发表于: 2018-01-15 09:33:25
1 712
今天完成的事情
1.修改昨天的bug:
(1)昨天的新增学生信息报错:
Available parameters are [param7, param5, param6, param3, param4, arg6, param1, param2, arg3, arg2, arg5, arg4, arg1
拿着这个错误去百度了一下,被一篇博客说明白了:
只要把dao层代码的参数加上@param才可以
于是我按照这个说法去试了试
package com.student.dao;
import com.student.model.Student;
import org.apache.ibatis.annotations.Param;
import java.util.List;
public interface StudentDao {
public void addStudent(@Param("name") String name,@Param("qq") Integer qq,@Param("school") String school,@Param("type") String type,@Param("say") String say, @Param("create_at") Integer create_at,@Param("update_at") Integer update_at);
public void deleteStudent(int id);
public void updateStudent(@Param("student")Student student, @Param("id") int id);
public Student getStudent(int id);
public List<Student> listStudent();
}
然后部署到tomcat,运行之后可以新增学生信息了。结合之前的一次修改bug,也就是倒数第三行的修改,也是因为多个参数传参,以后记住了,多个参数记得加上@Param注解。
(2)接下来是更新学生信息的报错:点击提交之后的报错:
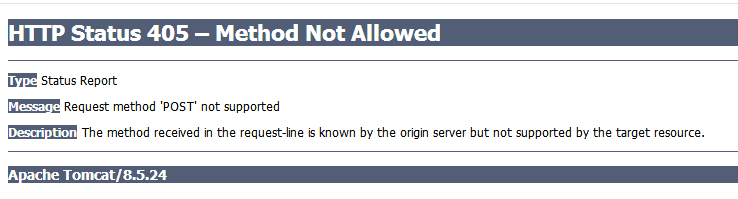
然后我去百度,我用的put方法报错却是post:
@RequestMapping(value = "/updStu/{id}",method = RequestMethod.PUT,produces = "text/html;charset=UTF-8")
public String update(Student student, @PathVariable("id") Integer id) throws IOException {
studentService.update(student,id);
return "redirect:/stus";
}
找到一篇文章说到是:因为没有用过滤器将post请求转化为put请求,我照着它是故意的加上过滤器,然后进入一个小坑:
<!-- 配置 :把POST请求转为DELETE、PUT请求 ctrl+shift+t -->
<filter>
<filter-name>HiddenHttpMethodFilter</filter-name>
<filter-class>org.springframework.web.filter.HiddenHttpMethodFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>HiddenHttpMethodFilter</filter-name>
<url-pattern>/</url-pattern>
</filter-mapping>
上面就是它说的要加的过滤器,我加了之后,tomcat无法启动,一下子很慌。。接着去百度,看到另一篇教程,也是说加过滤器,但是多了一点东西:
<!-- 配置可以把POST 请求转换为 PUT、DELETE 请求的 filter -->
<filter>
<filter-name>HiddenHttpMethodFilter</filter-name>
<filter-class>org.springframework.web.filter.HiddenHttpMethodFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>HiddenHttpMethodFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
就是url-pattren那行多了一个*号,然后就行了。一下子很好奇,我就去搜搜这是为啥呢:
震惊:博客居然说两种方式是一样的,那为什么上面的就是不行呢?我后来也有试过,就是不行。
于是换了一篇博客:
<url-pattern>/</url-pattern>:
会匹配到/springmvc这样的路径型url,不会匹配到模式为*.jsp这样的后缀型url。
<url-pattern>/*</url-pattern>:
会匹配所有的url:路径型的和后缀型的url(包括/springmvc,.jsp,.js和*.html等)。
应该就是这样了,/不能匹配到.jsp类型的url,明白了。
至此,bug修改完毕,接下来就是理解ssm的配置文件了。
在调试的过程中发现了一个bug:我在修改数据的时候有一个数据无法修改,对应我的表里面的type字段,这时候我没有着急去看哪儿出错了,而是慢慢地分析了一下这种情况出现的原因:取不到值,有可能是我表单提交那块儿的type有问题,也有可能是我之前修改update方法时sql语句除了问题,我就这样去找了,发现是sql语句出错了,没获取type的值。
2.理解ssm的配置文件:
今天读到了一篇写的非常好的ssm搭建的流程,按照里面的内容捋了一下过程:
ssm框架整合到底是怎么回事?
