发表于: 2018-01-11 21:32:46
1 681
今日完成
1.memecache
(1)在本地先测试一下,安装一个windows 版。
首先需要下载一个memcached for Windows的软件,解压后只有一个memcached.exe文件
然后进入cmd命令行,cd到文件路径下
使用命令
memcached.exe -d install
memcached.exe -d start
注意,使用这两个命令后,什么都不会发生,命令行没有任何提示,但是如果你再输入一遍上面的两个命令,会提示已安装和已启动等,证明安装成功了。
(2)连接
然后输入Telnet "your's ip" 11211(memcached默认端口)
进入一个空白界面,然后输入Ctrl+],就可以直观的使用Memcache了,还是不知道怎么使用。
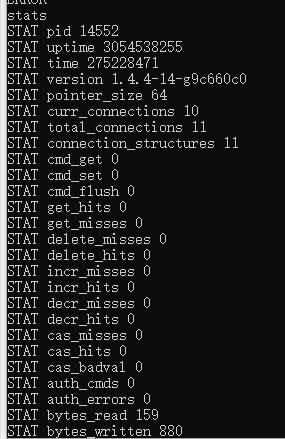
(3)使用xmemecache,Java环境下使用memecache。先导入一个jar包。
<dependency>
<groupId>com.googlecode.xmemcached</groupId>
<artifactId>xmemcached</artifactId>
<version>2.0.0</version>
</dependency>
再介绍一下memecache。
Memcache是一个高性能的分布式的内存对象缓存系统,通过在内存里维护一个统一的巨大的hash表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。简单的说就是将数据调用到内存中,然后从内存中读取,从而大大提高读取速度。
Memcache是danga的一个项目,最早是LiveJournal 服务的,最初为了加速 LiveJournal 访问速度而开发的,后来被很多大型的网站采用。
Memcached是以守护程序方式运行于一个或多个服务器中,随时会接收客户端的连接和操作
(4)整合spring与memecache
<!--配置memcache-->
<bean id="memcachedClientBuilder" class="net.rubyeye.xmemcached.XMemcachedClientBuilder">
<!--Xmemcached是基于java nio的client实现,默认对一个memcached节点只有一个连接-->
<property name="connectionPoolSize" value="1"/>
<!--ailure模式是指,当一个memcached节点down掉的时候,发往这个节点的请求将直接失败,而不是发送给下一个有效的memcached节点-->
<property name="failureMode" value="true"/>
<!-- XMemcachedClientBuilder have two arguments.First is server list,and
second is weights array. -->
<constructor-arg>
<list>
<bean class="java.net.InetSocketAddress">
<constructor-arg>
<value>127.0.0.1</value>
</constructor-arg>
<constructor-arg>
<value>11211</value>
</constructor-arg>
</bean>
</list>
</constructor-arg>
<!--配置权重比-->
<!--<constructor-arg>-->
<!--<list>-->
<!--<value>${memcached.server1.weight}</value>-->
<!--<value>${memcached.server2.weight}</value>-->
<!--<value>${memcached.server3.weight}</value>-->
<!--<value>${memcached.server4.weight}</value>-->
<!--</list>-->
<!--</constructor-arg>-->
<property name="connectTimeout" value="3000"/>
<property name="commandFactory">
<bean class="net.rubyeye.xmemcached.command.TextCommandFactory"/>
</property>
<property name="sessionLocator">
<bean class="net.rubyeye.xmemcached.impl.KetamaMemcachedSessionLocator"/>
</property>
<property name="transcoder">
<bean class="net.rubyeye.xmemcached.transcoders.SerializingTranscoder"/>
</property>
</bean>
<!-- Use factory bean to build memcached client -->
<bean id="memcachedClient" factory-bean="memcachedClientBuilder"
factory-method="build"
destroy-method="shutdown"/>
(5)整理以前的增删改查的逻辑,先去缓存里面查找,如果没有,再去数据库查找。——比如这个学生列表
public List<StudentCustom> findStudentList(StudentQueryVo studentQueryVo) {
