发表于: 2018-01-25 14:13:22
5 750
补日报2018-01-24
一、今天完成的事情:
(三)安装tomcat
为了让helloworld项目能运行起来,安装apache tomcat
1.打开Terminal,进入ApacheTomcat所在目录的bin目录下
cd /Users/leeyo/Library/ApacheTomcat/bin
2.启动Tomcat
./startup.sh
3.出现The file is absent or does not have execute permission报错,
修改bin目录下.sh文件权限
chmod u+x *.sh
4.重启tomcat
5.在浏览器地址栏输入:http://localhost:8080验证
6.关闭Tomcat
./shutdown.sh
(四)配置ITEA与tomcat服务器
打开项目-点击run-点击编辑配置
添加tomcat-local,默认选择本地安装的tomcat 8.5.27版本
添加name:Tomcat
切换到deployment,添加

点apply后,run即可,自动打开浏览器页面展示hello world
(五)建立一个普通maven项目
创建maven项目时使用quickstart
(六)学习java基础语法:how2j
变量:
1.变量
2.基本类型
3.字面值
4.类型转换
5.命名规则
6.作用域
7.final
8.表达式
9.块
面向对象:
1.类和对象
2.属性
3.方法
二、明天计划的事情:
学习how2j的java基础部分
1.操作符
2.控制流程
3.数组
三、遇到的问题:
做任务一创建maven项目时,建错创建了webapp,调试时发现需要搭web服务器运行,配置了半天tomcat运行起来,才发现和任务需求有些不一样。
然后用quickstart新创建了一个才正常,而且很适合学习java基础语法时练手做项目。
四、收获:
java语法方面之前有接触过,在重新学习的时候,感觉很快就捡起来用。
多操作多敲代码,学习来就是快。
自己学习比看视频效果更好,更节省时间。
学习的知识点较多,没有详细写,之后注意。
补日报2018-01-23
一、今天完成的事情:
(一)数据库完成学员报名的DB设计并读写数据库
学员线下报名格式为:
姓名:varchar(50)
qq:INT
修真类型:
预计入学时间:
毕业院校:
线上学号:
日报链接:
立愿:
推荐人:
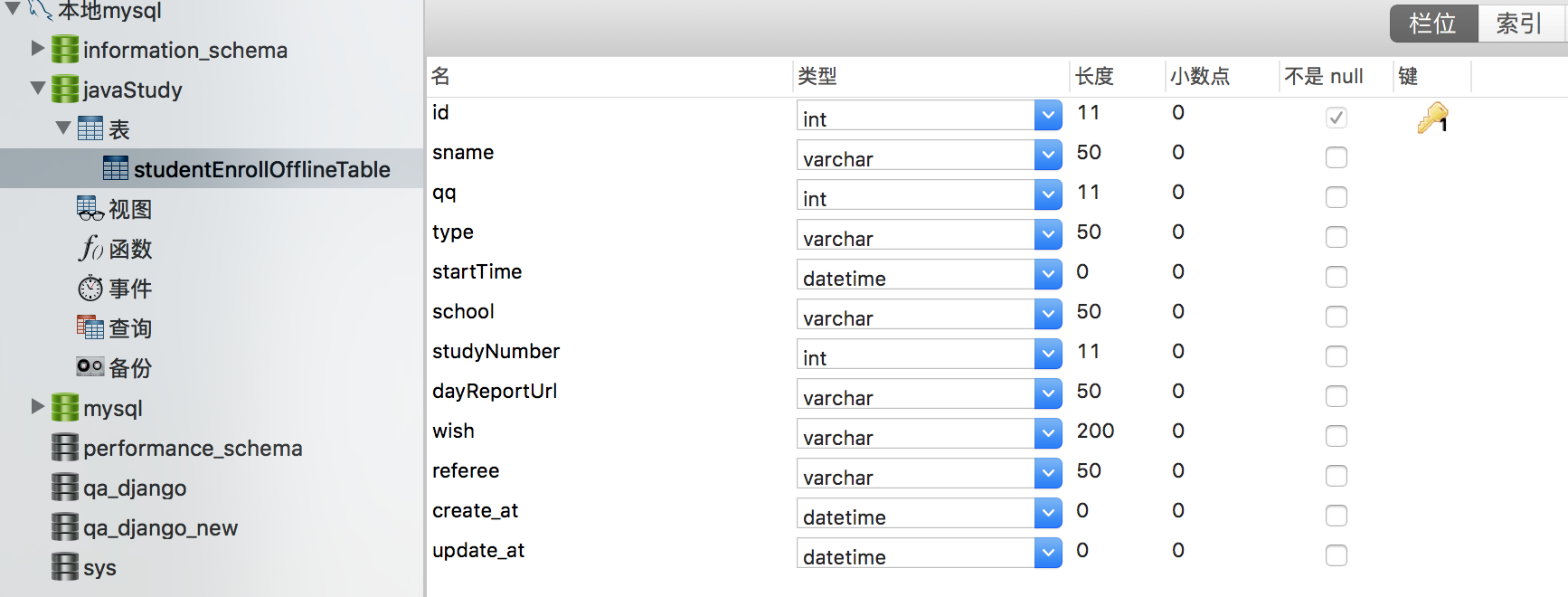
表名:studentEnrollOfflineTable
表结构如下:
| id | sname | type | startTime | school | studyNumber | dayReportUrl | wish | referee | create_at | update_at | |
| INT | varchar(50) | INT | varchar(50) | Date | varchar(50) | INT | varchar(200) | varchar(200) | varchar(50) | Long | Long |
| 唯一PRIMARY KEY | |||||||||||
| 自增AUTO_INCREMENT |
