发表于: 2018-01-12 22:25:43
1 602
今日完成的事情:
1,看完《SQL必知必会》
2,完成大部分《SQL必知必会》笔记
8 函数
常用文本处理函数
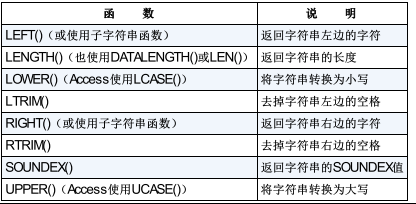
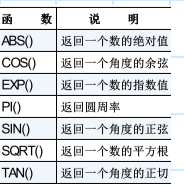
数值处理函数
举例:SELECT name,UPPER(name) AS name_upcase
FROM student ORDER BY name;
体会:函数简单,使用时大写,基本可以用在SQL各部分
9汇总数据:用聚集函数来汇总数据
常用聚集函数
其中COUNT使用时有两点需要注意:
使用COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值。
使用COUNT(column)对特定列中具有值的行进行计数,忽略NULL值。
举例:
SELECT COUNT(*) AS num_student,
MIN(age) AS age_min,
MAX(age) AS age_max,
AVG(age) AS age_avg
FROM student;
ALL与DISTINCT,其中ALL参数为默认,如果不指定DISTINCT,则假定为ALL;而在计算时使用默认参数ALL可能会影响结果,如对于AVG()
举例:SELECT AVG(DISTINCT age) AS age_avg FROM student WHERE class_num=20140111;
注意:如果指定列名,则DISTINCT只能用于COUNT()。DISTINCT不能用于COUNT(*)。类似地,DISTINCT必须使用列名,不能用于计算或表达式。
10 分组数据--GROUP BY 与 HAVING
数据分组--GROUP BY
规定:
a,GROUP BY子句可以包含任意数目的列,因而可以对分组进行嵌套,更细致地进行数据分组。
b,如果在GROUP BY子句中嵌套了分组,数据将在最后指定的分组上进行汇总。换句话说,在建立分组时,指定 的所有列都一起计算(所以不 能从个别的列取回数据)。
c, GROUP BY子句中列出的每一列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUP BY子 句中指定相同的表达式。不能使用别名。
d, 大多数SQL实现不允许GROUP BY列带有长度可变的数据类型(如文本或备注型字段)。
e,除聚集计算语句外,SELECT语句中的每一列都必须在GROUP BY子句中给出。
f, 如果分组列中包含具有NULL值的行,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
g,GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
h,GROUP BY 2, 1可表示按选择的第二个列分组,然后再按第一个列分 组
举例:
SLECT stendent_id,COUNT(*) AS num_stu
FROM student
GROUP BY age;
一般在使用GROUP BY子句时,应该也给出ORDER BY子句。这是保证数据正确排序的唯一方法。千万不要仅依赖GROUP BY排序数据。
过滤分组--HAVING (类似于 WHERE)
举例:
SLECT stendent_id,COUNT(*) AS num_stu
FROM student
GROUP BY age
WHERE age > 16;
HAVING和WHERE的差别:WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤;WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤
11 子查询(我更喜欢称之为嵌套查询,像复合句一样,多个定语一般)
举例:
SELECT cust_id FROM Orders
WHERE orders
WHERE order_num IN (SELECT order_num FROM OrderItems Where prod_id = 'wahaha');
在SELECT语句中,子查询总是从内向外处理。
作为计算字段使用子查询;
SELECT cust_name, cust_state, (SELECT COUNT(*) FROM Orders WHERE Orders.cust_id = Customers.cust_id) AS orders
FROM Customers
ORDER BY cust_name;
用一个句点分隔表名和列名,这种语法必须在有可能混淆列名时使用
12 联结表:联结是一种机制,用来在一条SELECT语句中关联表,因此称为联结。
关系表:关系表的设计就是要把信息分解成多个表,一类数据一个表,各 表通过某些共同的值互相关联
创建联结:
SELECT vend_name, prod_name, prod_price
FROM Vendors, Products //有两个表,而不是一个表了
WHERE Vendors.vend_id = Products.vend_id;//一定要用WHERE过滤,在联结两个表时,实际要做的是将第一 个表中的每一行与第二个表中的每一行配对。WHERE子句作为过滤条件,只包含那些匹配给定条件(这里是联结条件)的行。没有WHERE子句, 第一个表中的每一行将与第二个表中的每一行配对,而不管它们逻辑上是否能配在一起,从而得到笛卡尔积(由没有联结条件的表关系返回的结果为笛卡儿积。检索出的行的数目将是第一个表中的行数乘以第二个表中的行数。)
内联结(等值联结)
SELECT Customers.cust_id, Orders.order_num
FROM Customers INNER JOIN Orders ON Customers.cust_id = Orders.cust_id;
