分布式的快取系统。
memcached缺乏认证以及安全管制,这代表应该将memcached服务器放置在防火墙后。
memcached的API使用三十二位元的循环冗余校验(CRC-32)计算键值后,将资料分散在不同的机器上。当表格满了以后,接下来新增的资料会以LRU机制替换掉。由于memcached通常只是当作快取系统使用,所以使用memcached的应用程式在写回较慢的系统时(像是后端的数据库)需要额外的程式码更新memcached内的资料。
对 memcached 的接口是通过网络连接提供的。这意味着您可以在多个客户机间共享单个的 memcached 服务器(或多个服务器)。这个网络接口非常迅速,并且为了改善性能,服务器会故意不支持身份验证或安全性通信。但这不应限制部署选项。 memcached 服务器应该存在于您网络的内部。网络接口的实用性以及可以部署多个 memcached 实例的简便性让您可以使用多个机器上的多余 RAM 来提高您缓存的整体大小。
使用情况:
Memcached 是“分布式”的内存对象缓存系统,那么就是说,那些不需要“分布”的,不需要共享的,或者干脆规模小到只有一台服务器的应用,memcached不会带来任何好处,相反还会拖慢系统效率,因为网络连接同样需要资源。
Memcached在很多时候都是作为数据库前端cache使用的。因为它比数据库少了很多SQL解析、磁盘操作等开销,而且它是使用内存来管理数据的,所以它可以提供比直接读取数据库更好的性能,在大型系统中,访问同样的数据是很频繁的,memcached可以大大降低数据库压力,使系统执行效率提升。另外,memcached也经常作为服务器之间数据共享的存储媒介,例如在SSO系统中保存系统单点登陆状态的数据就可以保存在memcached中,被多个应用共享。
需要注意的是,memcached使用内存管理数据, 所以它是易失的,当服务器重启,或者memcached进程中止,数据便会丢失,所以memcached不能用来持久保存数据。很多人的错误理解,memcached的性能非常好,好到了内存和硬盘的对比程度,其实memcached使用内存并不会得到成百上千的读写速度提高,它的实际瓶颈在于网络连接,它和使用磁盘的数据库系统相比,好处在于它本身非常“轻”,因为没有过多的开销和直接的读写方式,它可以轻松应付非常大的数据交换量,所以经常会出现两条千兆网络带宽都满负荷了,memcached进程本身并不占用多少CPU资源的情况
memcached 是一个开源项目,旨在利用多个服务器内的多余 RAM 来充当一个可存放经常被访问信息的内存缓存。这里的关键是使用了术语缓存:memcached 为加载自他处的信息提供的是内存中的暂时存储。
存储方法:
memcached 的存储方法是一个简单的键/值对,类似于很多语言内的散列或关联数组。通过提供键和值来将信息存储到 memcached 内,通过按特定的键请求信息来恢复信息。
信息会无限期地保留在缓存内,除非发生如下的情况:
为缓存分配的内存耗尽 — 在这种情况下,memcached 使用 LRU(最近最少使用)方法从此缓存删除条目。最近未曾使用的条目会从此缓存中先删除,最旧的最先访问。
条目被明确删除 — 总是可以从此缓存内删除条目。
条目过期失效 — 各条目均有一个有效的期限以便针对此键存储的信息在过于陈旧时可从缓存中清除这些条目。
使用:
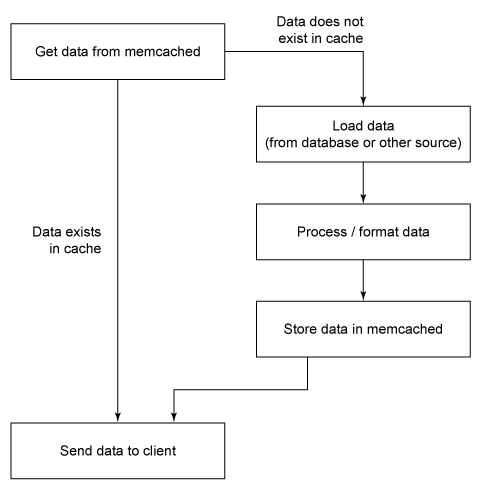
加载适合于显示的信息
更新或存储数据
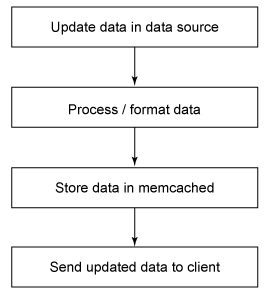
memcached 内的存储操作是原子的,所以信息的更新不会让客户机只获得部分数据;它们获得的或者是老版本,或者是新版本。
对于大多数应用程序,这两个操作是您惟一需要注意的。在访问他人使用的数据时,它会自动被添加到这个缓存内,而且如果对该数据进行了更改,此缓存内也会自动进行更新。
键/值存储:
memcached 键/值存储的简便性(以及安全性的缺乏)意味着如果您想要在使用同一个 memcached 服务器的同时支持多个应用程序,那么就可以考虑使用其他格式的量词来标识数据属于某种特定的应用程序。比如,可以添加像 blogapp:blogpost-29 这样的应用程序前缀。这些键是没有格式的,所以可以使用任何字符串作为键的名称。