(1)dao层:spring和mybatis整合,由spring来管理mapper接口 m
(2)service层:spring管理接口和对象 c
(3)web层:springMVC调用service层接口 v
(1)结合我之前的理解,说一下前提,mybatis的配置文件mybatis-Config.xml,spring的配置文件applicationContext.xml。在mybatis整合spring之后,mybatis-Config.xml已经废了,所有东西都由spring接管了。所以这一步的整合是形成一个spring-mybatis.xml文件,接下来我就传一下这个文件,都应经注释好了:
spring-mybatis.xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx.xsd">
<!-- 扫描service包下所有使用注解的类型 -->
<context:component-scan base-package="com.student.service"/>
<!-- 配置数据库相关参数properties的属性:${url} -->
<context:property-placeholder location="classpath:jdbc.properties"/>
<!-- 数据库连接池 -->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.driver}"/>
<property name="jdbcUrl" value="${jdbc.url}"/>
<property name="user" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
<property name="maxPoolSize" value="${c3p0.maxPoolSize}"/>
<property name="minPoolSize" value="${c3p0.minPoolSize}"/>
<property name="autoCommitOnClose" value="${c3p0.autoCommitOnClose}"/>
<property name="checkoutTimeout" value="${c3p0.checkoutTimeout}"/>
<property name="acquireRetryAttempts" value="${c3p0.acquireRetryAttempts}"/>
</bean>
<!-- 配置SqlSessionFactory对象 -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<!-- 注入数据库连接池 -->
<property name="dataSource" ref="dataSource"/>
<!-- 扫描model包 使用别名 -->
<property name="typeAliasesPackage" value="com.student.model"/>
<!-- 扫描sql配置文件:mapper需要的xml文件 -->
<property name="mapperLocations" value="classpath:mapper/*.xml"/>
</bean>
<!-- 配置扫描Dao接口包,动态实现Dao接口,注入到spring容器中 -->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<!-- 注入sqlSessionFactory -->
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/>
<!-- 给出需要扫描Dao接口包 -->
<property name="basePackage" value="com.student.dao"/>
</bean>
<!-- 配置事务管理器 -->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<!-- 注入数据库连接池 -->
<property name="dataSource" ref="dataSource"/>
</bean>
<!-- 配置基于注解的声明式事务 -->
<tx:annotation-driven transaction-manager="transactionManager"/>
</beans>
看这个配置文件就知道了,原来放在mybatis-Config.xml文件中的东西全部放到了上面这个文件,也就是整合。
(2)service层和spring整合,service层调用mapper接口的方法
这里就传一个add方法来说明:调用了dao层的方法:
@Service("stusService")
public class StudentServiceImpl implements StudentService {
@Resource
private StudentDao studentDao;
public void create(String name, Integer qq, String school, String type, String say, Integer create_at, Integer update_at) {