叉联结:笛卡尔联结
自联结:自己联结自己
SELECT c1.cust_id, c1.cust_name, c1.cust_contact
FROM Customers AS c1, Customers AS c2 //同一个表
WHERE c1.cust_name = c2.cust_name AND c2.cust_contact = 'Jim Jones';
自联结通常作为外部语句,用来替代从相同表中检索数据的使用子查询语句
自然联结;自然联结排除多次出现,使每一列只返回一次
外联结:联结包含了那些在相关表中没有关联行的行。这种联结称为外联结。
SELECT Customers.cust_id, Orders.order_num
FROM Customers LEFT OUTER JOIN Orders ON Customers.cust_id = Orders.cust_id;
在使用OUTER JOIN语法时,必须使用RIGHT或LEFT或FULL关键字指定包括其所有行的表(RIGHT指 出的是OUTER JOIN右边的表,而LEFT指出的是OUTER JOIN左边的表)。上面的例子使用LEFT OUTER JOIN从FROM子句左边的表(Customers表) 中选择所有行。为了从右边的表中选择所有行,需要使用RIGHT OUTER JOIN
联结时三个表需要2各联结条件,其余的为过滤条件(都在WHERE后);联结的表越多,性能下降越厉害
13 创建高级联结
表别名
举例:
SELECT cust_name, cust_contact
FROM Customers AS C, Orders AS O, OrderItems AS OI
WHERE C.cust_id = O.cust_id AND OI.order_num = O.order_num AND prod_id = 'RGAN01';
使用表别名的一个主要原因是能在一条SELECT语句中不止一次引用相同的表。
14 组合查询--UNION
多数情况下,组合相同表的两个查询所完成的工作与具有多个WHERE子句条件的一个查询所完成的工作相同
举例:
SELECT cust_name, cust_contact, cust_email
FROM Customers WHERE cust_state IN ('IL','IN','MI')
UNION SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_name = 'Fun4All';
UNIOIN规则:
UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔(因此,如果组合四条SELECT语句,将要使用三个UNION关 键字)。
UNION中的每个查询必须包含相同的列、表达式或聚集函数(注意可以是不同的表,不过,各个列不需要以相同的次序列出)。
列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以隐含转换的类型
UNION从查询结果集中自动去除了重复的行,如果想返回所有的匹配行,可使用UNION ALL而不是UNION
用UNION组合查询时,只能使用一条ORDER BY子句,它必须位于最后一条SELECT语句之后。对于结果 集,不存在用一种方式排序一部分,而又用另一种方式排序另一部分的情况,因此不允许使用多条ORDER BY子句。
15 插入数据
INSERT INTO table_name VALUES(每个列的值)
INSERT INTO table_name(需要的列)VALUES(对应列的值)
插入检索出来的数据
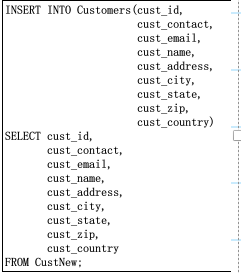
INSERT通常只插入一行。要插入多行,必须执行多个INSERT语句。INSERT SELECT是个例外,它可以用一条INSERT插入多行,不管SELECT语 句返回多少行,都将被INSERT插入
INSERT SELECT与SELECT INTO:前者导出数据,而后者导入数据
SELECT * INTO CustCopy FROM Customers;
16 更新和删除数据--UPDATE DELETE DROP
UPDATE :更新表中的特定行; 更新表中的所有行
UPDATE Customers
SET cust_contact = 'Sam Roberts', cust_email = 'sam@toyland.com'
WHERE cust_id = '1000000006';
DELETE:从表中删除特定的行; 从表中删除所有行。
DELETE FROM Customers WHERE cust_id = '1000000006';
使用外键确保引用完整性的一个好处是,DBMS通常可以 防止删除某个关系需要用到的行。
DELETE不需要列名或通配符。DELETE删除整行而不是删除列。要删除指定的列,请使用UPDATE语句。
使用UPDATE或DELETE的原则
除非确实打算更新和删除每一行,否则绝对不要使用不带WHERE子句的UPDATE或DELETE语句。
保证每个表都有主键,尽可能像WHERE子句那样使用它(可以指定各主键、多个值或值的范围)。
在UPDATE或DELETE语句使用WHERE子句前,应该先用SELECT进行测试,保证它过滤的是正确的记录,以防编写的WHERE子句不正确。
使用强制实施引用完整性的数据库,这样DBMS将不允许删除其数据与其他表相关联的行。
有的DBMS允许数据库管理员施加约束,防止执行不带WHERE子句的UPDATE或DELETE语句。如果所采用的DBMS支持这个特性,应该使用 它。
17 创建和操纵表
创建表 CREATE TABLE
明日计划的事情:
1,完成剩下的笔记
2,继续JAVA基础的学习
3,完成任务一关于MAVEN的学习
遇到的问题:
无
收获:
1,对于SQL有了比较全的基础认识
2,好记性不如烂笔头,需要多次记忆,虽然SQL语法简单




评论