// TODO Auto-generated method stub
try {
//在缓存里面查找studentlist
List<StudentCustom> studentlist1 = memcachedClient.get("studentlist");
//如果studentlist1为空,那么去数据库里面查询。
if (null == studentlist1) {
List<StudentCustom> studentlist2 = studentMapperCustom.findStudentList(studentQueryVo);
//将查询出来的结果,放入缓存中。
memcachedClient.set("studentlist",3000,studentlist2);
return studentlist2;
}
return studentlist1;
} catch (TimeoutException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (MemcachedException e) {
e.printStackTrace();
}
return null;
}
测试对比一下时间差。缓存很厉害
2.使用mybatis整合memecache。
(1)jar包
<!--mybatis整合memecache-->
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-memcached</artifactId>
<version>1.0.0</version>
</dependency>
(2)在mapper文件中添加
<mapper namespace="lujing.mapper.CustomProfessionInfoMapper">
<cache type="org.mybatis.caches.memcached.MemcachedCache">
<property name="org.mybatis.caches.memcached.servers" value="localhost:11211"/>
(3)配置
官方api:
| Property | Default | Description |
| org.mybatis.caches.memcached.keyprefix | _mybatis_ | 缓存key的前缀 |
| org.mybatis.caches.memcached.servers | localhost:11211 | memcache地址 |
| org.mybatis.caches.memcached.connectionfactory | net.spy.memcached.DefaultConnectionFactory | 只要实现接口net.spy.memcached.ConnectionFactory |
| org.mybatis.caches.memcached.expiration | 2592000(30天的秒数) | 过期时间单位秒 |
| org.mybatis.caches.memcached.asyncget | false | 是否启用异步读 |
| org.mybatis.caches.memcached.timeout | 5 | 使用异步读的timeout时间 |
| org.mybatis.caches.memcached.timeoutunit | java.util.concurrent.TimeUnit.SECONDS | 使用异步读的timeout时间单位 |
| org.mybatis.caches.memcached.compression | false | 如果开启,对象在放到memcache前会使用GZIP 压缩 |
mybatis下就可应用memcache缓存,默认mapper下的所有语句都缓存。
备注:
<1>.对于不需要缓存的添加useCache=”false”,例如:
<select id="getAllUser" parameterType="PageParameter" resultType="User" useCache="false"> select * from user ORDER BY user_id*1 ASC
</select> - 1
- 2
- 3
<2>对于某条语句的执行触发缓存flushCache=”true” :
<delete id="deleteUser" parameterType="User" flushCache="true" > delete from user where user_id=#{user_id}</delete >(4)总结
对查询频率高,变化频率低的数据建议使用二级缓存。
对于访问多的查询请求且用户对查询结果实时性要求不高,此时可采用mybatis二级缓存技术降低数据库访问量,提高访问速度,业务场景比如:耗时较高的统计分析sql、电话账单查询sql等。
实现方法如下:通过设置刷新间隔时间,由mybatis每隔一段时间自动清空缓存,根据数据变化频率设置缓存刷新间隔flushInterval,比如设置为30分钟、60分钟、24小时等,根据需求而定。
3.再使用jmeter测试,在使用memecache前后,压力测试的差异。
(1)新建一个测试计划。
(2)服务器蹦了,明天再测试一下。
遇到问题
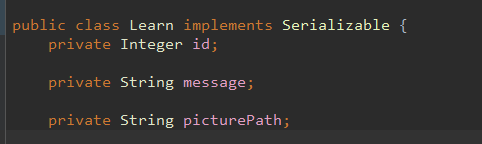
1.报错,提示对象未序列化。

解决:将储存的对象实现Serializable接口即可。
明日计划
1.学习json数据,回传json数据
2.学习redis,继续进行压力测试。
收获
1.学会了memecache的使用与配置,学会了mybatis整合memecache。




评论