发表于: 2018-02-24 17:47:19
2 780
一、今天完成的事情:
将表数据导出到文件:
- Navicat
- 选中要导出的表,点击导出,选择全部记录.
- 勾选包含列的标题,将字段名导出,不然导入时需要手动勾选对应字段,最后完成即可.
mysql
SELECT * FROM students INTO OUTFILE 'C:\\TEST.TEXT';报错:

百度搜索了一下,说是mysql权限的问题,可以使用
show variables like '%secure%';查看当前secure-file-priv的值.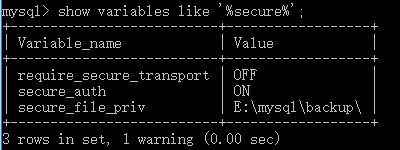
导出的数据必须是这个值的指定路径才可以导出,默认有可能是NULL就代表禁止导出,需要修改一下mysql配置文件
my.ini,添加:secure-file-priv="E:/mysql/backup"
注意 windows下配置文件中需要使用反斜杠重启mysql使配置生效,以管理员方式启动命令提示符:
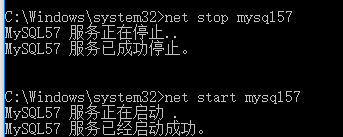
查看配置
尝试导出到文件:
无格式导出
mysql> select * from students into outfile 'E://mysql//backup//students.txt';

- students.txt

1 张三 1753218 20180123 20180123 1 1 学无止境 dd http://www.baidu.com 知乎
2 李四 1753558 20180123 20180123 2 1 努力奋斗 五五开 https://xiaoweba.ml 微博
通过命令选项来设置数据输出的指定格式,以下实例为导出 CSV 格式:

select * from students into outfile 'E://mysql//backup//students_cvs.txt'
FIELDS TERMINATED BY ',' ENCLOSED BY '"'
LINES TERMINATED BY '\r\n';- students_cvs.txt

