发表于: 2018-01-07 18:42:40
3 447
■今天完成的事情:
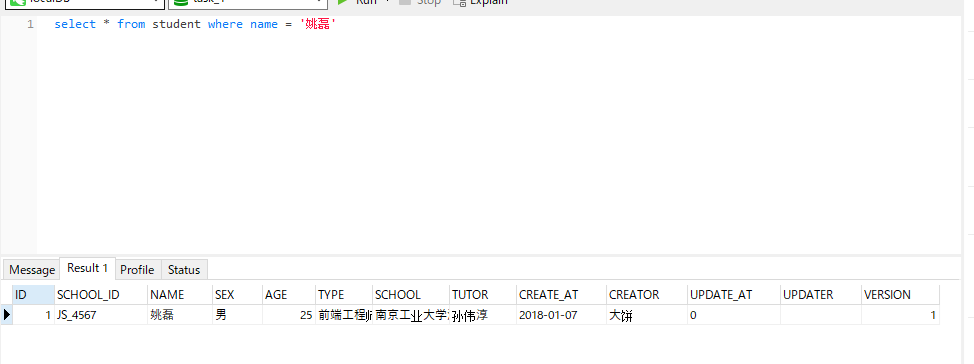
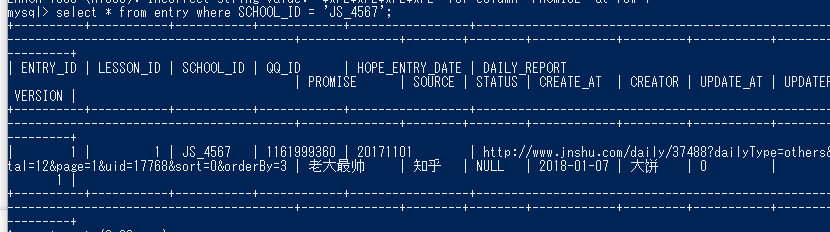
6.从报名贴中找一条最近报名的师弟,用Mysql插入这条数据,并能够根据姓名查出来这条记录 6.1 我把step 4设计好的model,自动转成了create用的sql,生成了表格
6.2 然后我去插入数据 用的sql如下 insert into TRAINING_TYPE (SCHOOL_ID,TITLE,BODY,CREATOR,UPDATE_AT,UPDATER,VERSION) values ('前端工程师', curdate(), '大饼', 0, '', VERSION + 1) insert into LESSON (LESSON_NAME,LESSON_TYPE,START_DATE,SEMESTER,CREATE_AT,CREATOR,UPDATE_AT,UPDATER,VERSION) values ('线下学员招募', '线下', 20180102, 5, curdate(), '大饼', 0, '', VERSION + 1) insert into ENTRY (LESSON_ID,SCHOOL_ID,QQ_ID,HOPE_ENTRY_DATE, PROMISE, DAILY_REPORT, SOURCE, CREATE_AT,CREATOR,UPDATE_AT,UPDATER,VERSION) values (1, 'JS_4567', '1161999360', 20171101, '11', '', '', curdate(), '大饼', 0, '', VERSION + 1); insert into STUDENT (SCHOOL_ID,NAME,SEX,AGE,TYPE,SCHOOL,TUTOR,CREATE_AT,CREATOR,UPDATE_AT,UPDATER,VERSION) values ('JS_4567', '姚磊', '男', 