发表于: 2018-01-14 06:10:14
2 691
编辑日报内容...
今天完成的事情:
查看nginx日志
1.1.1 查看日志路径
nginx -V
1.1.2 配置自定义日志格式
日志格式在配置文件中定义,配置文件的位置可以用nginx -t或nginx -V来查找。
自定义需要的关键参数是:
访问端ip地址→已经有了
每次访问的响应延时→ upstream_response_time 参数
多少个不同的ip地址访问→计算出来
在http域下边
将原来日志删除,然后nginx -s reload
1.1.3 日志格式解释:
日志格式log_format
$remote_addr 访问端系统的ip地址,如果访问端用了代理,就是代理服务器的地址
$remote_user 访问端用户名,访问者提供的名字,没记录就是 -
[$time_local] 访问时间,最后+0800表示8时区
$request 请求报文的请求行
$status 这次请求的响应的状态码
$uptream_status:upstream状态,比如成功是200.
$body_bytes_sent 服务端发送给访问端的文件主体内容的大小,可以将日志每条记录中的这个值累加起来以粗略估计服务器吞吐量。
$http_referer 记录从哪个页面链接访问过来的。
$http_user_agent:客户端浏览器信息
$http_x_forwarded_for:客户端的真实ip,
$upstream_addr:upstream的地址,即真正提供服务的主机地址。
$request_time:整个请求的总时间。
$upstream_response_time:请求过程中,upstream的响应时间。
-:空白,用一个"-"占位符替代,历史原因导致还存在。
1.1.4 只记录天访问情况

默认情况下,nginx会把前一天的日志打包。
用shell脚本统计脚本统计访问次数,统计响应延时
1.1 awk命令
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk工作流程是这样的:读入有'\n'换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是"空白键" 或 "[tab]键"
cat <文件路径>| awk '{print $1}' 一种方式
awk '{print $1}' <文件路径> 另外一种方式。
1.2 grep命令
1.3 统计步骤
1、过滤HTTP请求
cat /var/log/nginx/access.log | grep -i "HTTP\/1\.[1|0]"
过滤请求并且把内容覆盖到临时文件
cat /var/log/nginx/access.log | grep -i "HTTP\/1\.[1|0]" > /var/log/nginx/temp.log
2、统计网站访问量,及单个ip的数量
显示所有访问者的ip
awk '{print $1}' /var/log/nginx/access.log | sort | uniq
统计访问者的数量
awk '{print $1}' /var/log/nginx/access.log | sort | uniq | wc -l
(解释 | 代表管道命令将|符号左边的输出值传给右边,'{print $1}':代表要统计的字段位置,/var/log/nginx/access.log 代表文件路径,sort 代表排序,这里没有加后缀让系统按照默认排序方式进行排序,uniq 代表去除重复的行,将唯一的ip筛选出来,wc -l 代表统计出的结果的行数)
把1的写法结合起来,统计某个项目的访问者ip:
cat /var/log/nginx/access.log | grep 'ssmcrud' | awk '{print $1}' | sort | uniq
ssmcrud是项目名称,首先过滤了对项目的访问。
统计响应时间,小于20ms的 这里要用2次awk筛选
awk '{print $26}' /var/log/nginx/access.log | awk '{if($1<0.020&&$1>0)print $1}' | wc -l
统计响应时间,大于20ms的 这里要用2次awk筛选
awk '{print $26}' /var/log/nginx/access.log | awk '{if($1>0.020)print $1}' | wc -l
这是前边师兄的例子,但是有一个问题很严重,就是这么统计出来是不对的。
原因如下:
awk默认用空格来分割字符串,这样分割出来的字符串是不符合要求的。比如下面的
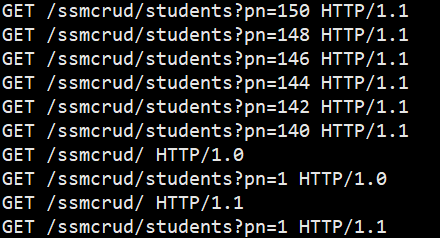
这种本来应该是在一起的,也被分割了,所以如果遇到多个客户端请求,空格数量不一样的情况,统计就会出错。
实验:用手机访问项目,然后用命令统计,就会出现这种情况:

如图:user-agent不一样,导致按空格分割出问题。
解决办法就是先按 " 分割
cat /var/log/nginx/access.log | grep 'ssmcrud'|awk -F'"' '{print $9}'
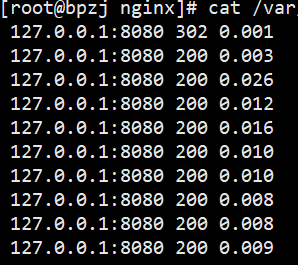
cat /var/log/nginx/access.log | grep 'ssmcrud'|awk -F'"' '{print $2}'
再按空格分割
[root@bpzj nginx]# cat /var/log/nginx/access.log|grep 'ssmcrud'|awk -F'"' '{print $9}'|awk '{if($3>0.020)print $3}'
0.026
0.021
[root@bpzj nginx]# cat /var/log/nginx/access.log | grep 'ssmcrud'|awk -F'"' '{print $9}'|awk '{if($3>0.020)print $3}'|wc -l
2
[root@bpzj nginx]#
注意,awk -F'"' 也可以写成 awk -F\" 这里\代表转义字符。
整理好这些命令
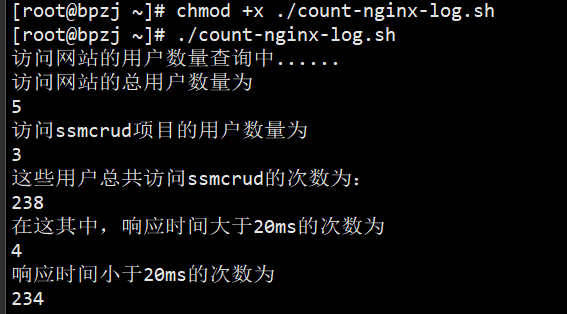
写到脚本conut-nginx-log.sh里
脚本内容:
在服务器执行效果:执行前赋予执行权限 chmod +x <文件名>
使用resin部署
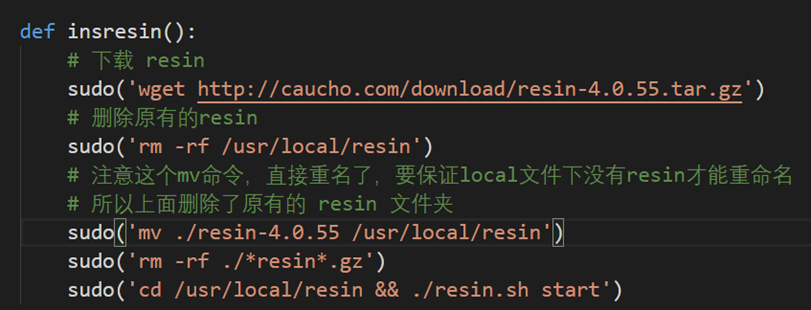
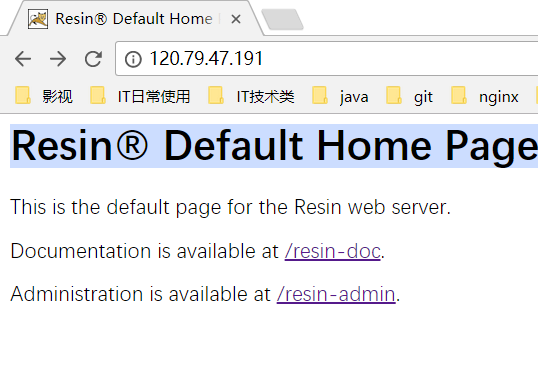
然后
cd /usr/local/tomcat/webapps && mv ./ssmcrud.war /usr/local/resin/webapps/
resin默认就是自动热加载的,也就是即使有项目有改动也不用关闭resin再重启,resin会自动加载新的文件
访问项目,成功。
明天计划的事情:
resin日志。spring aop,提交任务3。学习任务4。
遇到的问题:
awk按空格分割,导致不同如果空格数量不同,统计出错
解决方法:继续使用awk,先用"分割,再用空格分割。
对awk、grep、nginx命令不熟的话,还要去网上查
一个比较通用的解决办法就是 <命令> --help或者<命令> -h
例如:nginx -h,awk --help直接看帮助,英语能看懂的话,就很方便了。
注意help前边是两个-,h前边是一个-。
收获:
shell脚本,awk,grep命令。




评论