发表于: 2018-03-09 23:18:20
0 560
今日完成:
1. chain.doFilter(request,response)
他的作用是将请求转发给过滤器链上下一个对象。这里的下一个指的是下一个filter,如果没有filter那就是你请求的资源。 一般filter都是一个链,web.xml 里面配置了几个就有几个。一个一个的连在一起
request -> filter1 -> filter2 ->filter3 -> .... -> request resource.
2. MVC(http://www.digpage.com/mvc.html)

Model是指数据模型,是对客观事物的抽象:数据、业务逻辑和业务规则
Model的几个原则:
数据、行为、方法是Model的主要内容;
实际工作中,Model是MVC中代码量最大,逻辑最复杂的地方,因为关于应用的大量的业务逻辑也要在这里面表示。
Model所提供的数据都是原始数据。也就是说,不带有任何表现层的代码。 比如,一般不会在输出的数据中添加HTML标签,这是View的工作。 但是Model可以提供有结构的数据,数组结构、队列结构、乃至其他Model等。 这个结构并非是表现层的格式,而是数据在内存中的表现。
与输出不同,Model的输入数据,可以是带有表现格式的数据。 如将一篇文章保存到Post里面,内容中必然包含各种HTML标签。 因此,Model一般要对输入数据作过滤、验证和规范化等预处理。 特别是对于需要保存进数据库的,一定要对所有的输入数据作预处理。 这些预处理,有的其实是业务逻辑。比如只有主编才可以删除文章,这一验证规则既也是业务逻辑,也是权限控制。 而有些预处理,则不属于业务逻辑,比如,文章标题前后的空格应去除。
注意与Controller区分开。Model是处理业务方面的逻辑,Controller只是简单的协调Model和View之间的关系, 只要是与业务有关的,就该放在Model里面。好的设计,应当是胖Model,瘦Controller。
View是指视图,也就是呈现给用户的一个界面,是model的具体表现形式,也是收集用户输入的地方。
View的几个原则:
负责显示界面,以HTML为主;
一般没有复杂的判断语句或运算过程,可以有简单的循环语句、格式化语句。 比如,一般博客首页的文章列表,就是一种循环结构;
从不调用Model的写方法。也就是说,View只从Model获取数据,而不直接改写Model,所以我们说他们老死不相往来。
一般没有任何准备数据的代码,如查询数据库、组合成一定格式的字符串等。 这些一般放在Controller里面,并以变量的形式传给视图。 也就是说,视图里面要用到的数据,都是拿来就能直接用的变量。
Contorller指的是控制器,主要负责与model和view打交道。Contorller用于决定使用哪些Model,对Model执行什么操作,为视图准备哪些数据,是MVC中沟通的桥梁。
Controller的设计原则:
用于处理用户请求。 因此,对于reqeust的访问代码应该放在Controller里面,比如 $_GET $_POST 等。 但仅限于获取用户请求数据,不应该对数据有任何操作或预处理,这些工作应该交由Models来完成。
调用Models的读方法,获取数据,直接传递给视图,供显示。 当涉及到多个Model时,有关的逻辑应当交给Model来完成。
调用Models的类方法,对Models进行写操作。
调用视图渲染函数等,形成对用户Reqeust的Response。
3. MVC与前后端的配合
对于MVC中三者的划分并没有十分明晰的定义和界线。MVC设计模式只是一种指导思想, 让你按照model, view, controller三个方面来描述你的应用,并通过三者的交互,使应用功能得以正常运转。
Web浏览器的功能日臻强大。因此,Web应用开发出现了一个新的发展苗头,就是功能从后端往前端转移。
在前端,通过JavaScript捕获用户操作,进行相应处理。 或是发送回后端获取响应后处理,如通过ajax请求后端数据,实现无刷新的局部页面更新,向用户进行反馈; 或直接在前端由浏览器进行处理,如使用backbone.js、Angular.js等前端框架的数据绑定功能等。 这些都使得Web应用表现得越来越像桌面应用。
后端MVC也在为前后端的发展而改变。 Controller的功能更多的变成了识别是ajax请求还是普通请求, 并根据请求的不同采取相应的视图渲染方式。对于普通请求,正常渲染视图,输出HTML。 对于ajax请求,则返回局部渲染视图,输出HTML片段。有的甚至输出XML或者JSON。 唯一在大潮流中,巍然不动的,还是我们的Model。
4. Spring AOP
OOP允许开发者定义纵向的关系,但并不适合定义横向的关系,例如日志功能。日志代码往往横向地散布在所有对象层次中,而与它对应的对象的核心功能毫无关系对于其他类型的代码,如安全性、异常处理和透明的持续性也都是如此,这种散布在各处的无关的代码被称为横切(cross cutting),在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。
AOP技术恰恰相反,它利用一种称为"横切"的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其命名为"Aspect",即切面。所谓"切面",简单说就是那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块之间的耦合度,并有利于未来的可操作性和可维护性。
使用"横切"技术,AOP把软件系统分为两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关注点,与之关系不大的部分是横切关注点。横切关注点的一个特点是,他们经常发生在核心关注点的多处,而各处基本相似,比如权限认证、日志、事物。AOP的作用在于分离系统中的各种关注点,将核心关注点和横切关注点分离开来。
连接点(joinpoint):
被拦截到的点,因为Spring只支持方法类型的连接点,所以在Spring中连接点指的就是被拦截到的方法,实际上连接点还可以是字段或者构造器
通知(advice):
所谓通知指的就是指拦截到连接点之后要执行的代码,通知分为前置、后置、异常、最终、环绕通知五类
执行顺序:
(1)aspect里面有一个order属性,order属性的数字就是横切关注点的顺序
(2)Spring默认以aspect的定义顺序作为织入顺序
1) XML配置
<bean id="helloWorldImpl1" class="com.xrq.aop.HelloWorldImpl1" />
