发表于: 2018-01-25 17:33:06
1 642
今天完成的事情:
按照师兄的建议
1 又测了一下
单个web容器,Redis缓存,jsp页面,20线程,1秒启动,一直循环
忘截图了,但是记得90%line是在4600左右。
单个web容器,Redis缓存,json数据,20线程,1秒启动,一直循环

进服务器看看Nginx响应时间(重写了下脚本,现在可以读取键盘输入的参数了):
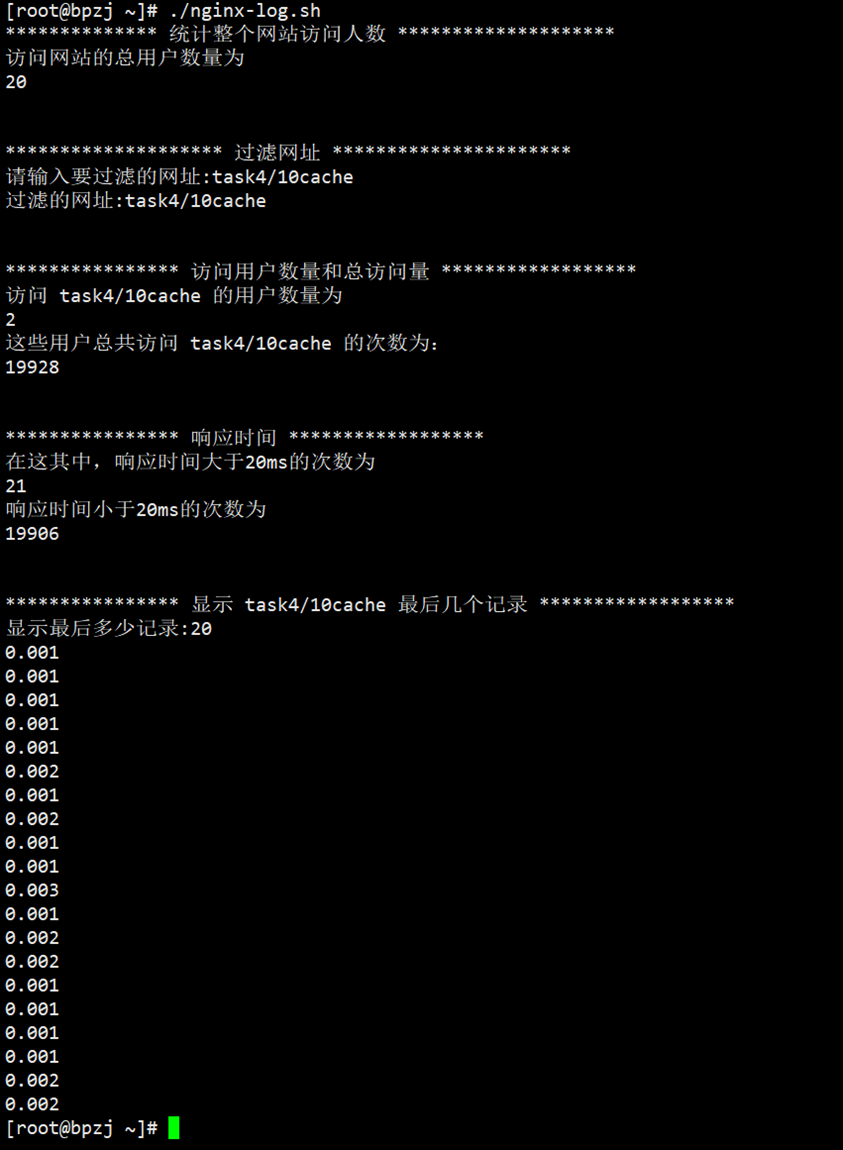
发现Nginx响应时间并不高,最高也就是3ms,按照这个效率,1s应该可以处理 300个请求左右啊,
然后看下resin容器的反应时间
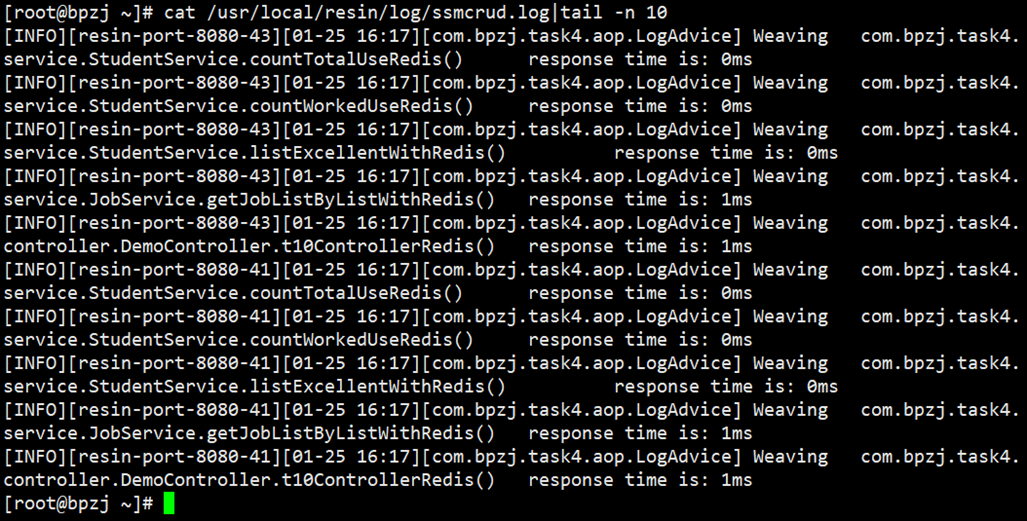
也挺快啊,service层几乎没有时间,controller层也就1秒左右
2 思考:
jmeter的响应时间应该=
客户端发送请求到Nginx的时间 + 创建连接并保持连接的时间 + Nginx转发请求到web容器的时间+web容器处理的时间+web容器返回响应给Nginx的时间 +Nginx返回响应并结束连接的时间+请求从网络传输到客户端的时间
这个标黄的Nginx转发请求到web容器的时间+web容器处理的时间+web容器返回响应给Nginx的时间 应该就是Nginx日志中的时间,<3ms
剩下的时间到哪去了?
创建socket连接并保持连接的时间、Nginx返回响应并结束socket连接的时间这个应该是和Nginx有关的,那就优化下Nginx的配置吧。
3 是不是Nginx的问题?
然后就搜了下Nginx优化,
http://blog.csdn.net/weiyuefei/article/details/51727191
