发表于: 2018-01-17 20:27:17
1 764
完成
1.数据库里插入100万条数据,对比建索引和不建索引的效率查别
参考网页:https://www.cnblogs.com/fanwencong/p/5765136.html
代码:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.Date;
import com.mysql.jdbc.PreparedStatement;
public class InsertTest {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
final String url = "jdbc:mysql://39.107.103.103/Princiman";
final String name = "com.mysql.jdbc.Driver";
final String user = "root";
final String password = "1234";
Connection conn = null;
Class.forName(name);//指定连接类型
conn = DriverManager.getConnection(url, user, password);//获取连接
if (conn != null) {
System.out.println("获取连接成功");
insert(conn);
} else {
System.out.println("获取连接失败");
}
}
public static void insert(Connection conn) {
// 开始时间
Long begin = new Date().getTime();
// sql前缀
String prefix = "INSERT INTO teacher (count,name,password,sex,description,url,school,date,remark) VALUES ";
try {
// 保存sql后缀
StringBuffer suffix = new StringBuffer();
// 设置事务为非自动提交
conn.setAutoCommit(false);
// 比起st,pst会更好些
PreparedStatement pst = (PreparedStatement) conn.prepareStatement("");//准备执行语句
// 外层循环,总提交事务次数
for (int i = 1; i <= 100; i++) {
suffix = new StringBuffer();
// 第j次提交步长
for (int j = 1; j <= 10000; j++) {
// 构建SQL后缀
suffix.append("('" + j * i + "','" + i * j + "','123456'" + ",'nv'" + ",'teacher'" + ",'www.bbk.com'" + ",'university'" + ",'" + "2016-08-12 14:43:26" + "','note'" + "),");
}
// 构建完整SQL
String sql = prefix + suffix.substring(0, suffix.length() - 1);
// 添加执行SQL
pst.addBatch(sql);
// 执行操作
pst.executeBatch();
// 提交事务
conn.commit();
// 清空上一次添加的数据
suffix = new StringBuffer();
}
// 头等连接
pst.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
// 结束时间
Long end = new Date().getTime();
// 耗时
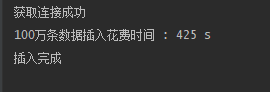
System.out.println("100万条数据插入花费时间 : " + (end - begin) / 1000 + " s");
System.out.println("插入完成");
}
}
运行结果
再插入1000万条
运到问题,说max_allowed_packet参数限制,插入不成功
解决办法:http://www.jb51.net/article/50364.htm
最后
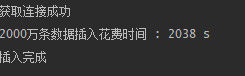 (这里是1000万,不是2000万)
(这里是1000万,不是2000万)
心想着应该是425s的十倍呀,没想到用时这么少。
接着比较有无索引的差别:
没索引

有索引

可见有索引能加快搜索效率。
这里卡了一个多小时:因为之前把索引建在一个99.99%重复数据的password下,导致有没有索引查询时间都无差别,如图,最后找到问题所在把,索引建在重复率很少的count下,才有了以上结果。
2.初步学习连接池
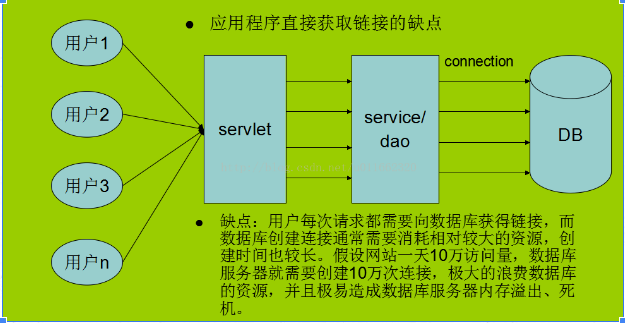
数据池:创建数据库连接是一个很耗时的操作,也容易对数据库造成安全隐患。所以,在程序初始化的时候,集中创建多个数据库连接,并把他们集中管理,供程序使用,可以保证较快的数据库读写速度,还更加安全可靠。