<bean id="helloWorldImpl2" class="com.xrq.aop.HelloWorldImpl2" />
<bean id="timeHandler" class="com.xrq.aop.TimeHandler" />
<aop:config>
<aop:aspect id="time" ref="timeHandler">
<aop:pointcut id="addAllMethod" expression="execution(* com.xrq.aop.HelloWorld.*(..))" />
<aop:before method="printTime" pointcut-ref="addAllMethod" />
<aop:after method="printTime" pointcut-ref="addAllMethod" />
</aop:aspect>
</aop:config>
ps:强制使用CGLIB生成代理,那就是<aop:config>里面有一个"proxy-target-class"属性,这个属性值如果被设置为true,那么基于类的代理将起作用,如果proxy-target-class被设置为false或者这个属性被省略,那么基于接口的代理将起作用。
2) 注解配置
<!-- 启用 @Aspect -->
<aop:aspectj-autoproxy proxy-target-class="true"/>
@Aspect
@Component
public class LoggerAspect {
//java自带的log日志
private final Logger logger = Logger.getLogger("DB_Controller");
@Pointcut("execution(* com.myitschool.controller.*.*(..))")
private void controller(){}
@Around("controller()")
public Object controllerTime(ProceedingJoinPoint pjp) throws Throwable {
String className = pjp.getSignature().getName();
long startT = System.currentTimeMillis();
Object re = pjp.proceed();
long time = System.currentTimeMillis() - startT;
logger.info(logger.getName() + " " + className + " " + time);
System.out.println(logger.getName() + " " + className + " " + time);
return re; //有返回值必须
}
5. CGLIB-----还不理解
CGLIB是一个强大的、高性能的代码生成库。其被广泛应用于AOP框架(Spring、dynaop)中,用以提供方法拦截操作。
CGLIB代理主要通过对字节码的操作,为对象引入间接级别,以控制对象的访问。我们知道Java中有一个动态代理也是做这个事情的,那我们为什么不直接使用Java动态代理,而要使用CGLIB呢?答案是CGLIB相比于JDK动态代理更加强大,JDK动态代理虽然简单易用,但是其有一个致命缺陷是,只能对接口进行代理。如果要代理的类为一个普通类、没有接口,那么Java动态代理就没法使用了。
6. DES
DES有很多种加密模式,其中的密钥向量可以通过选择不同模式来选择是否自定义。
可以通过密钥生成,也可以自定义IvParameterSpec iv = new IvParameterSpec(key);
DES加密和解密过程中,密钥长度都必须是8的倍数。
之前DES加密解密结果不一致的问题,问题出现在编码格式的问题
[109, 107, 110, 118, 110, 106, 117, 102, 97, 106, 106, 100, 102, 107]
[B@6f2b958e
[109, 107, 110, 118, 110, 106, 117, 102, 97, 106, 106, 100, 102, 107]
[B@3a82f6ef
通过Arrays.toString()输出可以发现结果是一样的,但是不转换的结果是不一样的
需要将byte[]通过new String()转为string类型,则结果一致
7. 查看压测的相关知识
压力测试是为了发现系统能支持的最大负载,他的前提是要求系统性能处在可以接受的范围内,比如经常规定的页面3秒钟内响应; 在性能可以接受的前提下,测试系统可以支持的最大负载。
性能测试是为了检查系统的反映,运行速度等性能指标,他的前提是要求在一定负载下,如检查一个网站在100人同时在线的情况下的性能指标,每个用户是否都还可以正常的完成操作等。在不同负载下(负载一定)时,通过一些系统参数(如反应时间等)检查系统的运行情况;
综合性能=压力数*性能指数,
综合性能是固定的:
压力测试是为了得到性能指数最小时候(可以接受的最小指数)最大的压力数 。
性能测试是为了得到压力数确定下的性能指数。
8. 下载JMeter,压测自己的JSP,查看TPS数据,调整并发数,压到程序挂掉为止。
TPS (transaction per second)代表每秒执行的事务数量,可基于测试周期内完成的事务数量计算得出。例如,用户每分钟执行6个事务,TPS为6 / 60s = 0.10 TPS。
JMeter
请求消息中文显示乱码

响应消息中文显示乱码

被测试系统收到中文乱码
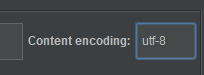
数据很糟糕
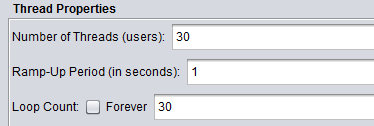

明日计划:
1. JMeter压力测试分析,优化项目,必要情况下重构
2. tps
3. 学习缓存
遇到的问题:
1. DES加密中使用的
// DES算法要求有一个可信任的随机数源
SecureRandom sr = new SecureRandom();
Cipher cipher = Cipher.getInstance("DES");
cipher.init(Cipher.DECRYPT_MODE, key, sr);
这个随机数有什么作用,为什么加密解密的随机数可以不一样???
收获:
1. MVC分层学习,DES加密算法熟悉,
2. JMeter压力测试入门




评论