发表于: 2018-01-29 23:59:40
1 690
今天完成的事情:
学习了索引btree,尝试向数据库里面添加千万条,亿条记录。并且分别在有索引
和没有索引情况下插入
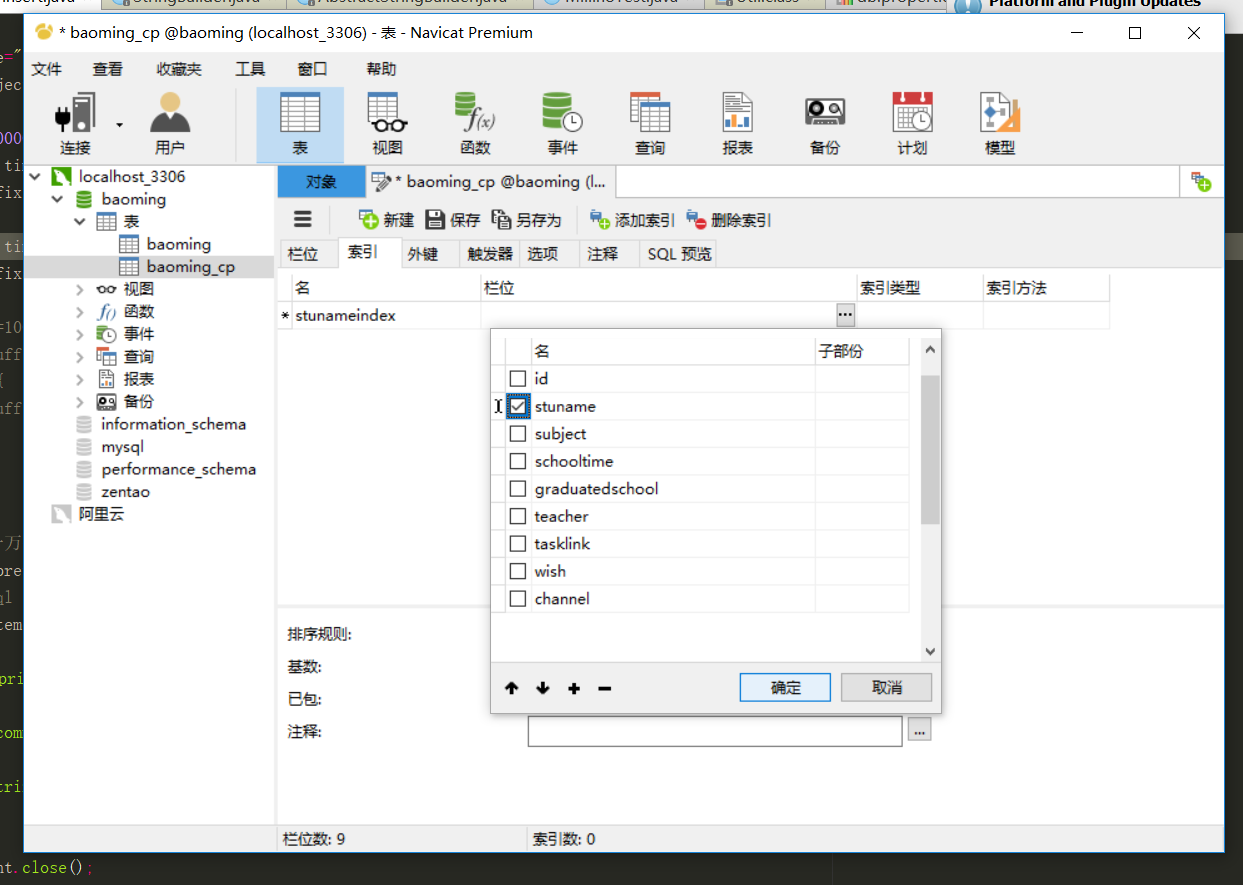
首先是创建一个有btree索引的表。
然后是查百万无索引表结果:
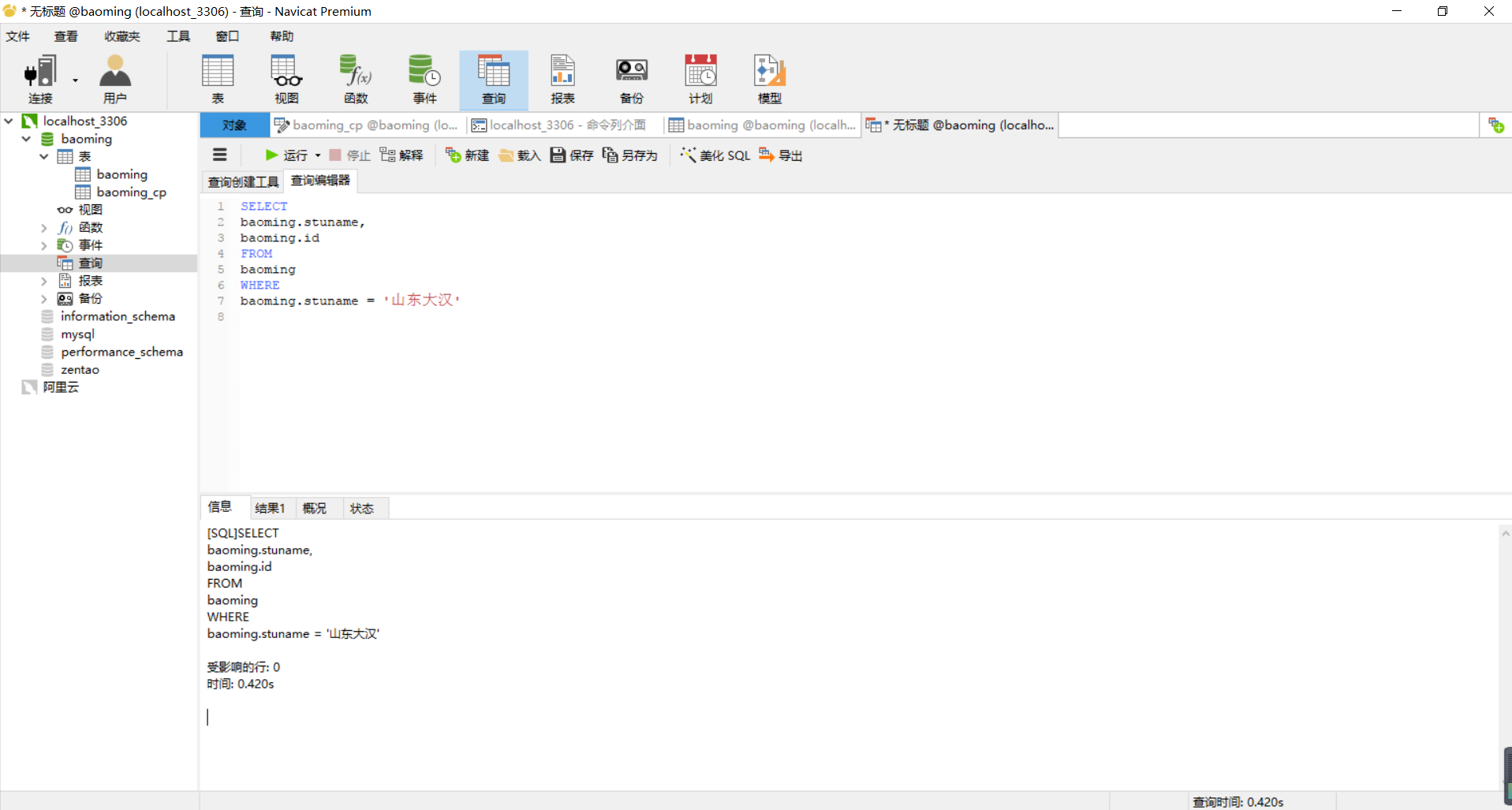
之后是查有索引百万数据表结果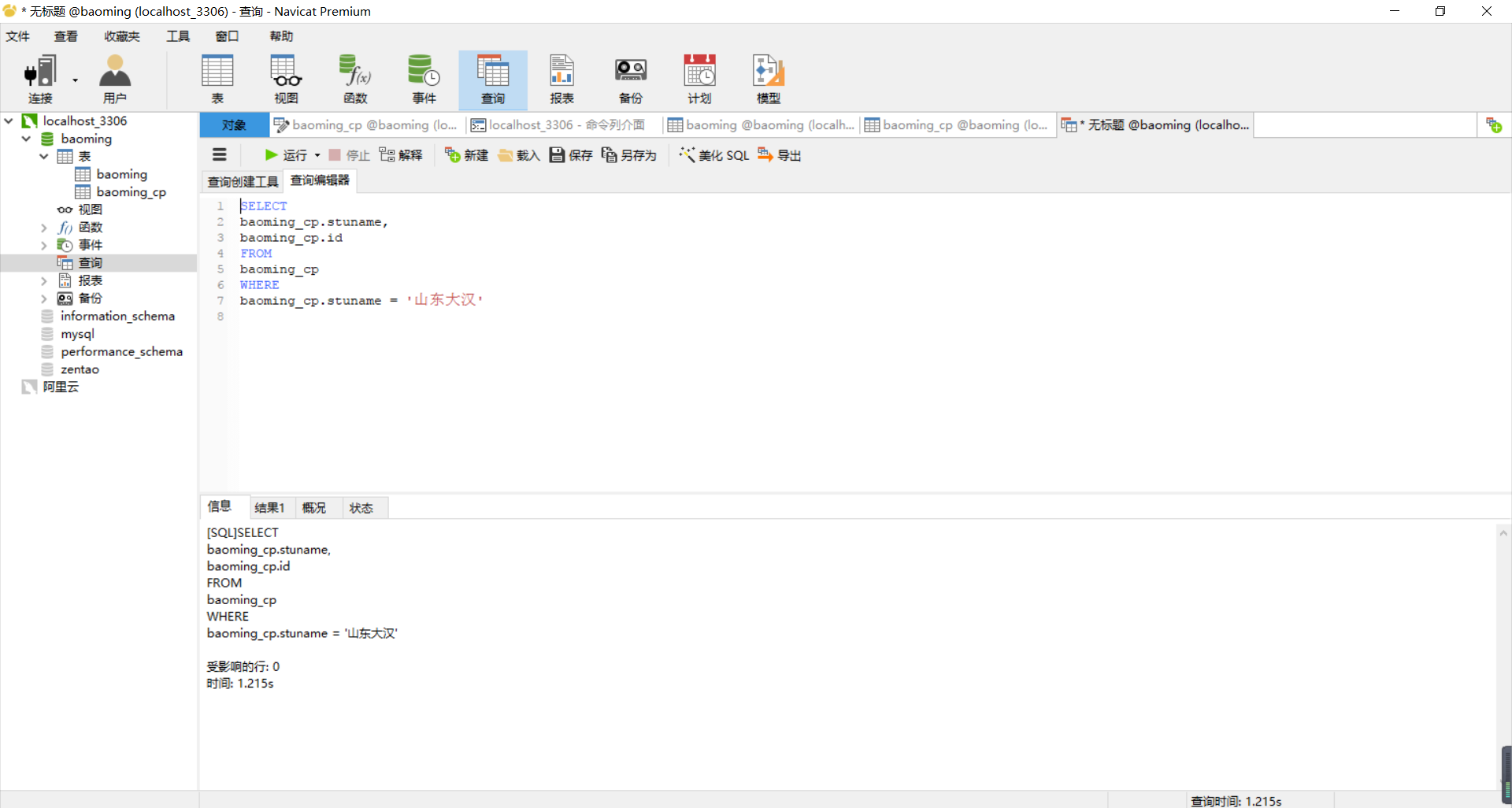
可一见到反而变慢了可能跟设置btree的是stuname有关,
MySQL对中文索引支持的没那么好。
到了千万级