studentDao.addStudent(name,qq,school,type,say,create_at,update_at);
}
(3)web层:springMVC调用service层接口,这里就需要spring-mvc.xml文件了:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc-3.0.xsd">
<!-- 扫描web相关的bean -->
<context:component-scan base-package="com.student.controller"/>
<!-- 开启SpringMVC注解模式 -->
<mvc:annotation-driven/>
<!-- 静态资源默认servlet配置 -->
<mvc:default-servlet-handler/>
<!-- 配置jsp 显示ViewResolver -->
<bean class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="viewClass" value="org.springframework.web.servlet.view.JstlView"/>
<property name="prefix" value="/WEB-INF/views/"/>
<property name="suffix" value=".jsp"/>
</bean>
</beans>
然后传一下controller的add方法加以说明:
@RequestMapping(value = "/addStu",method = RequestMethod.POST)
public String create(String name, Integer qq, String school, String type, String say, Integer create_at, Integer update_at, HttpServletRequest request, HttpServletResponse response) throws UnsupportedEncodingException {
studentService.create(name,qq,school,type,say,create_at,update_at);
return "redirect:/stus";
}
这里调用的是service层的方法。
!!!!!最重要的一步,在web.xml文件中加载所有的spring配置文件,这样才叫整合完毕:
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:spring-*.xml</param-value>
</init-param>
接下来我用大白话来说说这一系列的流程:上面动动嘴,下面跑断腿。
就拿我上传的/addStu来说,这样一个请求过来了,被servlet拦截,进了controller,在controller里面执行了方法,调用了service层的增加学生的方法,但是service层的增加学生的方法调用的是dao的方法,dao的方法又通过mapper.xml来实现,就这样层层调用,最后返回一个页面。在这个层层调用的过程中,就把ssm串联起来了。
这样说可能有点不规范,结合昨天的日报写的ssm工作流程:
客户端发送请求,后台服务器接受到请求首先被控制层(Controller)拦截,根据映射关系调用业务层(Service)的方法,找到逻辑层(ServiceImpl) ,然后通过持久层(Mapper / Dao)获取对象,对数据库进行操作,查询到的结果存储在实体类(Entity)中,最后这个结果数据会被一层一层的返回到客户端。
现在再看这个是不是感觉懂了呢?
完成整合ssm。
3.查看验收标准:
 这条还没实现,准确说不知道这个是什么?
这条还没实现,准确说不知道这个是什么?
搜了搜,发现也是个标签库。和之前用的core和form作用一样。
不过实现起来倒是比较简单,它就是一种存储数据的方式,可以转换数据格式。
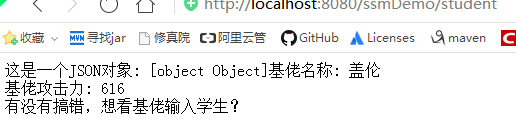
<body>
<script>
var gareen = {"name":"盖伦","hp":616};
document.write("这是一个JSON对象: "+gareen+"<br>");
document.write("基佬名称: " + gareen.name + "<br>");
document.write("基佬攻击力: " + gareen.hp + "<br>");
</script>
有没有搞错,想看基佬输入学生?
</body>
运行结果:
4.至此,任务二所有要求都已经达成。提交任务二。
5.深度思考的问题:
(1)什么是restful
所谓RESTful就是资源和表现层之间的状态转化;
对应的四种操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源。
综合上面的解释,我们总结一下什么是RESTful架构:
(1)每一个URI代表一种资源;
(2)客户端和服务器之间,传递这种资源的某种表现层;
(3)客户端通过四个HTTP动词,对服务器端资源进行操作,实现"表现层状态转化"。
(2)遵循REST规范的Web应用将会获得下面好处:
- URL具有很强可读性的,具有自描述性;
- 资源描述与视图的松耦合;
- 可提供OpenAPI,便于第三方系统集成,提高互操作性;
- 如果提供无状态的服务接口,可提高应用的水平扩展性;
(3)maven的moudle
目前还没有接触到,直接上复制的搜索答案。
所有用Maven管理的真实的项目都应该是分模块的,每个模块都对应着一个pom.xml。它们之间通过继承和聚合(也称作多模块,multi-module)相互关联。
(4)HTTP协议是用于从WWW服务器传输超文本到本地浏览器的传输协议,是一个客户端和服务端请求和应答的标准。
客户端向服务器发送一个请求,请求头包含请求的方法、URL、协议版本、以及包含请求修饰符、客户信息和内容的类似于MIME的消息结构。服务器以一个状态行作为响应,响应的内容包括消息协议的版本,成功或者错误编码加上包含服务器信息、实体元信息以及可能的实体内容。
GET和POST请求的区别在于GET是获取资源的请求,POST是提交资源的请求。
Content-Type: 类型
常见的媒体格式类型如下:
text/html : HTML格式
text/plain :纯文本格式
text/xml : XML格式
image/gif :gif图片格式
image/jpeg :jpg图片格式
image/png:png图片格式
也就是说,格式不同。
HTTP连接是短连接,客户端向服务端发送请求,服务端响应后会立即断掉,且其对应应用层,基于应用级接口使用方便。http适用场景:公司OA服务,互联网服务。
HTTP状态码可分五大类:
100-199 用于指定客户端应相应的某些动作。
200-299 用于表示请求成功。
300-399 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息。
400-499 用于指出客户端的错误。
500-599 用于支持服务器错误。
(5)TCP/IP是传输层协议,主要解决数据如何在网络中传输,而HTTP是应用层协议,主要解决如何包装数据。这个解释就很舒服。
三次握手
在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接。
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
完成三次握手,客户端与服务器开始传送数据
其实就是一次简单的交流:
a:给你个东西,b。
b:好啊
a:东西
(6)Web service是一个平台独立的,松耦合的,自包含的、基于可编程的web的应用程序。太笨重了,不好分离。
7.Spring MVC和Struts的区别是什么,为什么更倾向于使用Spring MVC?
1、Struts2是类级别的拦截, 一个类对应一个request上下文,SpringMVC是方法级别的拦截,一个方法对应一个request上下文,而方法同时又跟一个url对应,所以说从架构本身上SpringMVC就容易实现restful url,而struts2的架构实现起来要费劲,因为Struts2中Action的一个方法可以对应一个url,而其类属性却被所有方法共享,这也就无法用注解或其他方式标识其所属方法了。
2、由上边原因,SpringMVC的方法之间基本上独立的,独享request response数据,请求数据通过参数获取,处理结果通过ModelMap交回给框架,方法之间不共享变量,而Struts2搞的就比较乱,虽然方法之间也是独立的,但其所有Action变量是共享的,这不会影响程序运行,却给我们编码 读程序时带来麻烦,每次来了请求就创建一个Action,一个Action对象对应一个request上下文。
3、由于Struts2需要针对每个request进行封装,把request,session等servlet生命周期的变量封装成一个一个Map,供给每个Action使用,并保证线程安全,所以在原则上,是比较耗费内存的。
4、 拦截器实现机制上,Struts2有以自己的interceptor机制,SpringMVC用的是独立的AOP方式,这样导致Struts2的配置文件量还是比SpringMVC大。
5、SpringMVC的入口是servlet,而Struts2是filter(这里要指出,filter和servlet是不同的。以前认为filter是servlet的一种特殊),这就导致了二者的机制不同,这里就牵涉到servlet和filter的区别了。
6、SpringMVC集成了Ajax,使用非常方便,只需一个注解@ResponseBody就可以实现,然后直接返回响应文本即可,而Struts2拦截器集成了Ajax,在Action中处理时一般必须安装插件或者自己写代码集成进去,使用起来也相对不方便。
7、SpringMVC验证支持JSR303,处理起来相对更加灵活方便,而Struts2验证比较繁琐,感觉太烦乱。
8、Spring MVC和Spring是无缝的。从这个项目的管理和安全上也比Struts2高(当然Struts2也可以通过不同的目录结构和相关配置做到SpringMVC一样的效果,但是需要xml配置的地方不少)。
9、 设计思想上,Struts2更加符合OOP的编程思想, SpringMVC就比较谨慎,在servlet上扩展。
10、SpringMVC开发效率和性能高于Struts2。
8.web.xml里的主要配置都包括什么,都代表什么含义,比如怎么加载Spring 配置的?