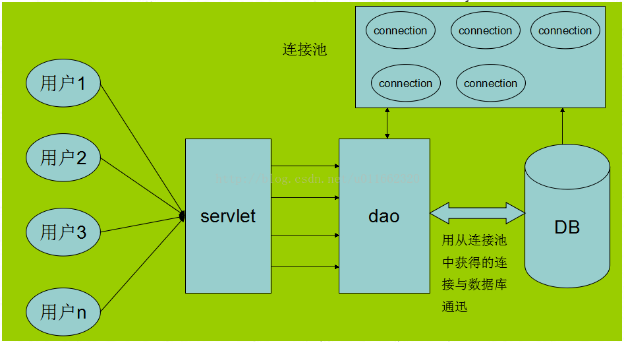
参考http://blog.csdn.net/wenwen091100304/article/details/48035003
<dependency>
<groupId>com.mchange</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.5.2</version>
</dependency>
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import com.mysql.jdbc.jdbc2.optional.MysqlDataSource;
public class ConnectionDemo {
public static void main(String[] args) throws SQLException {
System.out.println("使用连接池................................");
for (int i = 0; i < 20; i++) {
long beginTime = System.currentTimeMillis();
Connection conn = ConnectionManager.getInstance().getConnection();
try {
PreparedStatement pstmt = conn.prepareStatement("select * from students");
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
// do nothing...
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
long endTime = System.currentTimeMillis();
System.out.println("第" + (i + 1) + "次执行花费时间为:" + (endTime - beginTime));
}
System.out.println("不使用连接池................................");
for (int i = 0; i < 20; i++) {
long beginTime = System.currentTimeMillis();
MysqlDataSource mds = new MysqlDataSource();
mds.setURL("jdbc:mysql://39.107.103.103:3306/Princiman");
mds.setUser("root");
mds.setPassword("1234");
Connection conn = mds.getConnection();
try {
PreparedStatement pstmt = conn.prepareStatement("select * from students");
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
// do nothing...
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
long endTime = System.currentTimeMillis();
System.out.println("第" + (i + 1) + "次执行花费时间为:"
+ (endTime - beginTime));
}
}
}
结果
使用连接池................................
第1次执行花费时间为:1696
第2次执行花费时间为:32
第3次执行花费时间为:38
第4次执行花费时间为:43
第5次执行花费时间为:47
第6次执行花费时间为:40
第7次执行花费时间为:41
第8次执行花费时间为:34
第9次执行花费时间为:47
第10次执行花费时间为:34
第11次执行花费时间为:46
第12次执行花费时间为:36
第13次执行花费时间为:92
第14次执行花费时间为:79
第15次执行花费时间为:104
第16次执行花费时间为:43
第17次执行花费时间为:34
第18次执行花费时间为:43
第19次执行花费时间为:33
第20次执行花费时间为:45
不使用连接池................................
第1次执行花费时间为:395
第2次执行花费时间为:407
第3次执行花费时间为:406
第4次执行花费时间为:382
第5次执行花费时间为:344
第6次执行花费时间为:361
第7次执行花费时间为:380
第8次执行花费时间为:379
第9次执行花费时间为:394
第10次执行花费时间为:345
第11次执行花费时间为:359
第12次执行花费时间为:348
第13次执行花费时间为:317
第14次执行花费时间为:340
第15次执行花费时间为:361
第16次执行花费时间为:309
第17次执行花费时间为:343
第18次执行花费时间为:354
第19次执行花费时间为:642
第20次执行花费时间为:391
测试结果表明,在使用连接池时,只在第一次初始化时,比较耗时,完成初始化之后,使用连接池进行数据库操作明显比不使用连接池花费的时间少
3.测试一下连接DB中断后TryCatch是否能正常处理。
用昨天的例子,中断DB后

连接失败,以下是catch的内容

问题
2亿条数据,生成太慢了,不知道有没有更好的方法
在Main函数里写1000个循环调用,循环调用我的理解就是递归,数据库里使用的递归,做不来。
收获
数据库的基本操作又熟悉了一遍
计划
任务1剩余的修修补补
思考题




评论