今天完成的事情:
首先学习了一下关于自定义标签tld。
首先是创建标签类继承自SimpleTagSupport:
public class DateTag extends SimpleTagSupport {//重写SimpleTagSupport类里面的doTag方法,创建自己的时间获取方法:
@Override
public void doTag() throws JspException, IOException {
PageContext ctx = (PageContext) getJspContext();
JspWriter out = ctx.getOut();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日");
out.println(sdf.format(new Date()));
}
}
然后是是创建并定义mytag1.tld文件:
<?xml version="1.0" encoding="UTF-8" ?>
<tlib-version>1.1</tlib-version>
<short-name>c1</short-name>
<!--Jsp文件引用Tag的相对路径-->
<uri>http://www.tarena.com.cn/mytag1</uri>
<tag>
<!--创建的Tag名称-->
<name>date</name>
<!--Tag相对应的类路径-->
<tag-class>com.jnshu.tld.DateTag</tag-class>
<body-content>empty</body-content>
</tag>
</taglib>
然后是在Jsp文件中引用标签:
最后是使用标签:
将标签传递过来的数据输出到JsP网页中。
展示结果如下:
定义标签需要定义相关的标签类。在类中编写相关与标签的方法。
<?xml version="1.0" encoding="UTF-8"?>
version="2.0">
<tlib-version>1.0</tlib-version>
<short-name>isnull</short-name><!-- 定义标签使用的短名称 -->
<!-- 自定义标签的形参都是域里面传递的参数值;自定义标签基本使用在jsp页面上 -->
<function>
<description>判断传递内容是否为空</description><!-- 对该标签的说明 -->
<name>hasvalue</name><!-- 定义标签名,放在短标签之后 -->
<function-class>util.Tld_util</function-class><!-- 标签处理域值的类路径 -->
<function-signature>boolean isnull(java.lang.String)</function-signature><!-- 标签处理域值的具体的类方法 -->
<example>${isnull:hasvalue(obj1)}</example><!-- 自定义标签的使用示范 ,域参数会自动传递到具体的方法里面-->
</function>
</taglib>
下午主要研究了一下关于多表联查的知识。
CREATE DATABASE IF NOT EXISTS TestDB DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
USE TestDB;
DROP TABLE IF EXISTS Students;
CREATE TABLE Students(ID int primary key not null,Name nvarchar(50),Age int,City nvarchar(50),MajorID int);
DROP TABLE IF EXISTS Majors;
CREATE TABLE Majors(ID int primary key not null,Name nvarchar(50));
DROP TABLE IF EXISTS Teachers;
CREATE TABLE Teachers(ID int primary key not null,Name nvarchar(20)not null);
DELETE FROM Students;
INSERT INTO Students(ID,Name,Age,City,MajorID)VALUES(101,'Tom',20,'BeiJing',10);
INSERT INTO Students(ID,Name,Age,City,MajorID)VALUES(102,'Lucy',18,'ShangHai',11);
DELETE FROM Majors;
INSERT INTO Majors(ID,Name)VALUES(10,'English');
INSERT INTO Majors(ID,Name)VALUES(12,'Computer');
DELETE FROM Teachers;
INSERT INTO Teachers(ID,Name)VALUES(101,'Mrs Lee');
INSERT INTO Teachers(ID,Name)VALUES(102,'Lucy');
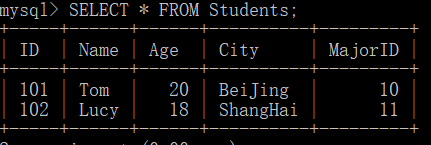
SELECT * FROM Students;
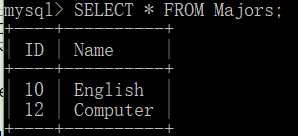
SELECT * FROM Majors;
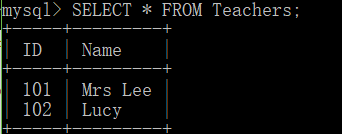
SELECT * FROM Teachers;
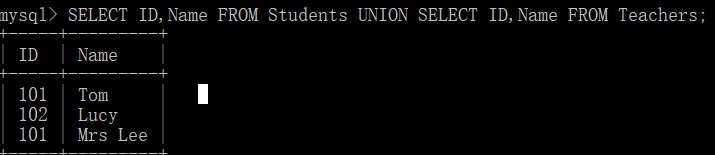
SELECT ID,Name FROM Students UNION SELECT ID,Name FROM Teachers;