"1","张三","1753218","20180123","20180123","1","1","学无止境","dd","http://www.baidu.com","知乎"
"2","李四","1753558","20180123","20180123","2","1","努力奋斗","五五开","https://xiaoweba.ml","微博"
- students_cvs.txt
- Navicat
将数据文件恢复到数据库中:
- Navicat
- 选中要恢复的表,点击导入,根据你导出的文件类型选择.
- 到
你可以为你的源定义一些附加的选项。时,可以选择要导入的数据范围. 自定义导入字段,我这里每次导入都必须手动设置数据相对应字段,不知道是否是导出时有问题.- 导入模式选择
Append即可.
- mysql
- 删除原记录:
mysql> delete from students; - 从文件恢复刚刚备份的数据:
- 无格式:
LOAD DATA LOCAL INFILE 'E://mysql/backup/students.txt' INTO TABLE students; - 指定格式:
LOAD DATA LOCAL INFILE 'E://mysql/backup/students.txt' INTO TABLE students
FIELDS TERMINATED BY ',' ENCLOSED BY '"'
LINES TERMINATED BY '\r\n';
- 无格式:
- 删除原记录:
- Navicat
索引:
- 索引的优点
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
- 可以大大加快 数据的检索速度,这也是创建索引的最主要的原因。
- 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
- 索引的缺点
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
- 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间。如果要建立聚簇索引,那么需要的空间就会更大。
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
- 索引是建立在数据库表中的某些列的上面。因此,在创建索引的时候,应该仔细考虑在哪些列上可以创建索引,在哪些列上不能创建索引, 一般来说,应该在这些列上创建索引,例如:
- 在经常需要搜索的列上,可以加快搜索的速度;
- 在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
- 在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
- 在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
- 在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
- 在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
- 建立索引,一般按照select的where条件来建立,比如: select的条件是where f1 and f2,那么如果我们在字段f1或字段f2上简历索引是没有用的,只有在字段f1和f2上同时建立索引才有用等。
- 什么样的字段不适合创建索引:
- 对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
- 对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比 例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
- 对于那些定义为text,image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
- 当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
- 为姓名创建索引:
- 添加索引后测试查询速度并无太大提升,应该是数据量太小了.
- 直接添加索引:
create index students_name ON students(s_name(20)); - 修改表结构添加索引:
alter table students add index students_name(s_name); - 创建表的时候直接指定:
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
- 删除索引:
drop index students_name on students;
- 查看表的所有索引:
show index from students;
- 索引的优点
安装配置JDK:
- 官网下载安装,系统环境变量中:
- 添加变量,名为:
JAVA_HOME,值为jdk目录:D:\java\jdk1.8.0_161\; - 在
Path变量中添加:%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;; - 添加变量,名为:
Classpath,值为:.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;
- 添加变量,名为:
- 命令提示符中测试
- 测试
java -version,javac无问题.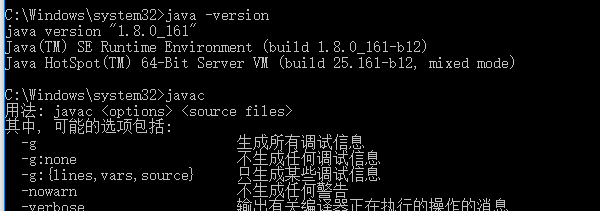
- 测试
- 官网下载安装,系统环境变量中:
安装配置Maven3:
- 设置环境变量:
- 变量名:
MAVEN_HOME,值:D:\apache-maven-3.5.2; Path中添加:%MAVEN_HOME%\bin;
- 变量名:
- 设置本地仓库位置:
- 修改
D:\apache-maven-3.5.2\conf目录下的settings.xml文件,将其中的localRepository修改为你本地的仓库位置:<localRepository>E://maven//LocalWarehouse</localRepository>,默认是被注释掉的.
- 修改
- 重开命令提示符中,测试
mvn -v:
- 设置环境变量:
- IDEA:
- 2017.3.4无法破解了,下来2017.3.3顶着.
- 去http://idea.lanyus.com/获取注册码激活,在线无法激活.
- 无法激活的下载JetbrainsCrack-2.6.10-release-enc.jar放到程序bin目录下,并在此目录下的
idea.exe.vmoptions和idea64.exe.vmoptions文件末尾添加-javaagent:D:\JetBrains\IntelliJ IDEA 2017.3\bin\JetbrainsCrack-2.6.10-release-enc.jar,再使用激活码注册.
- 配置Maven3
- 打开-File-Settings
- 打开-File-Settings
- 新建maven WEB项目
- 打开-File-New-Project,点击NEXT
NEXT
添加的配置为 archetypeCatalog=internal
NEXT
NEXT
点击Finish后项目开始创建,点击右下角查看进度, - 看样子是在下载相关文件,我这里下了好久
- 打开-File-New-Project,点击NEXT
- maven web模板项目结构
同样在main下新建test测试文件夹,再在此文件夹下新建java测试源码文件夹和resource测试资源文件夹
也可以右键项目-选择Open Module Settings打开项目配置页面更改 - 配置依赖jar包
- jar包配置搜索官方地址:http://mvnrepository.com/
- 2017.3.4无法破解了,下来2017.3.3顶着.