在存储值的方面,应该确保存储在缓存内的信息适合于您的应用程序。比如,对于博客系统,您可能想要存储被博客应用程序使用的对象以便格式化博客信息,而不是原始的 HTML。如果同一个基础结构用在应用程序内的多个地方,这一点更具实用性。
大多数语言的接口,包括 Java™、Perl、PHP 等,都能串行化语言对象以便存储在 memcached 内。这就让您可以存储并随后从内存存储恢复全部对象,而不是在您的应用程序内手动重构它们。 很多对象,或它们使用的结构,都基于某种散列或数组结构。对于跨语言的环境,比如在 JSP 环境和 JavaScript 环境间共享相同信息,可以使用一种架构中立的格式,比如 JavaScript Object Notation (JSON) 甚或 XML。
主要的函数有:
get(key) — 从存储了特定键的 memcached 获得信息。 如果键不存在,就返回错误。
set(key, value [, expiry]) — 使用缓存内的标识符键存储这个特定的值。如果键已经存在,那么它就会被更新。期满时间的单位为秒,并且如果值小于 30 天 (30*24*60*60),那么就用作相对时间,如果值大于 30 天,那么就用作绝对时间 (epoch)。
add(key, value [, expiry]) — 如果键不存在就将这个键添加到缓存内,如果键已经存在就返回错误。如果您想要显式地添加一个新键而又不会因它已经存在而更新它,那么这个函数将十分有用。
replace(key, value [, expiry]) — 更新此特定键的值,如果键不存在就返回一个错误。
delete(key [, time]) — 从缓存中删除此键/值对。如果您提供一个时间,那么添加具有此键的一个新值就会被阻塞这个特定的时期。超时让您可以确保此值总是可以重新读取自您的数据中心。
incr(key [, value]) — 为特定的键增 1 或特定的值。只适用于数值。
decr(key [, value]) — 为特定的键减 1 或特定的值,只适用于数值。
flush_all — 让缓存内的所有当前条目无效(或到期失效)。
弹性和可用性
有关 memcached 最常见的一个问题是:“若缓存不可用了,会发生什么情况呢?”正如之前章节中明示的,缓存内的信息不应该成为信息的的惟一资源。必须要能够从其他位置加载存储在缓存内的数据。
虽然,无法从缓存访问信息将会减缓应用程序的性能,但它不应该阻止应用程序的运转。可能会发生这样几个场景:
如果 memcached 服务宕掉,应用程序应该回退到从原始数据源加载信息并对信息进行显示所需的格式化。此应用程序还应继续尝试在 memcached 内加载和存储信息。
一旦 memcached 服务器恢复可用,应用程序就应该自动尝试存储数据。没有必要强制重载已缓存了的数据,可以使用标准的访问来用信息加载和填充缓存。最终,缓存将会被最常用的数据重新填充。
分配缓存:
由于 memcached 通过一个网络接口提供信息,因此单个的客户机可以从它所能访问的任何一个 memcached 实例访问数据。如果数据没有跨每个实例被复制,那么最终在每个应用程序服务器上,就可以有 3 GB 的 RAM 缓存可用
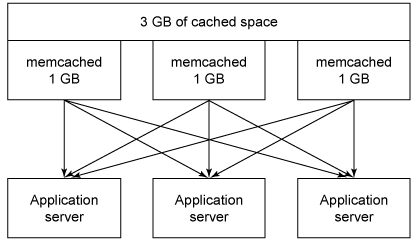
memcached 客户机不必决定此信息,它只需对在存储信息时指定的键使用一个简单的散列算法。当想要从一列 memcached 服务器存储或获取信息时,memcached 客户机就会用一个一致的散列算法从这个键获取一个数值。
如果有两个服务器,那么 memcached 客户机将对这个数值进行一个简单的运算(例如,系数)来决定它应将此值存储在第一个还是第二个配置了的 memcached 实例上。
当存储一个值时,客户机会从这个键确定出散列值以及它原来存储在哪个服务器上。当获取一个值时,客户机会从这个键确定出相同的散列值并会选择相同的服务器来获取信息。
如果在每个应用程序服务器上使用的是相同的服务器列表(并且顺序相同),那么当需要保存或检索同一个键时,每个应用程序服务器都将选择同一个 服务器。