<!--spring的配置文件-->
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:spring-mybatis.xml</param-value>
</context-param>
<!--spring监听器-->
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<!--springmvc核心:分发servlet-->
<servlet>
<servlet-name>mvc-dispatcher</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<!--springmvc的配置文件-->
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:spring-mvc.xml</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>mvc-dispatcher</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
9.Annotation和XML两种配置的差别,为什么更喜欢使用Annotaion来配置Spring MVC?
annoation更加简便
10.使用Annotaion的时候需要有哪些配置,他的加载过程是怎么样的?
需要指定对应的controller包 指定包过后 系统会自动去包里寻找对应的类,然后自动注入。
<context:component-scan base-package="com.student.controller"/>
- Filter是基于函数回调的,而Interceptor则是基于Java反射的。
- Filter依赖于Servlet容器,而Interceptor不依赖于Servlet容器。
- Filter对几乎所有的请求起作用,而Interceptor只能对action请求起作用。
- Interceptor可以访问Action的上下文,值栈里的对象,而Filter不能。
- 在action的生命周期里,Interceptor可以被多次调用,而Filter只能在容器初始化时调用一次。
11.什么是Filter,什么是Interceptor,他们的区别是什么,和AOP又是什么关系?
12.生成Json有几种方式,他们之间的好处和坏处分别是什么,为什么推荐使用JsonTaglib来处理Json?
- 母鸡啊
13.一份规范的接口文档应该包括什么内容,衡量接口(API)设计好和坏的准则是什么?
四部分:方法、uri、请求参数、返回参数
14.Http的Header里面包含哪些字段,每个字段都有哪些含义?
>>请求头字段的具体含义
Accept:浏览器可接受的MIME类型。
Accept-Charset:浏览器可接受的字符集。
Accept-Encoding:浏览器能够进行解码的数据编码方式,比如gzip。
Accept-Language:浏览器所希望的语言种类,当服务器能够提供一种以上的语言版本时要用到。
Authorization:授权信息,通常出现在对服务器发送的WWW-Authenticate头的应答中。
Connection:表示是否需要持久连接。如果Servlet看到这里的值为“Keep-Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接),它就可以利用持久连接的优点,当页面包含多个元素时(例如Applet,图片),显著地减少下载所需要的时间。要实现这一点,Servlet需要在应答中发送一个Content-Length头,最简单的实现方法是:先把内容写入ByteArrayOutputStream,然后在正式写出内容之前计算它的大小。
15.Content-type中的数据类型,在Spring MVC中都怎么接收数据?
16.Put请求在Linux下的Tomcat或者是Resin中会收不到数据,怎么解决这个问题,原因是什么?为什么本地使用Jetty的时候往往是正常的?
17.War包是什么,为什么WEB服务通常打出来的都是War包?除了War包,还有几种打包格式,他们之间的区别呢?
JavaSE程序可以打包成Jar包(J其实可以理解为Java了),而JavaWeb程序可以打包成war包(w其实可以理解为Web了)。然后把war发布到Tomcat的webapps目录下,Tomcat会在启动时自动解压war包。
http://blog.csdn.net/u012110719/article/details/44260417
18.maven常用的打包插件有哪些?有什么区别?如何使用 ?
详细介绍:
19.jetty,resin,tomcat的差别在哪里,在线上服务应该选择哪一种WEB服务器?
tomcat:Tomcat服务器是一个免费的开放源代码的Web应用服务器。Tomcat是Apache软件基金会的Jakarta项目中的一个核心项目,由Apache、Sun和其他一些公司及个人共同开发而成。
jetty:是一个开源的servlet容器,它为基于Java的web容器,Jetty是使用Java语言编写的,它的API以一组JAR包的形式发布。开发人员可以将Jetty容器实例化成一个对象,可以迅速为一些独立运行的Java应用提供网络和web连接。
resin:server,对servlet和JSP提供了良好的支持,性能也比较优良,resin自身采用JAVA语言开发。
20.jetty,resin,tomcat的常见配置有哪些,内存,端口,日志文件都怎么配置?