首先 UNION 操作符用于合并两个或多个 SELECT 语句的结果集。 UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。
结果如下:
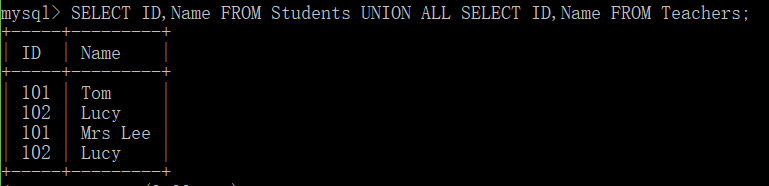
SELECT ID,Name FROM Students UNION ALL SELECT ID,Name FROM Teachers;
当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行。两种情况下,派生表的每一行不是来自 TABLE1 就是来自 TABLE2。
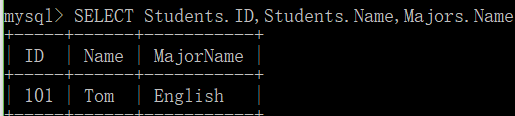
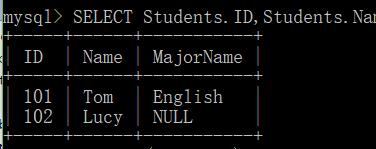
SELECT Students.ID,Students.Name,Majors.Name AS MajorName FROM Students INNER JOIN Majors ON Students.MajorID=Majors.ID;
INNER JOIN(内连接)
作用:根据两个或多个表中的列之间的关系,从这些表中查询数据。
注意: 内连接是从结果中删除其他被连接表中没有匹配行的所有行,所以内连接可能会丢失信息。
重点:内连接,只查匹配行。
语法:SELECT fieldlist FROM 表1 [INNER] join table2 ON 表1.column=表2.列;
SELECT Students.ID,Students.Name,Majors.Name AS MajorName FROM Students LEFT JOIN Majors ON Students.MajorID=Majors.ID;
外连接
与内连接相比,即使没有匹配行,也会返回一个表的全集。
外连接分为三种:左外连接,右外连接,全外连接。
对应SQL:LEFT/RIGHT/FULL OUTER JOIN。通常我们省略outer 这个关键字。写成:LEFT/RIGHT/FULL JOIN。
重点:至少有一方保留全集,没有匹配行用NULL代替。
1)LEFT OUTER JOIN,简称LEFT JOIN,左外连接(左连接)
结果集保留左表的所有行,但只包含第二个表与第一表匹配的行。第二个表相应的空行被放入NULL值。
结论:
通过结果,我们可以看到左连接包含了第一张表的所有信息,在第二张表中如果没有匹配项,则用NULL代替。
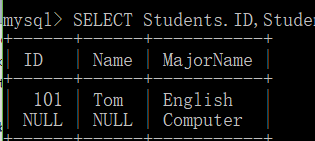
SELECT Students.ID,Students.Name,Majors.Name AS MajorName FROM Students RIGHT JOIN Majors ON Students.MajorID = Majors.ID;
RIGHT JOIN(right outer join)右外连接(右连接)
右外连接保留了第二个表的所有行,但只包含第一个表与第二个表匹配的行。第一个表相应空行被入NULL值。
右连接与左连接思想类似。只是第二张保留全集,如果第一张表中没有匹配项,用NULL代替
通过结果可以看到,包含了第二张表Majors的全集,Computer在Students表中没有匹配项,就用NULL代替。
SELECT Students.ID, Students.Name, Majors.Name AS MajorName FROM Students FULL JOIN Majors ON Students.MajorID=Majors.ID;
不知道为什么,使用全连接会报错。说什么找不到表。
SELECT Students.ID,Students.Name,Majors.Name AS MajorName FROM Students CROSS JOIN Majors;
交叉连接。交叉连接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉连接也称作笛卡尔积。
简单查询两张表组合,这是求笛卡儿积,效率最低。
SELECT Students.ID,Students.Name,Majors.Name AS MajorName FROM Students CROSS JOIN Majors WHERE Students.MajorID=Majors.ID;
为交叉连接添加查询条件
注意:在使用CROSS JOIN关键字交叉连接表时,因为生成的是两个表的笛卡尔积,因而不能使用ON关键字,只能在WHERE子句中定义搜索条件。
SELECT Students.ID,Students.Name,Majors.Name AS MajorName FROM Students,Majors;
查询多表,其实也是笛卡儿积,与CROSS JOIN等价,以下查询同上述结果一样。
这个可能很常见,但是大家一定要注意了,这样就查询了两张表中所有组合的全集。
晚上在整理关于数据表该如何搭建的问题,初步整理如下。
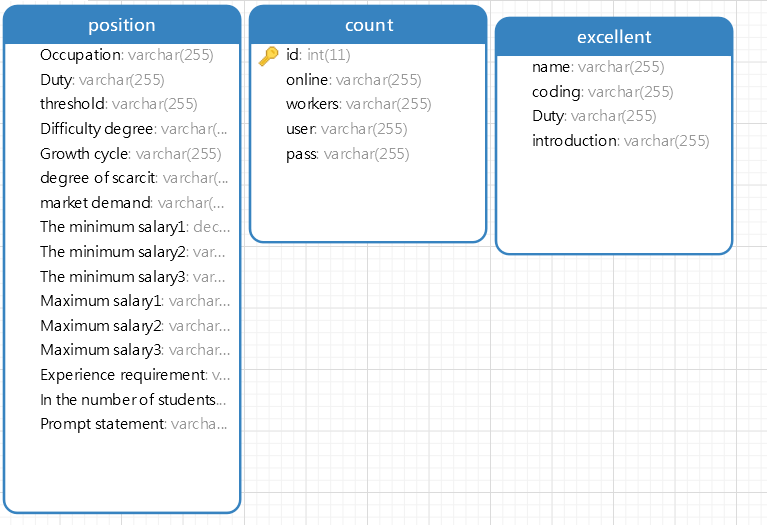
明天计划的事情:完成数据表的搭建,开始编写项目。
遇到的问题:
收获:
1.启动tomcat时候,IDEA弹出的两个窗口实际上是Tomcat下的两个日志文件,输出的内容就是两个日志文件记录的关于此项目运行的日志记录。
2.在别人那发现一个可以在本地编辑服务器脚本的SSH,很强大!
3.应该先把数据表整理出来,然后再学习数据库多表联查的,感觉有些本末倒置了。
进度:完成数据表的搭建的话,应该就舒服多了吧。
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
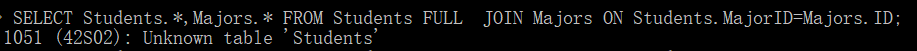
.png)

.png)

.png)





评论