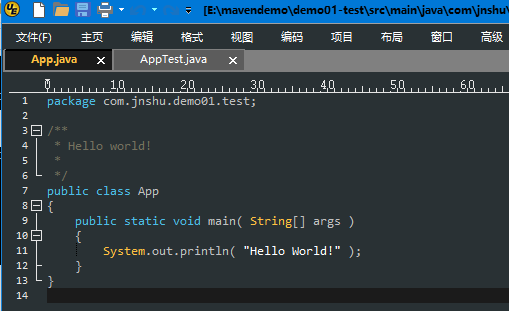
- 编写helloworld文件:
- main目录下:
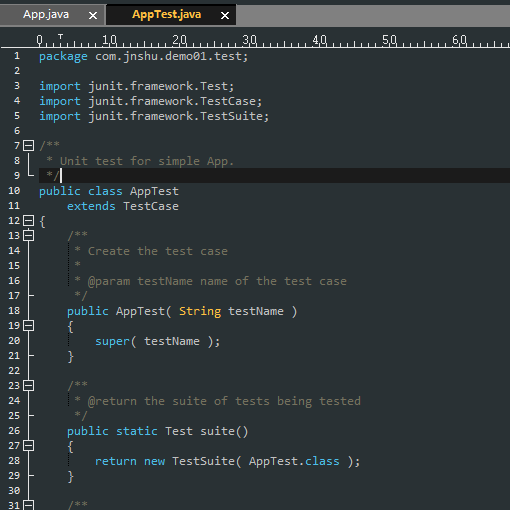
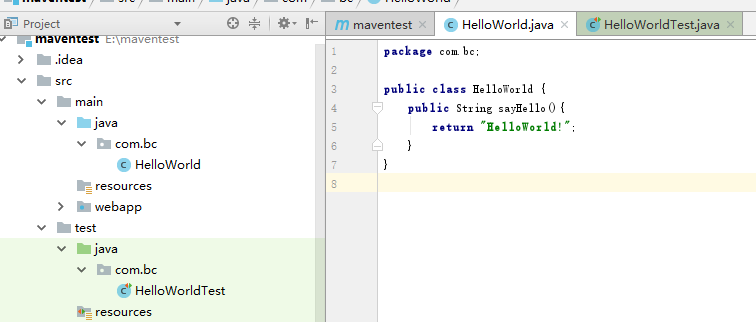 test目录下:
test目录下: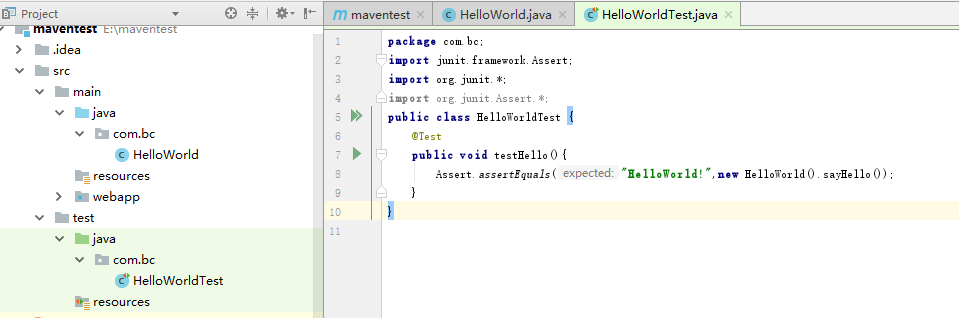
- 报错提示junit类不存在:
因为我使用了junit 4.0中的类,默认的是3.8的,修改pom.xml文件后保存会自动下载相应包.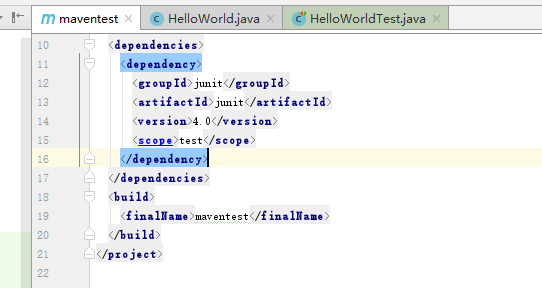
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.0</version>