http://blog.csdn.net/zdp072/article/details/51078138
http://blog.csdn.net/hjh15827475896/article/details/53442800
一顿配置后,再测jsp页面,原来90%Line在4000多,现在到了2500左右。

再测json,发现变化不大,感觉应该是json已经到极限了,改Nginx没啥效果,90%line还是300ms左右。
这些配置了,还有是Linux系统级的配置,比如系统最大的socket连接数量,tcp连接的各种策略,文件读取的限制。
也算了解了不少。
那剩下的就是网络传输占用的时间了。
我在淮北,买的阿里云是华南的,这个真是失误啊。不好做对比了,但是这个应该有一定关系。测下1个线程:
手动点了15次:

也就是说,就算只有一个人访问,最少也得要100ms,估计网络传输时间占了一大部分。
4 综上所述
使用json传输提高最大
其他优化方法:使用缓存,优化Nginx配置,优化服务器系统配置(socket、tcp等配置)
应该还可以优化:web容器配置,程序本身
现在程序逻辑很简单,而且响应时间也就几ms,就主要配置其他优化了。
5 Nginx负载均衡
昨天在本地试验,有效果,但是不大,今天在服务器配置了两个web容器,发现也没啥效果,如果有两个服务器配置下,应该有效果。
6 任务要求
90%line在500MS时的TPS是多少
测jsp页面:
也就能支撑3个线程。

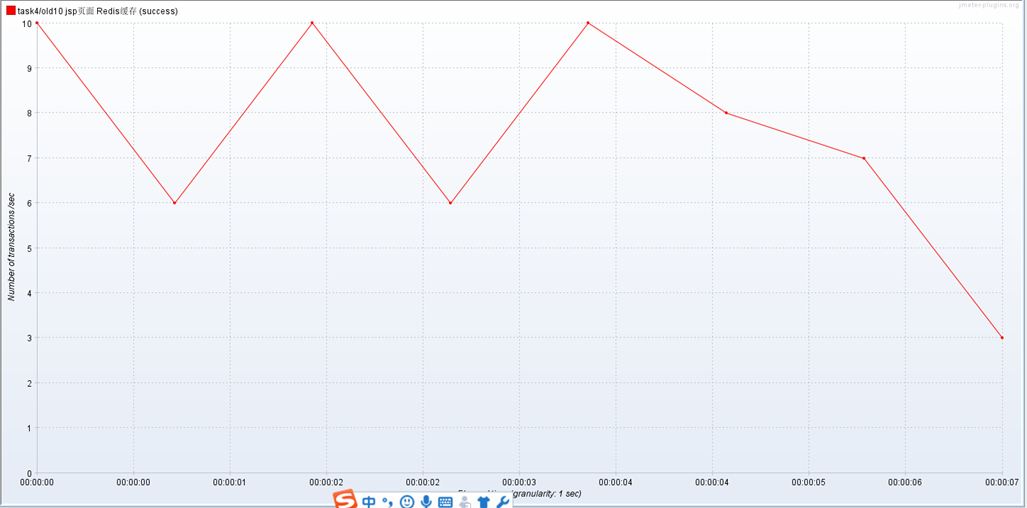
TPS为 8左右
测json数据
差不多50个线程

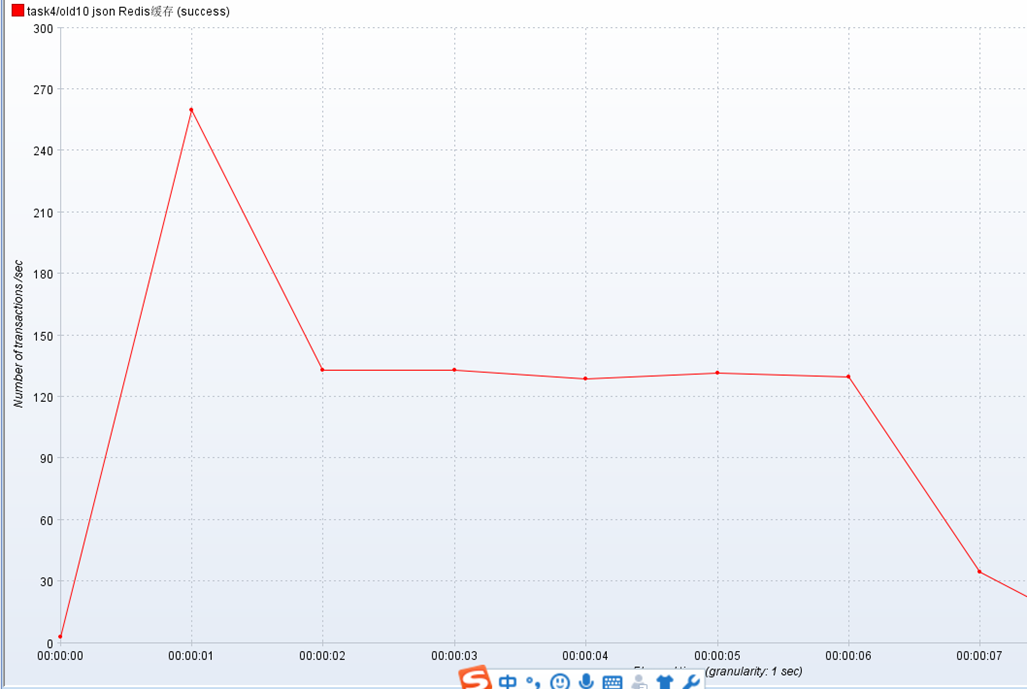
TPS在120左右。
模拟下缓存穿透
/**