Navicat中创建数据库:javaStudy
在数据库中创建表:studentEnrollOfflineTable
sql语句如下:
create table if not exists studentEnrollOfflineTable(
id INT PRIMARY KEY AUTO_INCREMENT,
sname varchar(50),
qq int,
type varchar(50),
startTime datetime,
school varchar(50),
studyNumber int,
dayReportUrl varchar(50),
wish varchar(200),
referee varchar(50),
create_at datetime,
update_at datetime
);
插入最新一条报名的师弟:我
insert into studentEnrollOfflineTable values (1,'liyang','616103556','外门弟子','2018-01-23','哈尔滨工业大学华德应用技术学院','3148','http://www.jnshu.com/school/21275/daily','修炼java成仙@。@','无','2018-01-23','2018-01-23';);
根据姓名查询此条数据
select * from studentEnrollOfflineTable where sname = ‘liyang’;
修改宣言为老大最帅
update studentEnrollOfflineTable set wish = '老大最帅' where id = 1;
删除此条数据
delete from studentEnrollOfflineTable where id = 1;
在name上创建索引
Create index indexName
On studentEnrollOfflineTable (sname);
插入10条数据,查看有索引和无索引的情况下,Sql语句执行的效率
10条数据对比。查询时间都是0秒

(二)java环境搭建、IDEA搭建
官网下载jdk1.8,安装并配置java环境变量
创建一个maven项目,create new perject,选中maven,勾选create from archetype,选中列表中webapp,next。
在接下来出现的页面中,输入GroupID,ArtifacID(在网上看到关于这两个名词的解释:groupId:定义了项目属于哪个组,一般来说这个通常和公司或组织关联,比如说,你所在的公司为mycom.那就应该定义为com.mycom.mymaven,mymaven为项目名称
artifactId:定 义了当前Maven项目在组中的唯一id,例如HelloMaven这个项目,我则把他定义为hello-maven,还例如spring项目,他的 groupId为org.springframework,对于content项目来说artifactId则为spring-content,web项 目则为spring-web)
输入完毕之后,点击next,出现如下界面,点击next,随后的界面输入项目名称,项目地址,点击finish即可....