非常简单。。。
21.如果有多个WEB服务,都把WEB服务都配置在一个容器里,还是一个WEB配置一个容器,他们的差别是什么,你觉得哪种方式更好?
一个web配置一个容器,独立出来。
22.在Linux服务器上部署的时候,一般都要有哪些脚本,这些脚本该怎么编写?
我是用的是oneinstack跑的服务。
23.域名和端口号是怎么对应起来的?应该通过域名访问吗,从域名服务商到服务器的流程是怎么样的?
域名是不能直接绑定到端口的,域名是指向一个IP,所有对域名的访问都是要加端口号的.
DNS(Domain Name Server,域名服务器)是进行域名(domain name)和与之相对应的IP地址 (IP address)转换的服务器。DNS中保存了一张域名(domain name)和与之相对应的IP地址 (IP address)的表,以解析消息的域名。
24.Nginx的作用是什么,在WEB服务前端配置Nginx的好处是什么,除了Nginx,还有别的反向代理服务器吗?
Nginx (engine x) 是一个高性能的HTTP和反向代理服务器。
作用:其实就是用来做负载均衡的,把用户请求收集发送给真正的服务器,然后返回给用户,其实用户不知道为自己服务的服务器是哪一个。
25.在Controller里应该怎么处理Service的异常,大段的Try Catch 会有什么坏处?
直接结果会导致程序性能下降。但是为了稳定性及健壮性,有些时候必须要牺牲掉一部分性能。
26.对Service返回的结果是否要判空,为什么?
27.对Service返回的结果是否要打日志,应该打什么样的日志,为什么?
28.该怎么模拟假数据,为什么在真实项目中,我们通常都是先定义接口,再写假数据,再去写业务逻辑?
29.PostMan是什么,为什么要使用他来测试接口,除了Postman,还有哪些工具可以测试?
非常好用的测试接口的工具。Firefox自带的工具也可以
30.在Linux服务器上,有哪些工具是可以测试接口的,怎么用Wget或者是Curl分别发送Rest的四种请求?
31.内网IP和外网IP的区别是什么,在服务器上测试接口是否被防火墙屏蔽的时候,该用内网IP检测,还是该用外网IP检测?
内网IP地址、外网IP地址这个概念并不是固定的,而是相对的。如果用私有IP、公网IP或者局域网IP、互联网IP来理解就容易多了。
32.端口是什么含义,怎么判断一个端口是否被占用了,如何判断一个端口是否被防火墙拦截,怎么用Telnet判断端口号是否打开?
可以通过 netstat -ano 来查看端口的情况
33.WEB服务器通常要配置哪几个端口,如果一台服务器上有多个不同的WEB服务,该怎么规划端口的使用,修真院的端口分配是怎么样的?
这个目前来说还没有完全懂得。自己理解应该是通过不同的端口进行访问。
34.C标签是什么,为什么要使用C标签,有哪些常见的指令?