<scope>test</scope>
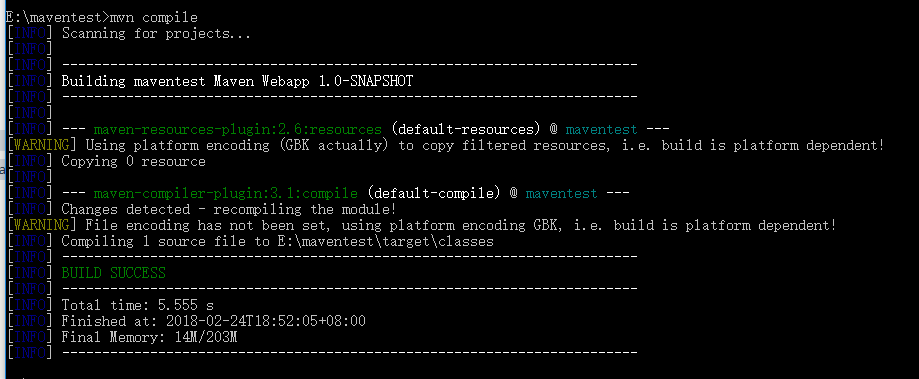
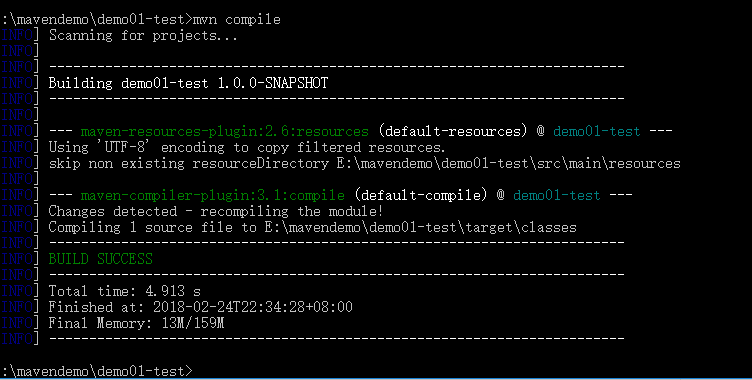
</dependency>- 编译 mvn compile
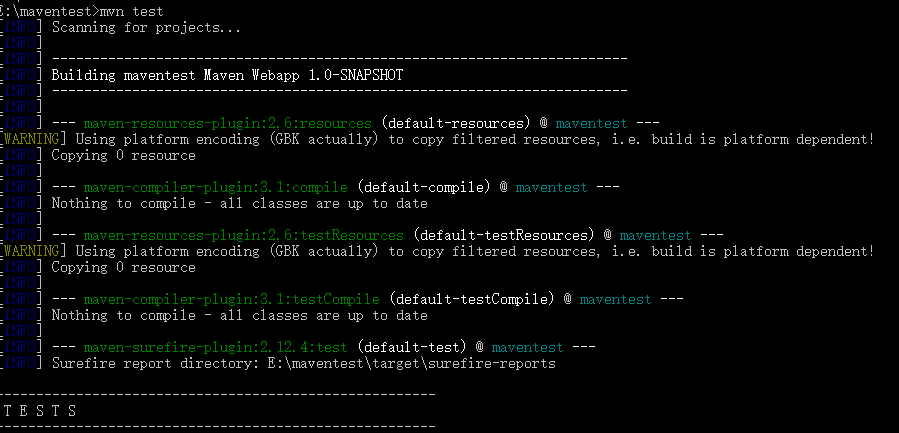
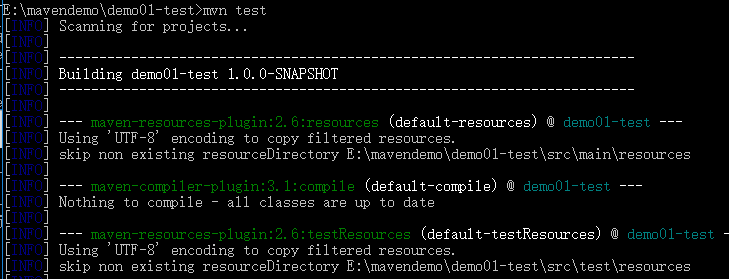
- 测试 mvn test
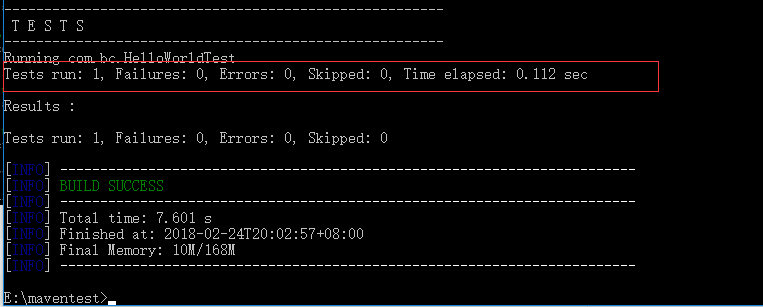
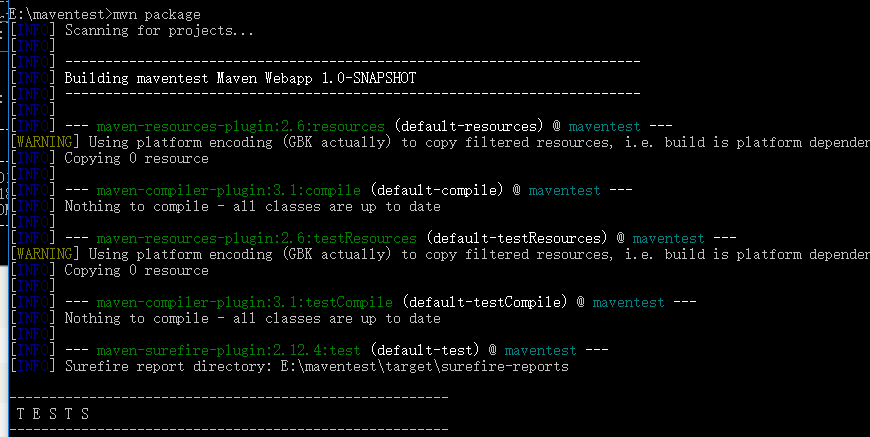
- 打包 mvn package,创建的是web项目,所以打包的是war文件.