25, '前端工程师', '南京工业大学浦江学院', '孙伟淳', curdate(), '大饼', 0, '', VERSION + 1); insert into ENTRY (LESSON_ID,SCHOOL_ID,QQ_ID,HOPE_ENTRY_DATE, DAILY_REPORT, PROMISE, CREATE_AT,CREATOR,UPDATE_AT,UPDATER,VERSION) values (1, 'JS_4567', '1161999360', 20171101, 'aaa', 'bbb', curdate(), 'aa', 0, '', VERSION + 1); 6.3 然后通过名字找到了数据
| |
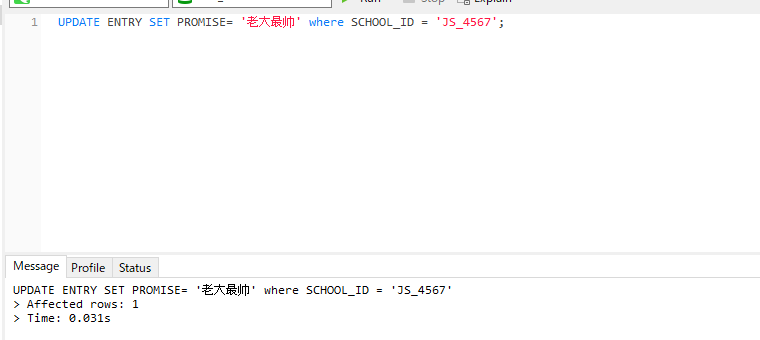
7.分别用Navciat和Sql语句去将本条数据记录的报名宣言改成老大最帅
| |
8.将表导出成Sql文件,并使用navciat和Sql分别尝试删除此条数据,并用之前备份的Sql恢复。 8.1 导出的文件
8.2删除数据 8.3恢复数据 | |
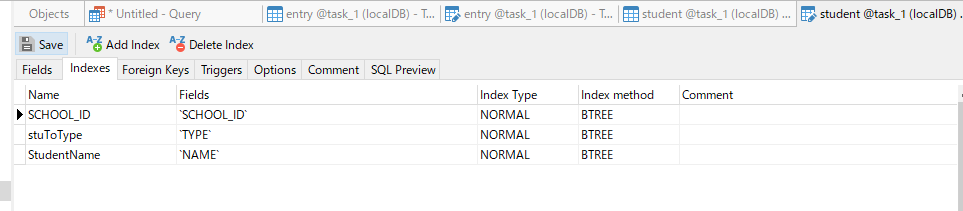
9.给姓名建索引,思考一下还应该给哪些数据建索引
就是经常搜索的东西,比如QQID,学号等 | |
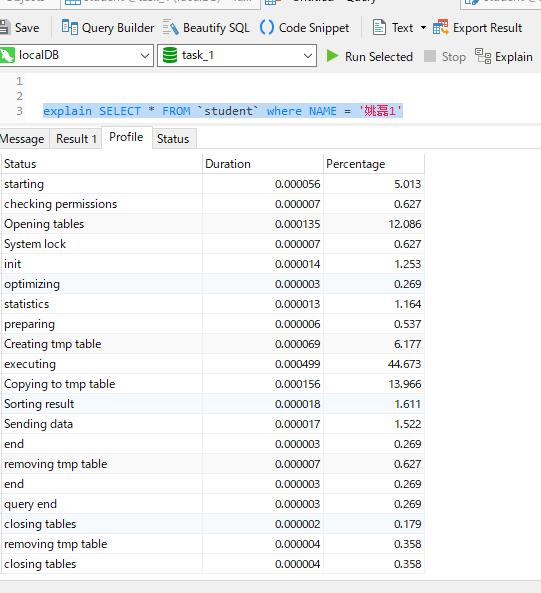
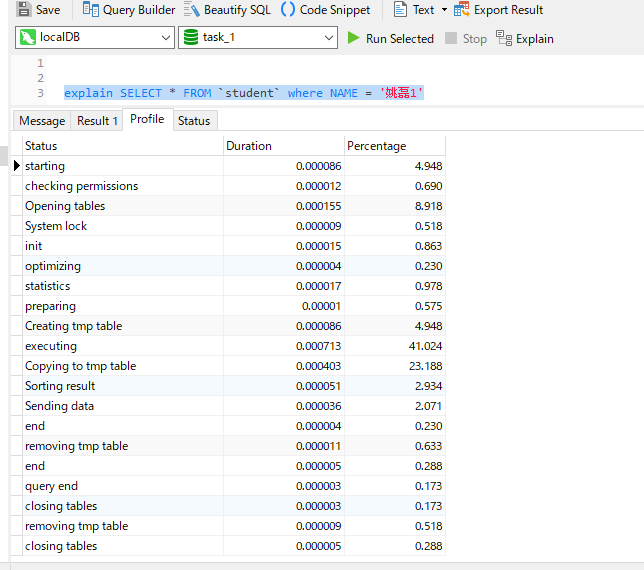
10.插入10条数据,查看有索引和无索引的情况下,Sql语句执行的效率 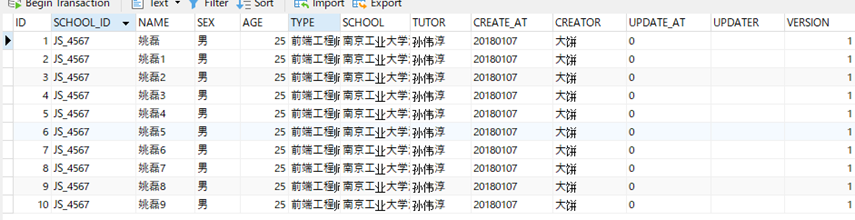 10.2 我比较了一下有无索引的差别,感觉数据量比较小,没什么区别2 有index的
无index的
| |
11.查看深度思考中Mysql相关的一些问题,将自己思考的结果写在日报中,并查阅之前师兄的日报,看看是否有合自己思路接近或者是完全不一致的地方。 5.为什么DB的设计中要使用Long来替换掉Date类型? 我以前遇到的项目里也都是这样规定的,没有仔细思考过,我猜测是方便加加减减 我搜到别的日报里是这么说的,我觉得有道理,以下为引用 用bigint来替换date的好处是:date会受到时区的限制,并且有时候不需要获取当时的时间。 