用于在JSP中显示数据,就像<%= ... > | |
用于保存数据 | |
用于删除数据 | |
用来处理产生错误的异常状况,并且将错误信息储存起来 | |
与我们在一般程序中用的if一样 | |
本身只当做<c:when>和<c:otherwise>的父标签 | |
<c:choose>的子标签,用来判断条件是否成立 | |
<c:choose>的子标签,接在<c:when>标签后,当<c:when>标签判断为false时被执行 | |
检索一个绝对或相对 URL,然后将其内容暴露给页面 | |
基础迭代标签,接受多种集合类型 | |
根据指定的分隔符来分隔内容并迭代输出 | |
用来给包含或重定向的页面传递参数 | |
重定向至一个新的URL. | |
使用可选的查询参数来创造一个URL |
这些深度思考都是复制过来的,有些东西还没涉及到,先慢慢理解这吧。
6.准备准备,开始任务三。
(1)先在服务器上安装配置了tomcat,这个过程非常简单,就不在这里赘述了,教程一搜一大把。
然后设置可执行权限:
chmod +x startup.shchmod +x shutdown.sh完事儿之后试跑了一下,可以正常运行
(2)在服务器安装svn
http://blog.csdn.net/Eric_lmy/article/details/51942931
上面是教程,我照着教程安装成功。

这个图表示安装且启动成功,关闭的话用:killall svnserve。
(3)在服务器安装Resin
这个也比较简单,不赘述。
(4)打包上传到服务器,这个也不难
(5)运行war包,目前卡住了
ping了一下远程服务器,是通的
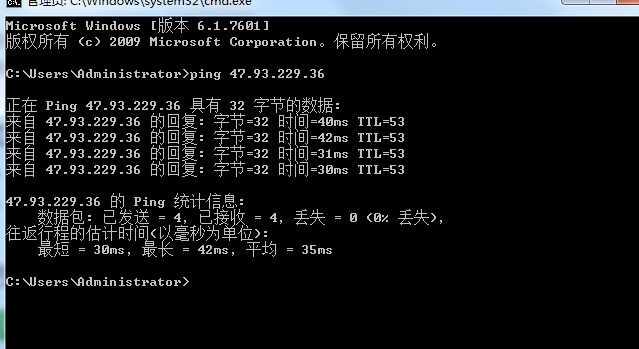
端口开了,ip换了,防火墙也关了,就是不行。只能求助师兄了。。。
喜大普奔,在师兄的一顿敲,终于成功了。上传一下解决方法
然后说一下我打包的步骤:点击生成之后选择build Artifacts,后面就是图示了。亲测成功
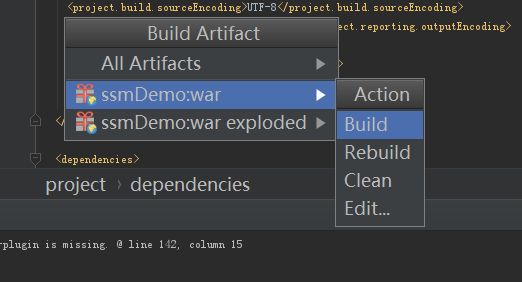
传一下成功的界面吧:
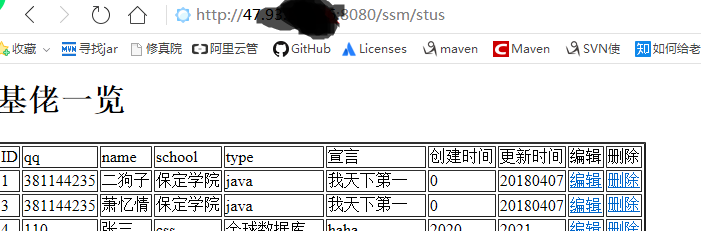
哇,终于成功啦!!!!!!!
至此任务三 1-4 结束。
7.安装nginx
哇,又是吃了一波大亏,教程害人啊!!!!!!!1
换了教程,很轻松地安装了:
只需要在命令行输入 apt-get install nginx 就行了,之前的教程简直日狗,我的妈。费了我少说两个小时给它找错误。
传一下运行nginx之后的效果:

然后是,在本地输入公网ip之后的情况:
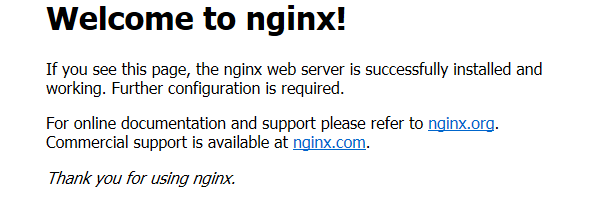
至此安装成功nginx
今天遇到的问题:
嗯。。总的说来没什么太大的问题,除了这个远程web项目本地访问。
今天的收获
打war包,部署到远程服务器,本地通过公网ip访问。
明天计划的事情
推进任务三。




评论