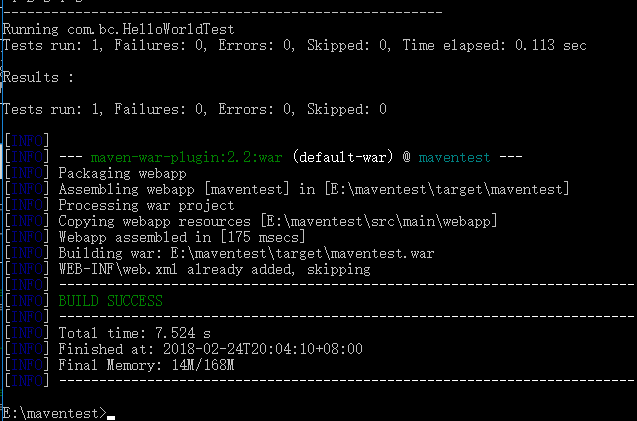
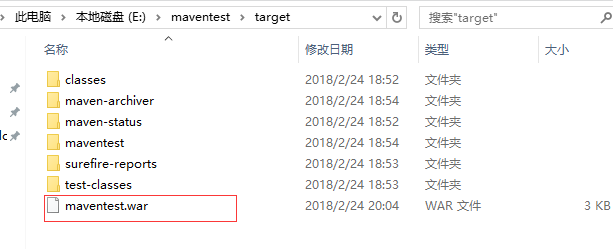
- 命令行构建maven项目
- 按步骤 mvn archetype:generate
- 直接填写参数 mvn archetype:generate -DgroupId=com.jnshu.demo02 -DartifactId=demo02-test -Dversion=1.0.0SNAPSHOT -Dpackage=com.jnshu.demo02.test
- mvn archetype:generate -X 为Debug模式,卡在Generating project in Interactive mode应该是网络问题,可将官方远程库修改为阿里云的镜像库.
