发表于: 2018-01-24 18:30:28
3 712
今天完成的事情:
1 压力测试
使用jmeter进行压力测试
安装jmeter、jmeter的tps插件(tps可视化)、badboy插件(录制请求)
具体过程不在赘述。
然后是具体测试:
|
| 无缓存jsp | 无缓存json | memcache缓存jsp | memcache缓存json | Redis缓存jsp | redis缓存json |
本地测试 | 本地单个web容器测试 | √ |
| √ | √ | √ | √ |
本地多个web容器,模拟Nginx负载均衡 |
|
|
|
| √ | √ | |
服务器测试 | 服务器单个web容器测试 | √ | √ |
|
| √ | √ |
多个服务器,Nginx负载均衡测试 |
|
|
|
|
|
|
以下是测试结果:
2 本地单个web容器
那些图片就不贴了。

使用redis缓存
本地单个web容器,jsp页面,redis缓存,200线程,效果和memcache差不多



这三张图都是200线程的。
本地单个web容器,json数据,redis缓存,200线程,比memcache快不少


3 本地2个web容器,模拟负载均衡
499错误
测试nginx发现如果两次提交post过快就会出现499的情况,看来是nginx认为是不安全的连接,主动拒绝了客户端的连接。
proxy_ignore_client_abort on;
表示代理服务端不要主要主动关闭客户端连接。
复制tomcat文件夹,然后修改service.xml文件,端口设置,改为8081
在Nginx配置文件中配置upstream
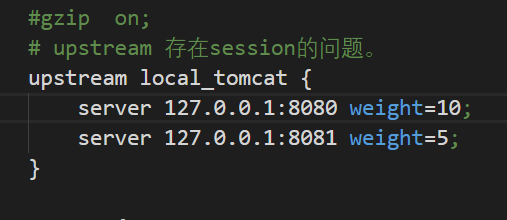
注意:如果开启ipv6,不要使用localhost,直接用127.0.0.1
测试jsp页面,200线程,redis缓存,Nginx负载均衡,和单个web容器相比,提升不大。

测试json数据,200线程,redis缓存,Nginx负载均衡,竟然比单个web容器还慢。

难道是因为多经过了Nginx转发这一层,所以变慢了。因为json就是字符串,Nginx代理没起啥作用?
又测试了下,发下Nginx不是很稳定,有时候比单个web容器性能高,有时候又掉回去了。
4 服务器测试
单个web容器,无缓存,jsp页面
25线程

30线程左右,程序挂掉:

35线程

单个web容器,不用缓存,json数据
30线程

不敢相信,json和jsp差距这么大
用json,轻轻送送200线程没问题。

单个web容器,使用Redis缓存,jsp页面
20线程

25线程


30线程,循环20次

这跟不用缓存差别不大啊,真是让人头疼。
网络延时的因素太大了。
单个web容器,使用Redis缓存,json数据
直接上200线程

和不用缓存差别不大。
结论:
使用缓存,在本地试验中,效果显著;但是在服务器上,只有一点点提升
使用Nginx做负载均衡,提升也有,效果不是很明显。
使用json传输数据,提升巨大,效果十分显著,在服务器端,可以说提升几十倍?
5 如何使用redis缓存
三种方法在SSM项目中使用Redis
方法 | jar包 |
|
1、只用Redis驱动,自己写工具类 | Jedis或。。其他Redis驱动 |
|
2、在1的基础上,使用Spring Data Redis来操作 | Spring Data Redis jar包 使用方法2种: | Spring Data Redis进一步对Jedis或其他驱动的jar包进行封装,类似于spring对jdbc封装,提供了一个JdbcTemplate,这里也提供了一个RedisTemplate。 |
3、在mybatis层配置Redis | mybatis-redis jar包 Jedis jar包 | 直接在mybatis层开启了缓存,解耦更充分,但是逻辑可能不是我们需要的。 相当于缓存了sql语句,也就是说同样的sql语句,就直接从缓存取数据了。 |
我这里用了第2种方法,而且是直接在Service层写了操作缓存的语句。
如果用第1种,自己手写工具类,对数据保存的过程控制,逻辑处理会更清晰,我只抄了一个工具类,测试了下能通过,就用第2种方法了。
为什么没用注解呢?试验没成功,太失败了,报错No bean,没时间搞了。
同样,mybatis配置redis做缓存也失败了。
学习redis 的hash类型、序列化、反序列化方法。
简单的来说就是为了保存各个对象在内存中的状态,并且可以把保存的对象状态读出来。虽然你可以用你自己的各种各样的方法来保存 object states,但是java给你提供一种应该比你自己好的保存对象状态的机制,那就是序列化。
http://blog.csdn.net/neosmith/article/details/17068365
序列化的对象要重写hashCode和equals方法。
redis保存java bean数据时,需要配置好hashKeySerializer、hashValueSerializer这两个东西,才能正确的把java bean序列化为hash数据。
详细的配置在卢静师兄的日报中,我就不贴了。
2.拦截器、过滤器、监听器各有什么作用?
过滤器(Filter):当你有一堆东西的时候,你只希望选择符合你要求的某一些东西。定义这些要求的工具,就是过滤器。拦截器(Interceptor):在一个流程正在进行的时候,你希望干预它的进展,甚至终止它进行,这是拦截器做的事情。监听器(Listener):当一个事件发生的时候,你希望获得这个事件发生的详细信息,而并不想干预这个事件本身的进程,这就要用到监听器。
明天计划的事情:
看看任务6的其他问题。
开始任务7,有时间再看下多线程、再看下序列化、反射、AOP、。
遇到的问题:
暂无
收获:
见上。




评论