二、明天计划的事情:
学习how2j的java基础部分
三、遇到的问题:
IDEA免费注册码不能用,查看评论修改下hosts 文件 加入一行 0.0.0.0 account.jetbrains.com 就可以了
四、收获:
聚集索引:
- 聚集索引的意思可以理解为顺序排列,比如一个主键自增的表即为聚集索引,即id为1的存在于第一条,id为2的存在于第二条...假使数据库中是使用数组来存放的这张表中的数据,那么如果我需要查找第100条,那么直接第一条数据的地址加上100即为第一百条的地址,一次就能查询出来。
- 因为数据库中的数据只能按照一个顺序进行排列,所以聚集索引一个数据库只能有一个。
- 在mysql中,不能自己创建聚集索引,主键即为聚集索引,如果没有创建主键,那么默认非空的列为聚集索引,如果没有非空的列那么会自动生成一个隐藏列为聚集索引。
- 一般在mysql中,我们创建的主键即为聚集索引,数据是按照我们的主键顺序进行排列。所以在根据主键进行查询时会非常快。
非聚集索引:
1.非聚集索引可以简单理解为有序目录,是一种以空间换取时间的方法。举个例子,在一个user表中,有一个id_num,即身份号,此不为主键id,那么这些数据在存储的时候都是无序的。
2.id为1的id_num为100,id为2的id_num为97,id为3的id_num为98,id为4的id_num为99,id为5的id_num为96。。。id为67的id_num为56。。。
那么如果我要查找id_num为56的人,那么只能一条一条的遍历,n条就需要查询n次,时间复杂度为O(n),这是非常耗费性能的。
3.现在就需要为id_num增加非聚集索引,添加了非聚集索引后,会给id_num进行排序(内部使用结构为B+树),并且排序后,我只需要查询此目录(即查询B+树),很快就知道为id为56的在数据库中的第67条,而不需要在去遍历表中的所有数据。
4.在非聚集索引中,不重复的数据越多,那么索引的效率越高。
5.我们平常在数据库中使用的索引一般为非聚集索引。
创建唯一索引:在创建了唯一索引之后,列中值不能重复,比如,现在我给表中插入一条重复的值,会报:Error Code: 1062. Duplicate entry '3' for key 'id_num_index'
1.创建索引:CREATE UNIQUE INDEX 索引名 ON 表名(列的列表)。
2.在表上增加索引:ALTER TABLE 表名ADD UNIQUE 索引名 (列的列表)。
3.创建表时指定索引:CREATE TABLE 表名( [...], UNIQUE 索引名 (列的列表) )。
创建普通索引:
模式:CREATE INDEX 索引名 ON 表名(列名1,列名2,...);
修改表: ALTER TABLE 表名ADD INDEX 索引名 (列名1,列名2,...);
创建表时指定索引:CREATE TABLE 表名 ( [...], INDEX 索引名 (列名1,列名 2,...) );
查看索引:
show index from 表名
删除索引:
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
索引的选择原则:
1.较频繁的作为查询条件的字段应该创建索引
2.重复太多的字段不适合单独创建索引,即使频繁作为查询条件
3.不会出现在WHERE子句中的字段不应该创建索引
以下两种情况不建议使用索引:
1.表的记录比较少,比如只有几百,一千条记录,那么没必要建立索引,直接全表查询即可。
2.不重复的字段越多,那么索引的价值越高,查看不重复的字段占总体的比例可以使用下面的sql语句:
SELECT count(DISTINCT(name))/count(*) AS Selectivity FROM index_test;
比如上面这个sql就是判断index_test表中name字段中不重复的值占整体的比例,这个比例应该在(0,1]之间,这个数值越大,越应该使用索引。
学习了数据库字符集的区别:
utf8_unicode_ci和utf8_general_ci对中、英文来说没有实质的差别。
utf8_general_ci校对速度快,但准确度稍差。
utf8_unicode_ci准确度高,但校对速度稍慢。
如果应用有德语、法语或者俄语,一定使用utf8_unicode_ci。一般用utf8_general_ci就够了




评论