格式也会受到限制。Bigint对时间差的处理更加方便。date类型只在MySQL中有意义,在java中并没有这种格式 6.自增ID有什么坏处?什么样的场景下不使用自增ID? 增加以后,再删除,就会缺少号码 这个ID本身数值是有意义的,比如第一和第二位表示地区,第三四位表示省市什么的,就不应当用 还有这个ID不是数字的时候,含有字母的时候,就不能用 我搜到的别的日报里还提到,数据需要经常修改时不使用,我觉得也有道理。 7.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引? DB索引就是给每一条数据建立一个目录,这样要找那个数据的时候,直接用索引去找 多大的数据量下建索引会有性能的差别,这个不太知道。我想还是要具体问题,具体分析,在实际业务上发现慢的sql,然后去不断优化 经常搜索的字段应该建立索引 8.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。 唯一索引,那个索引的字段不能重复,参照别人的日报里,引用如下 区别:唯一索引下的字段值不能重复,但可以为空;普通索引不存在这种限制 在某个字段有这样的需求,可以为空但必须唯一,这时候适合建唯一索引 9.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了? 我直觉上是觉得需要,我搜索的结果告诉我, 唯一索引在数据库表结构中对字段添加唯一索引后进行数据库进行存储操作时, 数据库会判断库中是否已经存在此数据,不存在此数据时才能进行插入操作。 所以如果不去判断的话,我觉得会被数据库拒绝 10.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口? 初次创建时,createAt要赋值时间 更新的时候,createAt不变,updateAt要改变 不应该,不然被篡改了怎么办 11.修真类型应该是直接存储Varchar,还是应该存储int? 应该是int,然后另外做一个表,把int数值对应的修真类型的名字写上去。 修真名字可能散布在非常多的其他表,应该集中在一张表去管理这些以后可能变化的常量值。不然以后修真名字改了,岂不是要改很多个表。