如果在加载和格式化后,使用它来存储全部信息块,就可以从 memcached 获得更多的实用工具和性能上的改善。以博客站点为例,存储信息的最佳点是在将博客类别格式化为对象,甚至是在格式化成 HTML 后。博客页面的构造可通过从 memcached 加载各个组件(比如 blog post、category list、post history 等)并将完成的 HTML 写回至客户机实现。
安全性:
memcached并不安全
为了确保最佳性能,memcached 并未提供任何形式的安全性,没有身份验证,也没有加密。这意味着对 memcached 服务器的访问应该这么处理:一是通过将它们放到应用程序部署环境相同的私有侧,二是如果安全性是必须的,那么就使用 UNIX® socket 并只允许当前主机上的应用程序访问此 memcached 服务器。
这多少牺牲了一些灵活性和弹性,以及跨网络上的多台机器共享 RAM 缓存的能力,但这是在目前的情况下确保 memcached 数据安全性的惟一一种解决方案。
扩展:
由于 memcached 与应用程序处于相同的架构水平,所以很容易集成并连接到它。并且更改应用程序以便利用 memcached 也并不复杂。此外,由于 memcached 只是一个缓存,所以在出现问题时它不会停止应用程序的执行。如果使用正确的话,它所做的是减轻其余服务器基础设施的负载(减少对数据库和数据源的读操 作),这意味着无需更多的硬件就可以支持更多的客户机。
5. Memcached客户端--------xmemcached
<dependency>
<groupId>com.googlecode.xmemcached</groupId>
<artifactId>xmemcached</artifactId>
<version>2.4.2</version>
</dependency>
在本地安装Mencached,测试
public class App {
public static void main(String[] args) throws IOException, InterruptedException, MemcachedException, TimeoutException {
MemcachedClientBuilder builder = new XMemcachedClientBuilder(AddrUtil.getAddresses("localhost:11211"));
MemcachedClient memcachedClient = builder.build();
memcachedClient.set("hello", 0 , "Hello, xmemcached");
String value = memcachedClient.get("hello");
System.out.println("hello=" + value);
memcachedClient.delete("hello");
value = memcachedClient.get("hello");
System.out.println("hello=" + value);
//close memcached client
memcachedClient.shutdown();
}
}

明日计划:
1. 重构任务5,尝试共同实现用户注册和登陆
2. 加上Memcache,在新建数据的时候同时维护好缓存(没有新建数据接口就自己加上,可以分成是压测JSP和Json接口两种方式) ,确定数据没问题,重新压测服务器,测出90%的线在哪里.
3. 停止Memcache进程,观察压测数据。部署两台WEB,使用Nginx的Upstream来做负载。重新压测。
遇到的问题:
1. 暂无
收获:
1. 初步学会JMeter进行压力测试和性能测试,还需要对数据和指标加以理解
2. 在服务器和本地安装memcached,memcached服务端和客户端,服务端在服务器上开辟内存空间进行缓存,客户端选择需要缓存的数据并在存储信息时指定键使用一个简单的散列算法,记录分布式缓存的位置,以此来达到多台服务器分布式缓存的功能。




评论