没索引插入时候很快,
有索引插入是10倍的时间: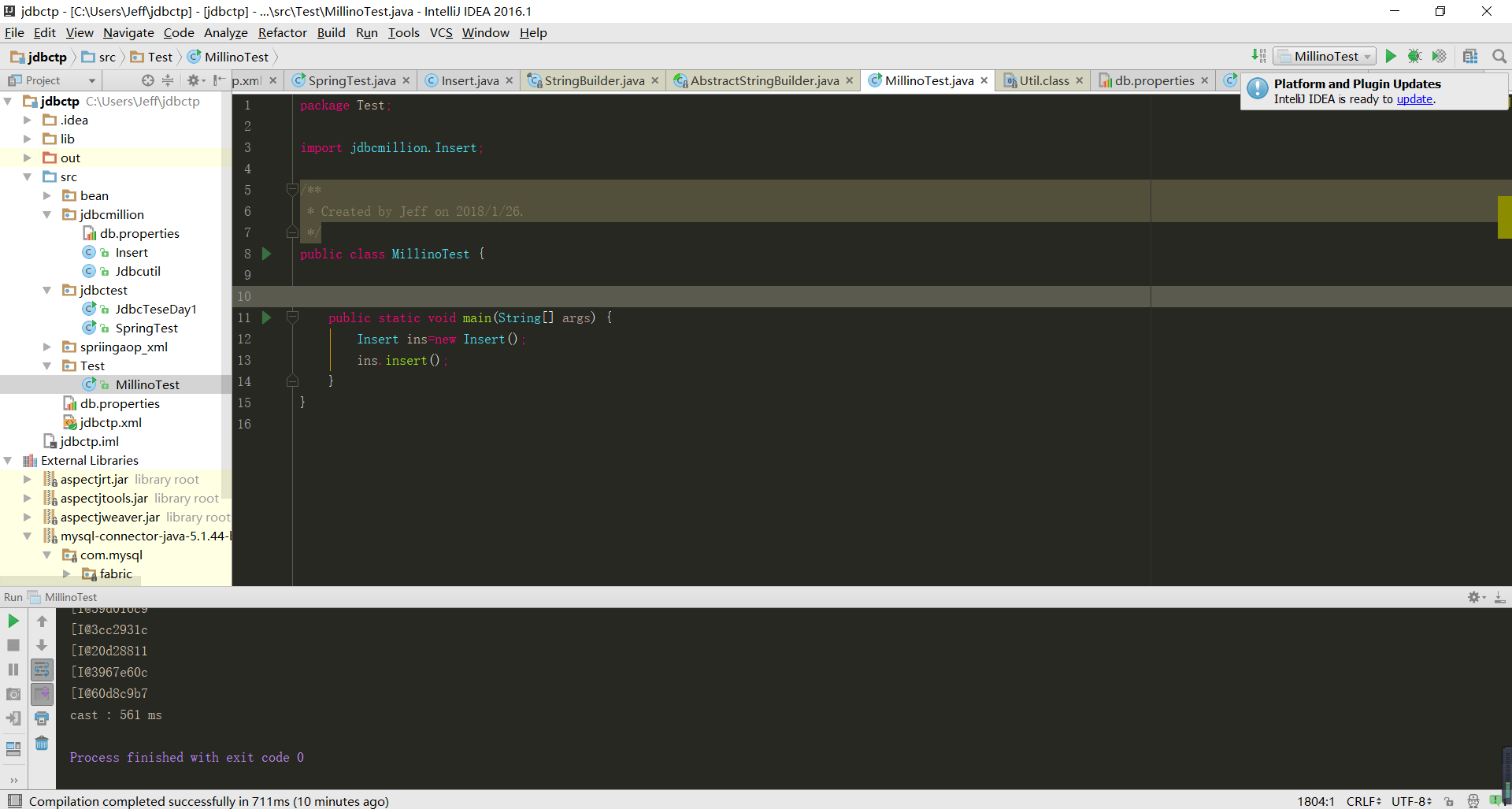
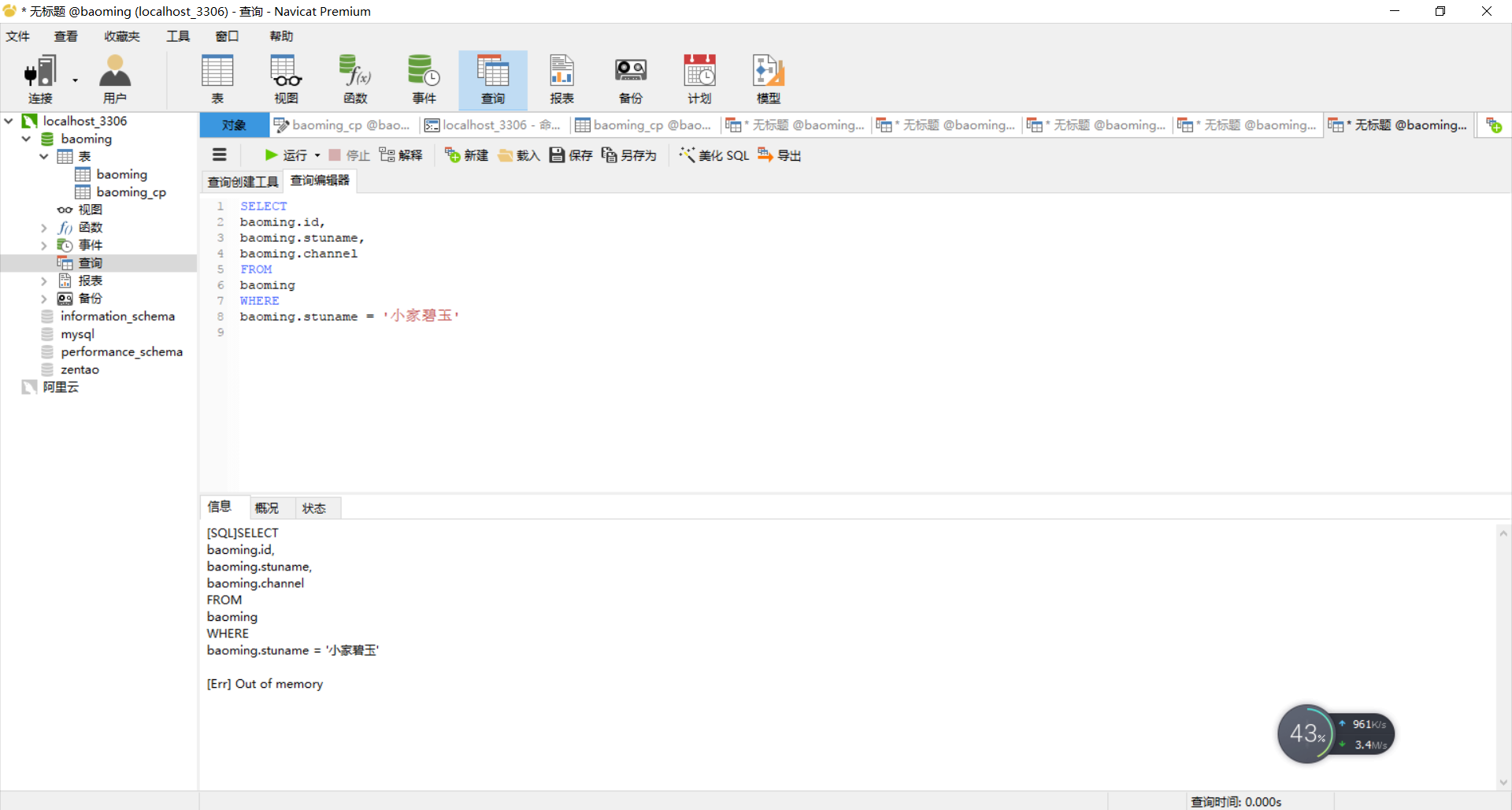
上亿级查询内存溢出了:
明天计划的事情:
23.将部署自己服务到服务器上,包括Maven,Mysql客户端等。直接用Maven命令跑单元测试。
24.直接执行Main方法,去在服务器上跑通流程。
25.测试一下不关闭连接池的时候,在Main函数里写1000个循环调用会出现什么情况。
遇到的问题:
中间有个bug,Data truncation: Incorrect string value
'\xF0\x9F\x98\xAD'
。
看了一下表,之后就知道大概是数据库很多字段是拉丁编码,而idea这边是utf-8.
用navicat跑一下就可以搞定了。
亿级别数据查询内存溢出:
今天没找到解决方法。
还有Btree对于中文索引支持不佳
收获:
知道了mysql对于中文索引支持很差。
索引并不是一定要加,数据量大的时候,
插入性能很差。




评论