发表于: 2017-12-27 23:22:47
2 737
今天完成的事情:
配置连接池
连接池的作用:减少频繁的数据库连接、关闭,降低资源消耗
http://blog.csdn.net/fysuccess/article/details/66972554
分别配置了jdbc无连接池、C3p0、Tomcat Jdbc Pool、DBCP、Druid 五种配置

详细配置就不贴了。
经过简单的测试:
JDBC(没用连接池) 593ms、576ms、607ms、599ms、593ms
C3p0 496ms、635ms、590ms、618ms、596ms
Tomcat Jdbc Pool 841ms、743ms、683ms、655ms、634ms
DBCP 628ms、734ms、598ms、841ms、800ms
Druid 144ms、155ms、142ms、154ms、174ms
因为测试的数据操作 简单,只能作为参考,但无疑,druid是性能最高的。
从网上看到,用的最多的就是两种C3p0、Druid。
小项目随意,大项目应该选Druid
| C3p0 | DBCP | Tomcat Jdbc Pool | BoneCP | Druid |
线程 | 单线程 | 单线程 | 多线程、异步 | 多线程、异步 | 多线程、异步 |
开源顶目集成 | Spring、 Hibernate | Tomcat组件 | Tomcat7 以后 | Hibernate、 DataNucleus | Druid |
PSCache | 支持 | 支持 | 支持 | 支持 | 支持 |
LRU性能关键指标 | 否 | 是 | ? | 否 | 是 |
ExceptionSorter | 否 | 否 | 否 | 否 | 是 |
监控 | Jmx、Log | Jmx | Jmx | Jmx | Jmx、Log、Http |
可扩展性 | 差 | 差 | 差 | 较好 | 好 |
连接池管理 | 队列 | LinkedBlockingD eque,FIFO 队列、 FILO堆栈 | FairBlockingQueue | 堆栈 | 数组、 CopyOnWriteArra yList(COW) |
Tomcat数据源、 | 数据源和JNDI绑定,支持 JDBC3规范和 JDBC2的标准扩展 | 支持JNDI配置,需要加入jconn3.jar | 支持JNDI配置,tomcat的 1个模块 | 支持JNDI配置,稍复杂 com.jolbox.bonecp.BoneCPDataSource | 支持jNDI配置 com.alibaba.drui d.pool.DruidData SourceFactory |
代码复杂度 | 复杂 | 中等,超过60个类,600KB | 简单,8个核心类 | 简单,40KB | 中等 |
更新维护 | 否 | 否 | 是 | 否 | 是 |
决定使用Druid配置连接池,下面是配置:
这个切换也比较方便
<!--Spring Druid 数据源配置-->
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<!-- 基本属性 url、user、password -->
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
<!-- 配置初始化大小、最小、最大 -->
<property name="initialSize" value="5" />
<property name="minIdle" value="1" />
<property name="maxActive" value="20" />
<!-- 配置获取连接等待超时的时间 -->
<property name="maxWait" value="60000" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="300000" />
<!-- 打开PSCache,并且指定每个连接上PSCache的大小 -->
<property name="poolPreparedStatements" value="true" />
<property name="maxPoolPreparedStatementPerConnectionSize" value="20" />
<!-- 配置监控统计拦截的filters,去掉后监控界面sql无法统计 -->
<property name="filters" value="stat" />
</bean>
把测试方法写到main()
先写一个基类,初始化spring容器,获得mapper bean
再写测试的实现
多写了两个sql查询语句。
//获取
Student getByName(String name);
Student getById(int id);
//分组查询
// @Select("SELECT * FROM student LIMIT #{start},#{count}")
List<Student> listGroup(@Param("start") int start,@Param("count") int count);
主要代码:
springmybatisdruid\src\main\java\com\bpzj\task1\test\MapperBean.java
package com.bpzj.task1.test;
import com.bpzj.task1.dao.StudentMapper;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class MapperBean {
// 实例化容器
ApplicationContext ctx = new ClassPathXmlApplicationContext("bean-druid.xml");
// 获取mapper bean
StudentMapper studentMapper = (StudentMapper) ctx.getBean("studentMapper");
public StudentMapper getStudentMapper() {
return studentMapper;
}
}
springmybatisdruid\src\main\java\com\bpzj\task1\test\Task1Test.java
public class Task1Test {
static MapperBean mapperBean = new MapperBean();
public static Student newStudent() {
Student student= new Student(1,"曲艳行","3169119846",
1,"11月18日-22日","燕山大学",
"2641","http://www.jnshu.com/occupation/5/daily",
"新年好","郑州分院-王鹏举","知乎");
return student;
}
public static void add() {
Student student1 = newStudent();
student1.setId(1);
boolean a= mapperBean.getStudentMapper().insert(student1);
if (a) {
System.out.println("insert success");
} else {
System.out.println("insert failure");
}
}
public static void delete() {
boolean a= mapperBean.getStudentMapper().deleteById(1);
if (a) {
System.out.println("delete success");
} else {
System.out.println("delete failure");
}
}
public static void listAll() {
List<Student> students = mapperBean.getStudentMapper().listAll();
for (Student student : students) {
System.out.println(student);
}
}
public static void listGroup(int start, int count) {
List<Student> students = mapperBean.getStudentMapper().listGroup(start, count);
for (Student student : students) {
System.out.println(student);
}
}
public static void update() {
Student student = newStudent();
student.setId(1);
student.setOath("老大最帅");
boolean a= mapperBean.getStudentMapper().updateById(student);
if (a) {
System.out.println("update success");
} else {
System.out.println("update failure");
}
}
// 根据姓名查询
public static void getByName() {
Student student = mapperBean.getStudentMapper().getByName("曲艳行");
System.out.println(student);
}
public static Student getById(int id) {
Student student = mapperBean.getStudentMapper().getById(id);
// System.out.println(student);
return student;
}
public static void main(String[] args) {
System.out.println("查询所有学生:");
listAll();
System.out.println("\n删除id=1的学生:");
delete();
System.out.println("选取前两个学生验证删除成功:");
listGroup(0,2);
System.out.println("\n新建学生,插入id=1这一列:");
add();
System.out.println("选取前两个学生验证插入成功:");
listGroup(0,2);
System.out.println("\n更新id=1的宣言");
update();
System.out.println("检查更新是否成功");
int id =1;
Student student = getById(id);
System.out.println("Student [id=" + id + " 宣言=" + student.getOath() + "]");
}
}
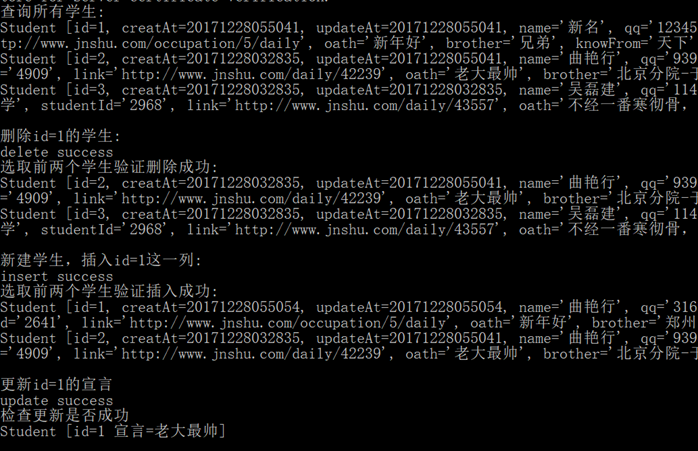
测试结果:

打包成jar文件,执行main方法
http://blog.csdn.net/xiao__gui/article/details/47341385
上传到服务器,执行main结果:
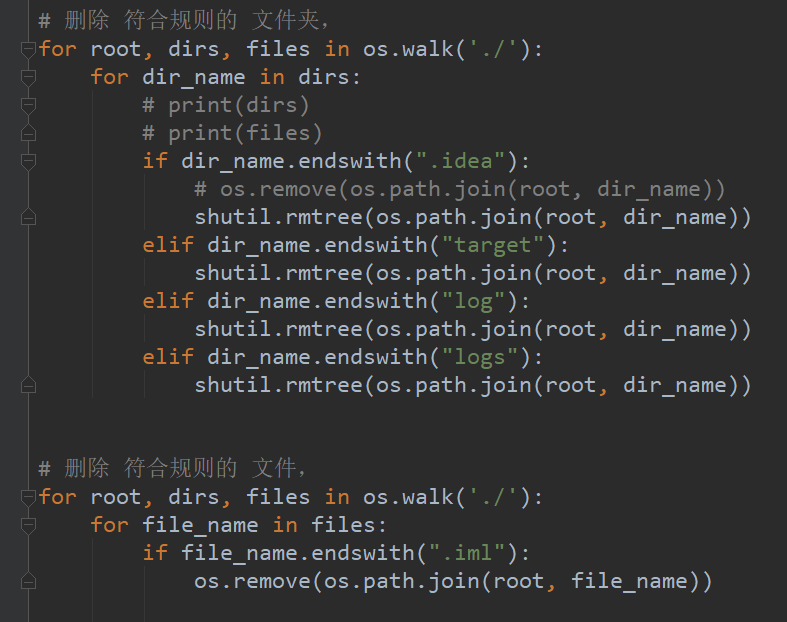
每次上传到github都要删些文件,写了一个python脚本:
https://github.com/bpzj/Study/tree/master/Java/Easy
明天计划的事情:
完成任务1,总结下。
遇到的问题:
1、spring 容器初始化、获取mapper bean的问题
在main方法中,因为不在test文件夹下,直接使用单元测试的注解,会出现空指针错误。
只要把 语句放到main函数下,就报空指针
一直调试,就是取不到mapper,最后,改用原来的方法。
想起以前写jdbcTemplate的时候,写过一个基类,从基类扩展,这个倒不用写基类,但效果差不多。时间都浪费在想通过那两个注解进行spring容器的创建、mapper bean的获取。浪费了大概5、6个小时。
最后想通了,先不管这些,自己实现也很简单。不能在这上面浪费时间
2、接口里重载方法,在mybatis中,用xml文件写sql时,在sql语句中造成id一致:
https://github.com/mybatis/mybatis-3/issues/705
解决办法(mybatis 3.4.4):使用注解,不重载(改方法名)
两种都试过了,都可以,如果必须保持方法的重载,可以用注解
3、log4j2 生成文件乱码
字符设置,log4j2默认使用系统配置,最好修改为utf-8
<PatternLayout pattern="..." charset="UTF-8"/>
需要用大写UTF
4、maven打包jar,同时打包依赖的jar包
http://blog.csdn.net/xiao__gui/article/details/47341385
第三种方法解决。
收获:
最重要的的收获就是,一个问题调试不出来,可能是方向错了。




评论