发表于: 2018-03-05 22:17:03
1 648
今天做了什么:
根据师兄的建议,看了domain model
领域模型:领域内的概念类或现实世界中对象的可视化表示,又称为概念模型或分析对象模型。它专注于分析问题领域本身,发掘重要的业务领域概念,并建立业务领域概念之间的关系。
贫血模型:是指使用的领域对象中只有setter和getter方法(POJO),所有的业务逻辑都不包含在领域对象中而是放在业务逻辑层。有人将 贫血模型进一步划分成失血模型(领域对象完全没有业务逻辑)和贫血模型(领域对象有少量的业务逻辑)。
充血模型:将大多数业务逻辑和持久化放在领域对象中,业务逻辑(业务门面)只是完成对业务逻辑的封装、事务和权限等的处理。下面两张图分别展示了贫血模型和充血模型的分层架构。
贫血模型:

充血模型

1、每个贫血对象职责单一,所以模块解藕程度很高,有利于错误的隔离。2、非常重要的是,这种模型非常适合于软件外包和大规模软件团队的协作。每个编程个体只需要负责单一职责的小对象模块编写,不会互相影响。
1、由于对象状态和行为分离,所以一个完整的业务逻辑的描述不能够在一个类当中完成,而是一组互相协作的类共同完成的。因此可复用的颗粒度比较 小,代码量膨胀的很厉害,最重要的是业务逻辑的描述能力比较差,一个稍微复杂的业务逻辑,就需要太多类和太多代码去表达(针对我们假定的这个简单的工时管 理系统的业务逻辑实现,ruby使用了50行代码,但Java至少要上千行代码)。2、对象协作依赖于外部容器的组装,因此裸写代码是不可能的了,必须借助于外部的IoC容器。
1、对象自洽程度很高,表达能力很强,因此非常适合于复杂的企业业务逻辑的实现,以及可复用程度比较高。2、不必依赖外部容器的组装,所以RoR没有IoC的概念。
1、对象高度自洽的结果是不利于大规模团队分工协作。一个编程个体至少要完成一个完整业务逻辑的功能。对于单个完整业务逻辑,无法再细分下去了。2、随着业务逻辑的变动,领域模型可能会处于比较频繁的变动状态中,领域模型不够稳定也会带来web层代码频繁变动。
个人理解:
贫血模型:适合频繁需求变更和共同开发项目,耦合度低
充血模型:适合需求相对稳定,业务体系不冗杂,开发人员相对可靠的情况
学习了动态sql,修改了mapper.xml的部分代码。
if、choose、trim、foreach。
其中在使用where后加2个及以上的if时,若第一个不匹配而第二个匹配会出现最后的sql语句出现
select some_column from table where
and some_value
报错,这时候用trim自定义where可以避免。
不过trim的用法还没深入研究。
public Long insertStudents(Students students) throws Exception {
SqlSession sqlSession = sqlSessionFactory.openSession();
//创建StudentsMapper对象,mybatis自动生成mapper代理对象
try {
StudentsMapper studentsMapper = sqlSession.getMapper(StudentsMapper.class);
students.setCreate_at(System.currentTimeMillis());
studentsMapper.insertStudents(students);
sqlSession.commit();
}catch (Exception e) {
sqlSession.rollback();
throw new RuntimeException(e);
}
finally {
sqlSession.close();
}
在service层增加了create_at的属性,在db中显示的是毫秒,明天打算写个工具类实现像20180305215432这种格式的转换。
在main方法中写了10k和100k次的insert,时间如下
100k:
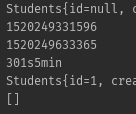
10k: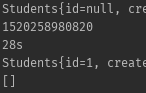
明天打算做什么:
完成时间转换工具类或找到代替方法
完善项目,准备开始spring-mybatis的新项目
问题:
mybatis的trim标签用法
收获:关于领域模型架构的一点点了解,




评论