12.varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么? 长度的话,我在写作业的时候是比较随意的,实际业务上还是要考虑,这个字段可能会发生的最大长度吧,同时也要在数据库支持的长度范围内 varchar规定的是字数,text和longText都是byte 基本上我觉得应该用varchar,数据特别打的时候用text 13.怎么进行分页数据的查询,如何判断是否有下一页? 分页数据的查询,我不是很知道什么意思,现在任务里没有出现。 我在实际业务中,是先把符合条件的数据全都选出来,然后根据取得的行数来判断有几页 下面这个博客比较有用,我可以在实际遇到问题的时候去参考一下 https://blog.jamespan.me/2015/01/22/trick-of-paging-query 14.为什么不可以用Select * from table? 这样query时间会非常大,并且很可能无法显示全部结果 同理,delete from table也绝对不能用 |


■明天计划的事情:
| 12.下载Java 7,并配置环境变量,百度搜索一下JDK和JRE的区别,并将结论用自己的话写在日报中。 |
| 13.下载Maven3,并配置好环境变量。 |
■遇到的问题:
1.插入中文的时候,遇到以下错误
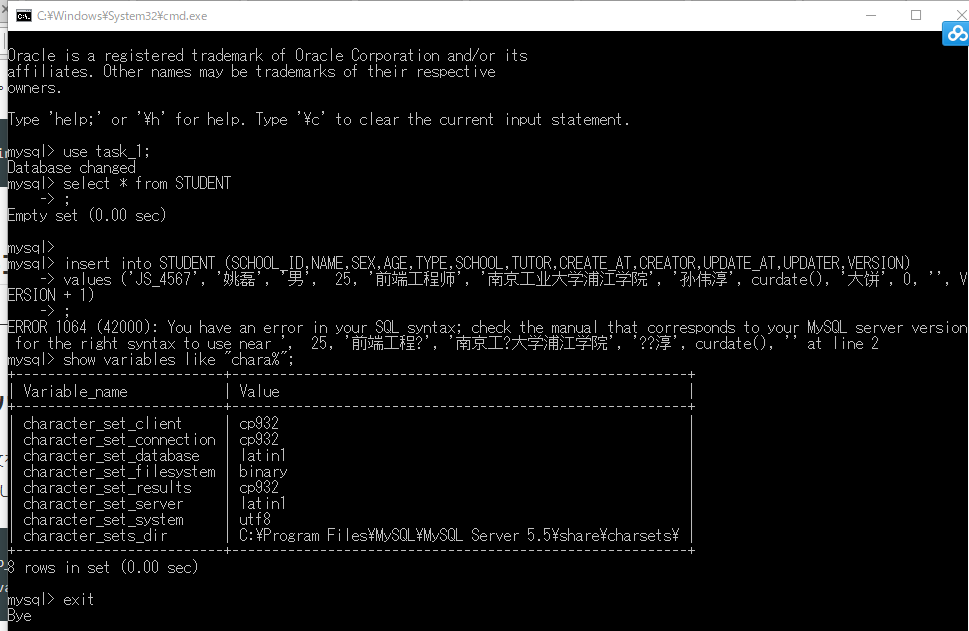
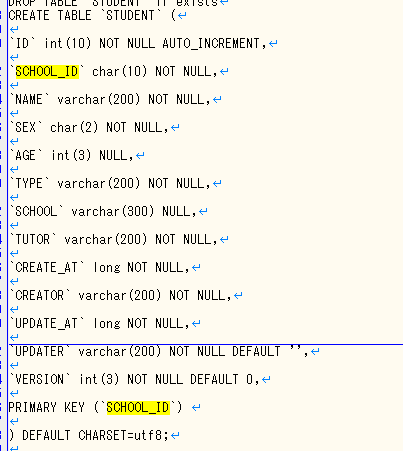
我用以下方式重新写了create语句,加了utf-8就可以插入了
2.在命令行不能插入,但是在navicat可以

是因为我的命令行也不是utf8格式的,设置成utf8以后就能正常插入了
3.在回答深入思考问题的时候,有挺多网上也没有说清楚,
日报上也没有一个正确的回答,感到有点困惑,只能说实际遇到问题的时候,多思考多关注了
■收获:
1.文字编码是一个大坑
2.数据库方面博大精深,每一个深入思考都可以引出很多值得思考的问题




评论