- 修改${maven.home}/conf或者${user.home}/.m2文件夹下的settings.xml文件,在<mirrors>标签下加入下述内容即可。如下:
<mirror>
<id>alimaven</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/repositories/central/</url>
</mirror>
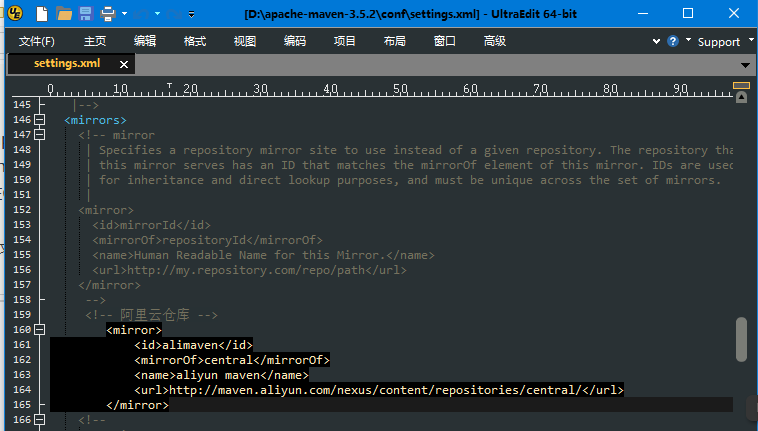
修改完毕后执行mvn archetype:generate
在回车后,项目将开始创建。从Archetype创建一个项目将执行下面3个步骤:
1)archetype的选择;
2)archetype的配置;
3)用户输入项目信息,并根据项目信息创建工程。
我们可以在命令行中看到下面的信息:

在这里,你需要做出一个选择,选择一种archetype,archetype就是一个模板,Maven将根据模板创建和模板匹配的项目,完整的archetype的信息你可以在http://repo1.maven.org/maven2/archetype-catalog.xml查看,目前有7000多种archetype,默认回车即可:

继续默认回车:

这里,你需要输入groupid,组织名,一般格式: 公司网址的反写.项目名称,输入groupid后回车:
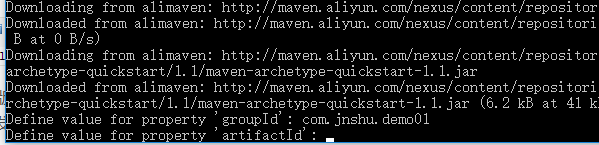
artifactId,一般格式:项目名称-模块名

version版本号,一般格式为:版本号-SNAPSHOT

package代码所存在的包名,一般格式为:公司网址的反写.项目名称.模块名

输入Y即可开始构建项目
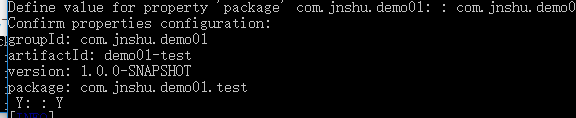
查看项目目录文件都已自动构建完毕.
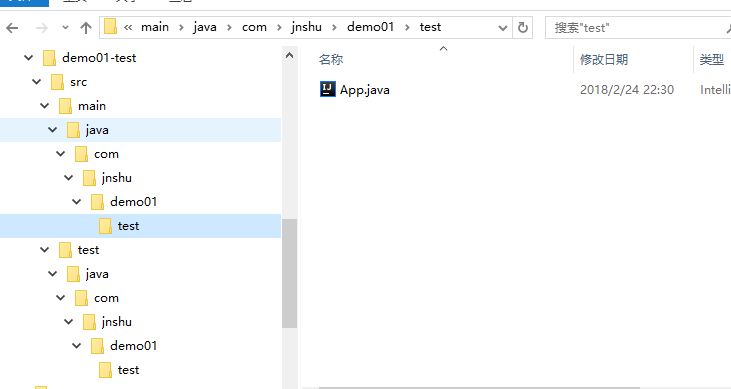
默认模板
mvn complie 编译成功
mvn test 测试正常
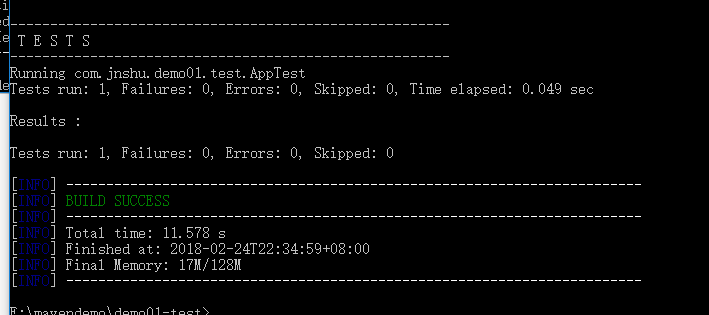
package 打包

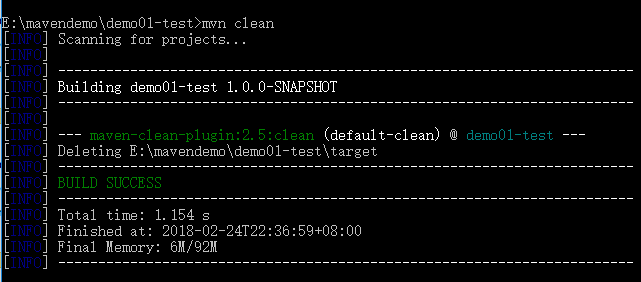
mvn clean
mvn install
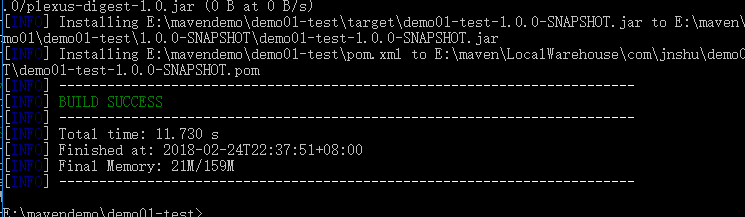
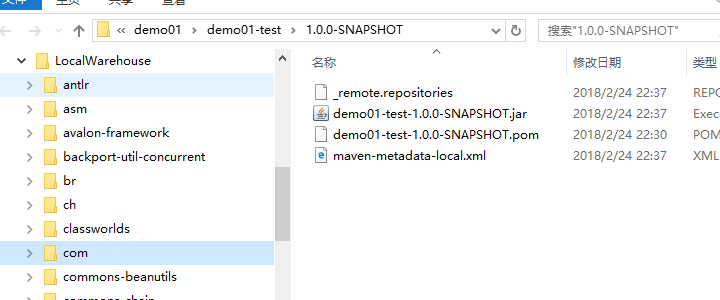
已添加到本地仓库
二、明天计划的事:
继续深入了解maven的工作流程,编写DAO,多接触Junit.
继续任务一.
三、遇到的问题:
今天全都是之前没碰过的新东西,maven项目创建就弄了半天,应该先手动创建目录,再在IDEA里做的,还需要继续理解这个项目管理工具,感觉都是不会的东西了.
ps: 之前看到有师兄把日报写出了md格式,今天试了一下转换成html日报编辑器一句都没有识别出来......
现在这个是直接复制过来的.感觉怪怪的,列表都无法显示,浪费了不少精力,明天直接写好了.
四、收获:
maven和Junit都碰到了边边,明天继续这两个.




评论