* 测试 缓存穿透 ,也就是 数据库中没有数据,缓存也没有
* @return
*/
public Student DataBaseNoValueUseRedis() {
try {
Student student = (Student) redisTemplate.opsForHash().get("student","noData");
if (student == null) {
student = studentMapper.selectByPrimaryKey(300);
redisTemplate.opsForHash().put("student","noData",student);
return student;
}
return student;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
/**
* 模拟 缓存穿透
* @param request
* @param model
* @return
*/
@RequestMapping(value = "/nodata")
@ResponseBody
public Student noData(HttpServletRequest request, Model model) {
Student student = studentService.DataBaseNoValueUseRedis();
return student;
}
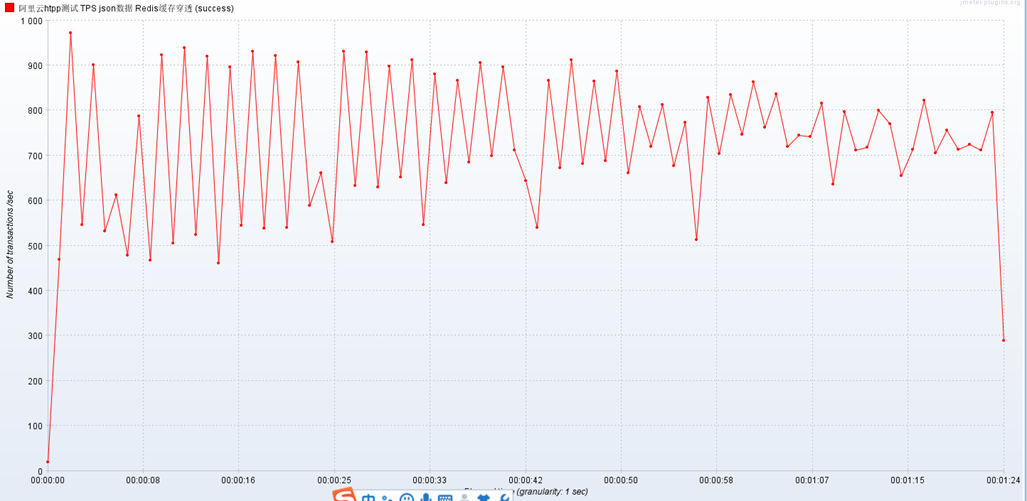
亮瞎我的眼
TPS竟然高达700多,比上边120还多。
猜测是因为逻辑太简单,而且用的是json,直接返回的就是空数据。如果是逻辑复杂,在service层的时间应该会大大增加,那时候就会出问题了。
解决办法:
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
7 其他缓存问题
7.1 主从一致性(比如共享session的问题)
7.2 缓存命中(多个服务器配置了redis,如何正确命中缓存所在的服务器)
memcached使用的是一致hash算法,来命中缓存所在的服务器。
7.3 缓存更新问题、几个更新模式、数据一致性(脏数据问题)
7.4 缓存穿透、缓存雪崩、缓存失效、缓存并发。。。
8 深度思考
为什么要使用memcache?memcashe有什么作用?
减轻数据库压力,提高服务器访问性能,典型的用程序提升了性能,不用加设备,不用加钱,只是程序员加加班就提升性能,O(∩_∩)O哈哈~
如果有一天,硬盘的速度赶上了内存,也就没必要用缓存了,哈哈。
什么是负载均衡,为什么要做负载均衡?
加缓存也扛不住,只能堆硬件了,多个硬件服务器,就要用负载均衡了。
我理解就是Nginx在最前边挡住了所有请求,然后根据我们的配置,来选择一个真正的服务器硬件,把请求转发给它,真正的服务器处理完成后再把结果返回给Nginx。
为啥做?一个服务器不够用了,就好比顺丰原来只有一个快递点,很多人打电话来要寄快递,让顺丰上门取件。然后顺丰发现请求太多,忙不过来。就设了很多分站点。
顺丰总部就是那个Nginx,你向顺丰总部打电话(向Nginx发请求),然后他就让某个特定的快递站点来处理你的请求。
真正的原因,就是一台服务器无法处理过多请求,堆数量,就出来这么一个解决方案。有需求,才有创造。
nginx如何实现负载均衡?
实现负载均衡有5种算法,其中分别为轮询、ip_hash、weight(upstream)、fair(第三方)、url_hash。
明天计划的事情:
任务7
遇到的问题:
暂无
收获:
见上。




评论